
校园网Web搜索引擎的设计与实现
2011-12-27 09:18夏敏捷
中原工学院学报 2011年5期
夏敏捷,徐 飞,夏 冰
(中原工学院 ,郑州450007)
校园网Web搜索引擎的设计与实现
夏敏捷,徐 飞,夏 冰
(中原工学院 ,郑州450007)
在研究Web搜索引擎发展的基础上,结合对校园网搜索引擎具体需求的分析,介绍了校园网搜索引擎系统整个框架的设计及关键技术.应用该搜索系统可以有效提高站内搜索效率.
搜索引擎;网络爬虫;Lucene
随着校园网建设的迅速发展,校园网内的信息内容正在以惊人的速度增加着.如何更全面、准确地获取最新、最有效的信息,已经成为我们把握机遇、迎接挑战和获取成功的重要条件.目前虽然已经有了像Google、百度这样优秀的通用搜索引擎,但是它们并不能适用于所有的情况和需要.对学术搜索来说,一个公平的排序结果是非常重要的.另外,由于互联网上信息量巨大,远远超出哪怕是最大的一个搜索引擎可以完全搜集的能力范围.因此,本着整合校园网资源的目的,为方便广大师生对校园网信息的获取和使用,本文设计并实现了一个灵活、可配置、具有良好可扩展性的校园网搜索引擎.
1 搜索引擎的发展
在国内,很多基于主题领域的小型搜索引擎得到很好的发展.例如,一些音乐搜索引擎以及医药方面的搜索引擎都有很好的应用;越来越多的学校、企业及比较大型的网站如BBS都开始建立了自己的搜索引擎.在国外,比较著名的有美国教育资源信息搜索的Ask-ERIC,实现医药文献搜索的Highwire等.Google公司在2007年决定向小型网站提供专门的搜索服务.这些都表明,小型专用的搜索引擎将在人们获取Web信息中发挥更重要的作用[1].
在小型搜索引擎快速发展的同时,越来越多的人致力于研究和开发这些小型搜索引擎技术,Lucene和Nutch是其中的代表成果.Lucene是一个高性能、纯Java的全文检索引擎,完全免费、开源;Lucene几乎适合于任何需要全文检索的应用,尤其是跨平台的应用.Lucene为Nutch提供了文本索引和查询服务的API,而Nutch在Lucene的基础上实现了网页收集与搜索[2].
小型搜索引擎与通用搜索引擎相比有很多优点,然而,由于它本身的信息量小,它不可能取代通用搜索引擎.但是,它是对通用搜索引擎的很好补充.随着Web上信息的进一步扩大,小型搜索引擎也将会进一步发展,其中已经引起人们关注的垂直搜索引擎将在未来的信息搜索中发挥更大的作用.
2 校园网搜索引擎系统设计
本文旨在使用Lucene建立一个适合校园网使用的Web搜索引擎系统,实现对校园网上常用信息的检索,能在较短时间内更新页面信息,实现有效准确的中文分词功能.本系统使用网络爬虫对校园网的网络资源进行采集和周期性更新,利用Lucene对采集的信息资源进行索引和检索,从而开发实现一个校园网Web搜索引擎系统.
系统主要由4个模块组成:信息采集模块、信息更新模块、索引模块、搜索模块.其中索引模块又分为3个部分:解析器(Parser)、分析器(Analyzer)和索引器(Indexer).
信息采集模块主要是利用网络爬虫实现对校园网网页信息的抓取.
信息更新模块负责对已有Web信息资源进行周期性更新,以保证索引信息与 Web网站信息的一致性.
索引模块负责对存储到数据库的网页文本内容进行索引.
搜索模块负责从索引库中搜索包含查询关键词的文档内容,并负责用户从界面输入查询关键词以及搜索结果信息的返回.校园网搜索引擎系统设计如图1所示.
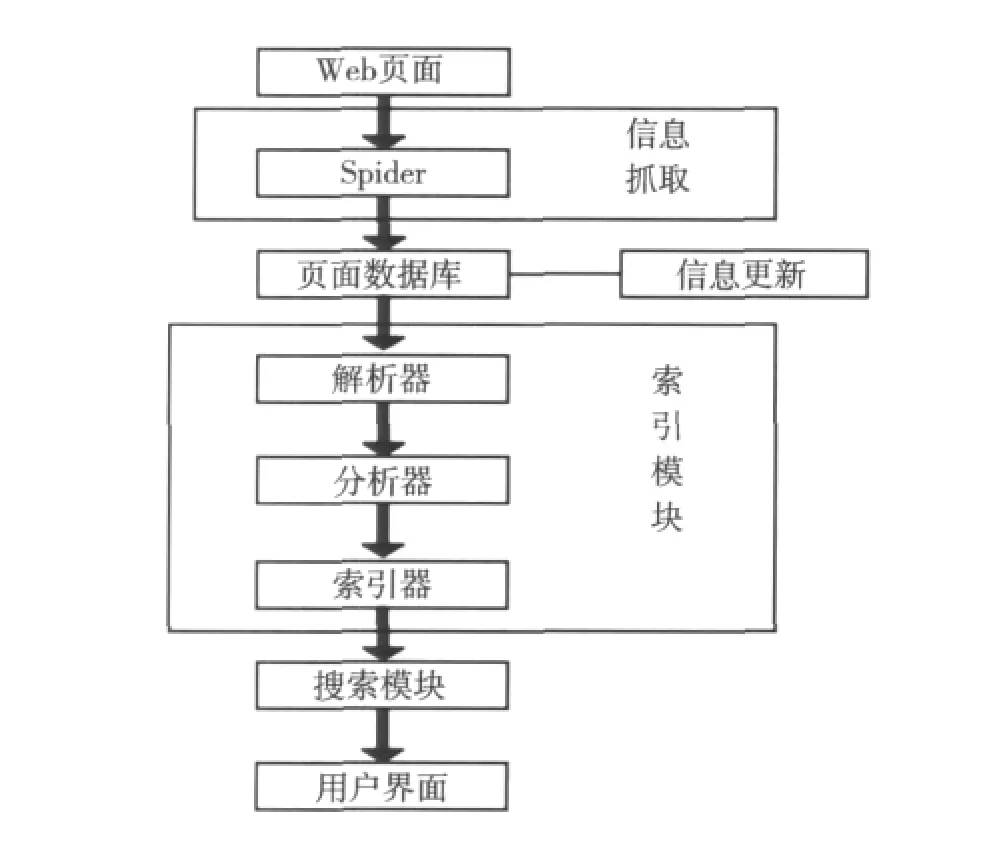
图1 系统设计图
3 校园网搜索引擎模块设计
3.1 信息采集模块设计
网络爬虫对整个校园网网站的网页进行抓取,生成新的页面集合并存储到MySQL数据库中.在抓取页面的同时,获取页面的文本内容.由于Lucene只能对文本文件进行索引,要想将网页内容加入到索引库中,必须使用网络爬虫从校园网上抓取网页URL、网页文本内容、网页标题,并保存在MySQL数据库中,然后从MySQL数据库中将网页文本内容读取出来以进行索引.
在使用网络爬虫抓取校园网的URL时,会发现重复URL抓取的现象,一个网页会在多个网页中含有对它的连接.为了避免在抓取网页中出现死循环现象,我们在设计数据、存储URL时使用唯一存储,只存储一次URL,如果有重复的URL出现,就不再往下抓取此网页以及以下目录的链接.页面去重放在抓取之前,可以减少重复的索引,从而提高索引效率.
3.2 页面更新模块设计
在进行搜索时,人们总是希望能准确获取最新的信息.而每次搜索结果里面总是有死链接或者信息明显过时的页面存在,也有一些新出现的页面不能被搜索到.页面更新的功能就是尽量保证本地页面内容和实际页面内容的一致性.做法就是在信息提取完成后的一段时间(例如3天)后,搜索引擎调用网络爬虫对整个校园网网站的网页重新抓取,生成新的页面集合来取代旧的页面集合.
3.3 索引模块设计
索引模块运行过程分为3个阶段:文本提取、分析文本和建立索引,如图2所示.

图2 索引模块流程
(1)文本提取.文本提取从MySQL数据库中将网页文本内容、网页URL、网页标题等读取出来并转换成Lucene的Field.提取网页文本之后,就要对文本内容进行分析了.
(2)文本分析.文本分析在Lucene中是指将Field文本转换成最基本的索引单元项Term.对于不同的语言,分析器要完成的功能是不同的.譬如对英文来说,要将字母转换成小写、除去符号等.在校园网 Web搜索引擎中,主要针对的是中文搜索,分析器需要实现的主要是中文分词.在英文中,单词之间是以空格作为自然分界符的.而中文只是字、句和段可以通过明显的分界符来简单划分,唯独词没有一个形式上的分界符.虽然英文也同样存在短语之间的划分问题,但是在词这一层上,中文比英文要复杂的多.
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程.分词是网页分析索引的基础,分词的准确性对搜索引擎来说十分重要.但是如果分词速度太慢,即使再准确,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理很多的网页,如果分词消耗的时间过长,会严重影响搜索引擎内容更新的速度.因此,搜索引擎对于分词的准确率和速率都提出了很高的要求[3-4].
使用Lucene时,选择一个合适的分析器是非常关键的.对分析器的选择没有唯一的标准.本系统采用的分词器是极易分词器mmseg4j.从网站上下载极易分词包,它包含词库和分词jar包.使用时在Tomcat Web服务器的安装目录下找到Webapps下本系统所在文件夹,在其下新建一个classes文件夹,用来存放词典和字库,将分词包中的data和dic文件复制到classes文件中,接着在 WEB-INF下的lib中添加jeanalysis-qw-1.5.3.jar文件.
最后用文本编辑器打开schema.xml文件,在<types></types>中加入新的字段类型--text_chinese,并在分词属性中加入类文件的名称"jeasy.analysis.MMAnalyzer",表示在创建索引和查询索引时都使用的是极易中文分词器.
schema.xml文件如下:
<fieldType name="text_chinese"class="solr.TextField">
<analyzer class="jeasy.analysis.MMAnalyzer"/>
</fieldType>
(3)索引的建立.索引就是为了快速搜索大量的文本.先将文件转化成一个快速搜索的数据结构,从而不需要进行缓慢的顺序扫描,这个转化过程称为建立索引.
Lucene采用的是倒排索引结构[5],将输入字符流存储在一个反索引的数据结构中.这个数据结构在允许关键词查询的同时,有效地利用了磁盘空间.这个结构使用从输入中提取的单词而不是处理的文档作为查询的入口.也就是说,这个结构为提供快速查询做了优化,即形成关键词到文档号的映射.仅仅知道关键词在哪些文档中还不够,还需要知道关键词在文档中出现的次数和出现的位置.通常有2种位置:字符位置和关键词位置.字符位置是记录关键词在文档中是第几个字符(优点是关键词高亮显示时定位快);关键词位置是记录关键词在文档中是第几个关键词(优点是节约索引空间、词组查询快).Lucene同时使用了这2种位置.
以上就是Lucene索引结构中最核心的部分.关键词是按照字符顺序排列的,Lucene可以用二元搜索算法快速定位关键词.
为了减小索引文件的大小,Lucene对索引还使用了压缩技术.首先,对文档中的关键词进行压缩,将关键词压缩为前缀长度加后缀;其次,大量用到的是对数字的压缩,数字只保存与上一个值的差值,这样也减小数字的长度,进而减少保存该数字需要的字节数.在这种索引结构下,文档通常非常小,因而,整个过程的时间是毫秒级的.
3.4 搜索模块的设计
对需要的网页文件索引完毕以后,就可以对用户提供搜索服务了.搜索模块负责接受用户提交的检索请求,并根据请求访问相应的Lucene索引数据库,最后将结果集按照相关度排序后返回给用户.搜索的处理流程如图3所示.

图3 搜索流程图
用户通过用户界面提出搜索请求,Lucene索引器接受用户请求,查找本地索引库,找到与输入相关的内容,按照某种算法排序后将相关结果信息返回给用户.这里主要利用Servlet技术实现,用户通过POST方法从客户端向服务器端提交查询条件,服务器端通过Tomcat的Servlet容器接收并分析提交的参数,再调用系统的搜索模块进行搜索操作.最后把搜索的结果以HTTP消息包的形式发送给客户端,从而完成一次搜索操作.搜索结果页面如图4所示.
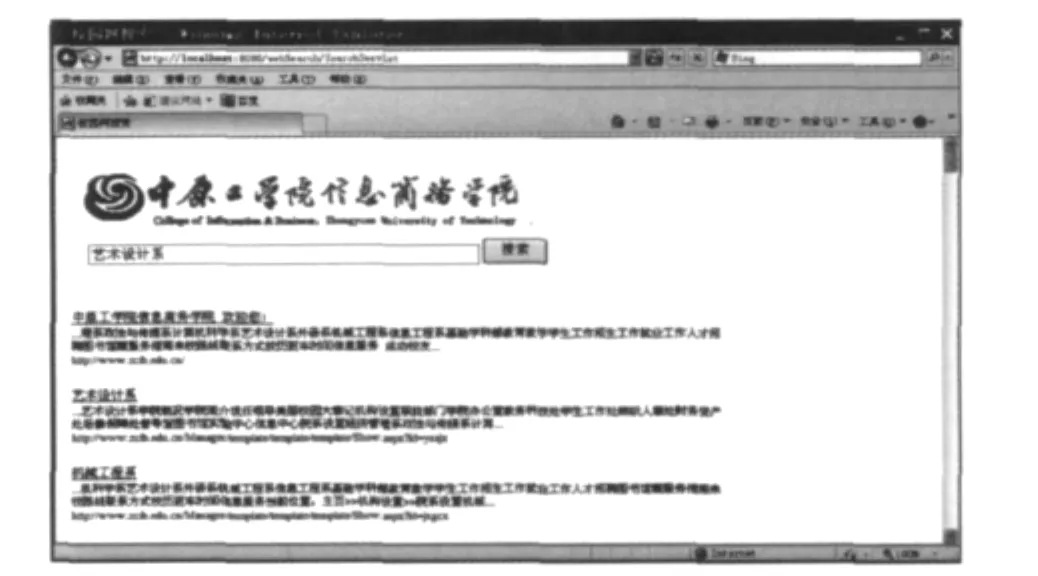
图4 搜索结果页面
4 结 语
本校园网Web搜索引擎在配置Tomcat服务器后即可投入使用,但要成为一个好的和有用的校园网搜索引擎和教育信息搜索引擎,还面临着许多挑战.首先,为进一步提高检索准确性,针对中文的特点,需解决人名、地名、专业词汇、新生词汇的识别问题,实现一个自动更新的词典,提高中文分词的准确度;其次需要为校园网用户提供个性化检索、个性化排序等功能,满足用户多样的信息需求;其他如网页重要性评估、结果得分算法、用户行为分析等问题.这些问题有待进一步研究和改进,从而提高校园网Web搜索用户获取知识与信息的效率.
[1] 孟晓明.浅谈搜索引擎及其发展趋势[J].计算机应用,2004(8):34-36.
[2] 冯斌.基于Lucene小型搜索引擎的研究与实现[D].武汉:武汉理工大学,2008.
[3] 陈康,滕育平.中文信息检索引擎的分词与检索技术[J].计算机应用,2004(7):30-33.
[4] 蔡勇智.基于最大匹配分词算法的中文词组粗分模型[J].计算机应用,2006(9):12-15.
[5] 胡俊,李星.校园网信息资源搜索引擎的研究与实现[J].计算机工程与设计,2006(7):22-26.
The Design and Implementation of Campus Web Search Engine
XIA Min-jie,XU Fei,XIA Bing
(Zhongyuan University of Technology,Zhengzhou 450007,China)
This paper studies the development of Web search engine.Based on the combination of the specific needs of the campus network search engines,the framework design of campus network search engine system and key technologies are introduced.Application of the search system can effectively improve the efficiency of the web site search.
search engine;Web crawler;Lucene
TP391
A
10.3969/j.issn.1671-6906.2011.05.007
1671-6906(2011)05-0027-04
2011-07-30
河南省科技攻关计划项目(092102310038;092102210029)
夏敏捷(1974-),男,河南三门峡人,副教授.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
疯狂英语·新阅版(2020年11期)2020-12-21
甘肃教育(2020年18期)2020-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2019年10期)2019-06-17
中央民族大学学报(自然科学版)(2018年2期)2018-11-09
电子制作(2017年8期)2017-06-05
中国卫生(2015年12期)2015-11-10
科学导报·学术论坛(2013年5期)2013-06-26
