
基于MapReduce技术的并行集成分类算法*
2012-02-19 07:27琚春华邹江波魏建良
电信科学 2012年7期
琚春华,邹江波,张 芮,魏建良
(1.浙江工商大学信息学院 杭州310018;2.浙江工商大学现代商贸研究中心 杭州310000)
1 引言
随着信息技术在全球范围内的普及,各行各业已经积累了大规模的行业数据,如电子商务行业中的用户消费数据、浏览商品数据、商品评论数据,生产制造业中的生产数据,科学研究领域的实验数据等,这些数据背后隐藏着许多有价值的信息和知识可被广泛用于各种应用,如市场分析、欺诈检测、顾客保有、产品控制和科学探索等[1]。
设计分类器是模式识别系统的核心,而基分类器的选择和集成策略是集成分类算法的关键[2]。基分类器的选择实质上是分类算法的选择,选择适合挖掘场景的算法是最终分类准确与否的决定因素之一,集成策略的好坏也会影响最终的分类结果,最常用的策略是对各分类器的分类结果进行加权组合,权重反映了各分类器对最终分类结果的影响。
[2]和[3]指出要设计高精度分类器并不容易,但设计出比随机猜测略好的简单分类器却相对容易,因此可以将多个简单分类器进行组合来提升分类精度,并从理论上证明了该假设的正确性。参考文献[4]利用不同分类器模型之间的互补性,动态选择出对目标有较高识别率的分类器组合,使参与集成的分类器数量能够随识别目标的复杂程度而自适应地变化,并根据可信度实现系统的循环集成。参考文献[5]基于Stacking多分类器组合策略,构造了一个两层的叠加式框架结构,融入可能的上下文信息作为情景特征向量输入到各层的4种分类器中进行组合,并在中文组块识别中取得了较好的效果。参考文献[6]针对AdaBoost算法在迭代后期,训练基分类器越来越集中于某一小区域样本上,不能体现出不同区域分类特征的问题,利用待测样本与各分类器的全信息相关度描述基分类器的局部分类性能,提出了基于全信息相关度的动态多分类器融合方法,根据各分类器对待测样本的局部分类性能动态确定分类器组合和权重。上述研究在一定程度上通过改进集成分类的集成策略,提高了小数据集上分类算法的效率。
当面对数据流数据时,目前提出的集成分类算法都无法高效地进行分类,因此,运用并行集成分类方法是解决数据流挖掘问题的一个重要途径。已有并行集成的方法仅在生产制造业研究中有所体现,但在数据挖掘领域还有待研究,参考文献[7]和[8]基于已有并行知识约简算法多任务并行的优点,利用属性集的不可辨识性和MapReduce技术,设计了适合大规模数据集的差别矩阵知识约简算法,并通过实验说明了该约简算法能够高效地处理大量数据。参考文献[9]基于模块化集成学习的思想,设计了与云平台相结合的增量分类方法,虽然没有对云环境下的集成策略进行深入研究,但为本文并行集成处理数据流奠定了基础。
针对已有集成分类算法只适合作用于小规模数据集的缺点,剖析了集成分类器的特性,采用基于聚合方式的集成分类器和云计算的MapReduce技术设计了处理大规模数据的集成分类算法(EMapReduce),并在Amazon计算集群上模拟实验,实验结果表明该算法具有一定的高效性和可行性。
2 相关理论研究
2.1 集成分类理论
集成分类器处理大规模数据的方式主要有3种:基于水平方式的集成分类器、基于垂直方式的集成分类器以及综合两者的基于聚合方式的集成分类器,如图1~3所示。
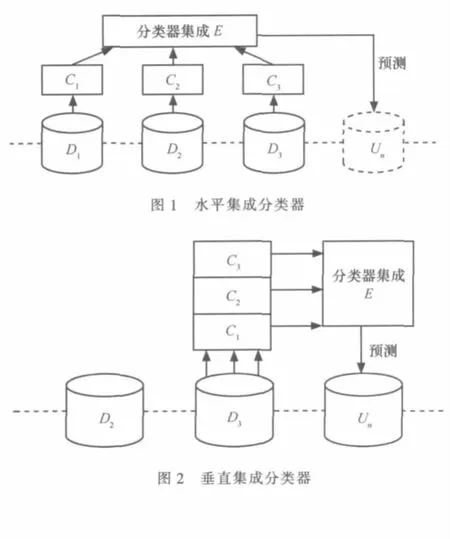
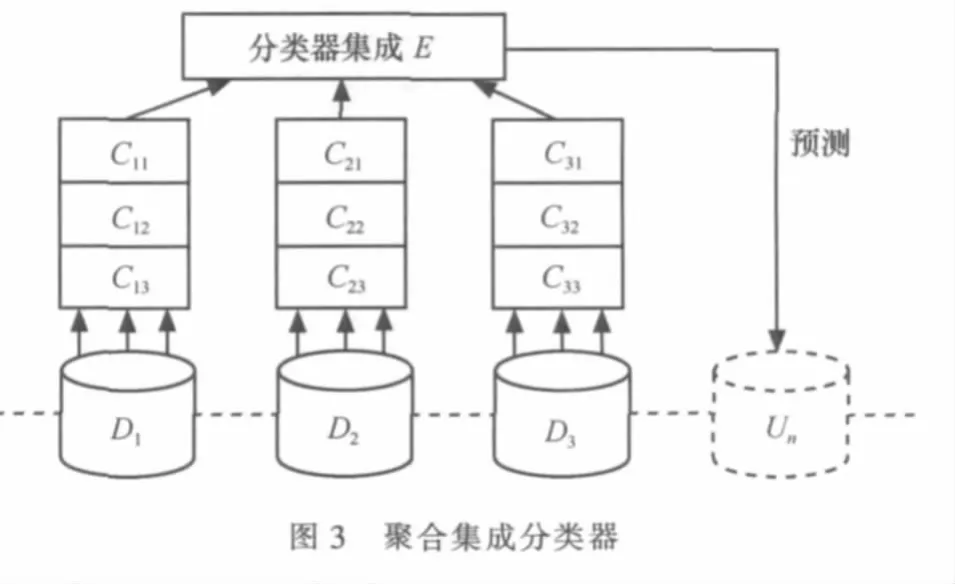
集成分类器增量处理大规模数据集,将连续达到的数据缓存,再对缓存数据等量分块得到数据块{Di}+∞i=1,由于存储空间的局限性,系统内存最多只能连续容纳n个包含一定数量记录的数据块。
基于水平方式的集成分类器通过选择学习算法L对缓存数据块Di学习得到集成分类器中的基分类器fi,即fi=L(Di),i=1,2,…,n。再对D1,D2,…,Dn已标记类别数据块中学习的基分类器集成,达到对Dn+1数据块分类的目的。基分类器fi对Dn+1中的每条记录预测分类结果,最后采用类似专家投票的方式得出分类结果。基于水平方式的集成分类器可用谓词逻辑表示,如式(1),时间复杂度为O(nlg(n))。

基于垂直方式的集成分类器通过选择学习算法Lj(j=1,2,…,m)随机选择缓存中的某一数据块Dn学习得到集成分类器中的基分类器fj,即fj=Lj(Dn)。如图2所示,该方式与水平集成分类器不同的是,它随机抽取一个数据块并采用不同的挖掘算法进行学习得到集成分类器。不同算法的基分类器fj对Dn+1中的每条记录分别预测分类结果,最后采用类似专家投票的方式得出分类结果。基于垂直方式的集成分类器可用谓词逻辑表示,如式(2),时间复杂度为O(mnlg(n))。

综合上述两者的基于聚合方式的集成分类器[10],如图3所示,通过m种学习算法Li(i=1,2,…,m)对缓存中的数据块Dj(j=1,2,…,n)学习得到集成分类器中的基分类器fij,即fij=Li(Dj),其中i表示算法集中的第i种算法,j表示缓存中的第j个数据块。基于聚合方式的集成分类器可用谓词逻辑表示,如式(3),时间复杂度为O(mnlg(n))。学习的基分类器构成了一个m×n阶的分类器矩阵(CM)。
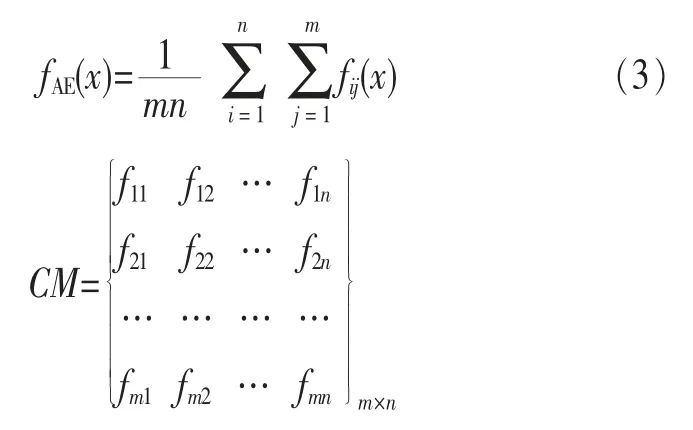
聚合集成分类器克服了水平集成分类器仅用一种算法学习而导致的过度拟合问题以及垂直集成分类器仅随机选择数据学习造成的欠学习问题,其处理数据流的能力良好,如降低了噪声数据对分类模型的干扰以及目标分类模型随时间变化产生的概念漂移。
理论上基于聚合方式的集成分类器在大规模数据时具有良好的性质,其时间复杂度与基于垂直方式的集成分类器相同,在实际应用中如果每个数据块Dj都用i种算法学习集成(i=1,2,…,m,j=1,2,…,n),由于计算机内存资源的限制,当m、n取值较小时,一台计算机需要运行较长时间进行分类学习,但当选择的算法较多,数据块划分较细时,仅用一台机器运算聚合集成分类算法显然是不合适的。
2.2 云计算技术
为了应对类似上述大规模数据计算的难题,MapReduce编程模型应运而生。该模型由Google公司提出,其良好的易用性和扩展性,得到了IT界和学术界的广泛支持。Hadoop是MapReduce模型的开源实现,并且已经在Yahoo、Facebook、IBM、百度、中国移动等多家企业中成功应用。
MapReduce以函数方式提供了Map和Reduce两种方式进行分布式计算。Map相对独立且并行运行,对存储系统中的文件按行处理,并产生键值(key,value)对。Reduce以Map的输出作为输入,相同key的记录汇聚到同个Reduce,所有Reduce任务并归处理输出组成最终结果,其流程如图4所示。

3 构建基于云计算的并行集成分类器
3.1 适用于MapReduce编程模式的并行集成分类模型
MapReduce编程模式弥补了集成分类器由于多基分类器在一台计算机上并行学习造成内存资源不足的问题。本文提出的并行集成分类算法基于聚合方式的集成分类器,利用MapReduce模式实现基分类器并行计算,EMapReduce算法结构如图5所示。
基于Hadoop将连续到达的数据{Di}切块存储到计算集群的分布式文件系统(HDFS)中,Hadoop负责管理切块数据{di},其key值为所属数据块Di。计算集群中的计算机Mi(i为计算集群数量)采用m种算法对本地存储的相应切块数据并行学习得到基分类器Ci,对同机器基分类器的分类结果Reduce(key值为机器号,value值为分类结果)得到该机器的分类结果,最后将所有集群的分类结果“投票”获得集成分类器。

并行集成分类模型将数据切块处理,降低了噪声数据对学习的干扰,通过并行学习提高了计算效率,选择多种学习算法,防止了分类结果过度拟合,采用集成的方法削弱了概念漂移对模型的影响。
3.2 并行集成分类器算法
在云计算环境下并行集成算法中,Map函数主要完成切块数据的基分类器学习,而Reduce函数主要计算同机器中不同算法基分类器的分类结果。下面给出处理大规模数据的并行集成分类算法EMapReduce,分别设计1个Map函数(算法1),用于并行学习生成基分类器,2个Reduce函数(算法2,算法3),用于计算分类结果。
EMapReduce算法1主要用于并行学习产生基分类器,如下所示。
Input:The chunk id(Key),the labeled training instance(Value)
Initialize threshold use to create base classifier;
Vtrain←training instances in value from chunk i which have stored in HDFS;
Vtest←all test instances read from HDFS;
N←Number of test instances in Vtest;
Ci←algorism(Vtrain);//create a base classifier use algorism i
For j=1 to N
Accurate←Ci(Vtest(j));//verify the base classifier accurate through test data
End for
If base classifier accurate>accurate threshold
Save this classifier in the map which use to predict prediction data class label
EMapReduce算法2主要用于并行学习产生的基分类器对预测样本进行分类,如下所示。
Input:The chunk which is except to predict class label,the key is chunk instance id,the unlabeled data is value
Output:
Vpredict←prediction data in HDFS;
N←Number of test instances in Vpredict;
For j=1 to N
List label←Ci(Vpredict j));//use trained base classifier to predict test instances class and return the list of predict class label
End for
key’←this base classifier id;
value’←List label;
EMapReduce算法3主要用于对预测分类进行加权统计得出最终分类结果,如下所示。
Input:the list of predict class label from every node base classifier
Output:final classification of this unlabeled chunk data
For each label in the list
If predict label is Li;
Li++;
End for
Final class label of this chunk data←max{Li}(i=1,2…k);
Return Final class label;
4 实验验证
本文没有自行搭建实验所需的云计算平台,因为关于Hadoop节点、网络的配置比较繁琐,并且自行搭建的计算环境性相对不稳定,所以本文选择在Amazon第三方云平台上进行模拟实验,因为它免除了搭建平台的复杂操作,使研究重点放在MapReduce逻辑处理上,图6为Amazon云计算平台主界面。
本实验所有的数据均来自UCI官网,主要选择了两大数据集,第一个是Amazon Commerce Reviews Set数据集,数据源来自客户对亚马逊电子商务网站商品的评论,数据实例由50名活跃用户(数据集中用户拥有唯一的姓名)对商品的评论构成,选择了每个用户的30条评论,共1 500条实例,本实验选择1 000条实例作为训练数据,500条数据作为测试数据,虽然数据量较少,但是该数据集具有高维性,共10 000个属性,具有如此高维度的原因是数据集将不同的单词作为一个维度,如果用户的评论中包含该单词,则实例中用该单词出现的次数表示,如果该单词没有出现则用0表示,最后实例类别为50名评论用户的唯一姓名。第2个是Adult数据集,数据源来自美国人口普查数据,共计48 842条,其中包含训练数据32 561条,测试数据16 281条,根据实例的性别、年龄、受教育水平、平均每周工作时间、工作性质等14个属性,对实例的实际年薪是否达到50 000美元进行分类。表1是对实验数据信息的汇总。
通过Amazon S3功能添加并行计算所需的实验数据,如图7所示,其中包含2个训练数据文件、2个测试数据文件以及实现MapReduce接口的并行集成分类器算法jar包。


表1 实验数据信息汇总

通过Amazon Elastic MapReduce功能达到配置程序的目的。用Create Job Flow配置数据源路径、主程序路径、结果输出路径,计算集群个数,当Job Flow建立完成以后,如图8所示,有1台Master主机和3台Core主机,共4台主机构成计算集群。
图9为Amazon集群上对Adult Data Set数据集完成计算的截图,可以看到在云平台上仅用10 min便完成了对数据集分类的任务。
当MapReduce任务完成后云计算主机自动停止并在输出目录中输出了此次计算的日志数据,如图10所示。


图11为计算完成后Master主机的资源使用情况,包括磁盘读写数、网络输入输出数、CPU使用百分比等。通过该图可以观测云计算的资源使用情况。
最后在Amazon S3中查看输出日志,选取混淆矩阵统计并行分类算法的分类准确率,混合矩阵的定义见表2,分类的平均准确率可由下式计算得出:


表2 混合矩阵
Amazon上并行集成分类算法对Amazon Commerce Reviews Set、Adult Data Set测试数据正负实例的分类结果,见表3和表4。

表3 EMapReduce在Amazon Commerce Reviews Set数据上分类准确率

表4 EMapReduce在Adult Data Set数据上分类准确率
本文将Amazon Commerce Reviews Set、Adult Data Set数据集在weka上进行实验,但由于数据维度较高,实验的运行时间较长,并没有得到期望的实验结果,相比较而言在云平台上对大规模数据进行分类计算具有一定的可行性。
5 结束语
经典的集成分类算法在处理小数据集时,有较高的分类准确性,但面对大规模数据集时,会因为基分类器的不断学习及其在内存中的数目不断增多而导致机器分类效率降低,这显然不适合处理如今的海量数据。针对已有集成分类算法只适合作用于小规模数据集的缺点,剖析了集成分类器的特性,采用基于聚合方式的集成分类器和云计算的MapReduce技术设计了集成分类算法(EMapReduce),达到并行处理大规模数据的目的。并在Amazon计算集群上模拟实验,实验结果表明该算法具有一定高效性和可行性。
参考文献
1 韩家炜,坎伯.数据挖掘:概念与技术.北京:机械工业出版社,2001
2 付忠良.分类器线性组合的有效性和最佳组合问题的研究.计算机研究与发展,2009,46(7):1 206~l 216
3 Valiant I G.A theory of the learnable.Communications of the ACM,1984,27(11):1 134~1 142
4 郝红卫,王志彬,殷绪成.分类器的动态选择与循环集成方法.自动化学报,2011,37(11):1 291~1 295
5 李珩,朱靖波,姚天顺.基于Stacking算法的组合分类器及其应用于中文组块分析.计算机研究与发展,2005,42(5):844~848
6 张健沛,程丽丽,杨静.基于全信息相关度的动态多分类器融合.计算机科学,2008,35(3):188~190
7 钱进,苗夺谦,张泽华.云计算环境下知识约简算法.计算机学报,2011,34(12):2 333~2 343
8 钱进,苗夺谦,张泽华.云计算环境下差别矩阵知识约简算法研究.计算机学报,2011,38(8):193~196
9 李曼.云计算平台上的增量分类研究.微型机与应用,2011,30(18):65~68
10 Zhang Peng,Zhu Xingquan,Shi Yong.Robust ensemble learning for mining noisy data streams.Decision Support Systems,2011(50):469~479
11 Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters.Osdi,2004(34):137~150
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
