
遗传神经网络在煤质测井评价中的应用
2011-12-26 01:00陈钢花董维武
测井技术 2011年2期
陈钢花,董维武
(中国石油大学地球资源与信息学院,山东青岛266555)
遗传神经网络在煤质测井评价中的应用
陈钢花,董维武
(中国石油大学地球资源与信息学院,山东青岛266555)
煤层气储层具有很强的非均质性和各向异性,使得测井资料解释结果具有多解性、模糊性和不确定性。提出了将遗传算法和神经网络相结合的方法,利用遗传算法优化神经网络的连接权值及阈值,从而提高网络训练精度和煤层气储层评价精度。该方法避免了标准BP算法易陷入局部最小和遗传算法局部搜索能力较差的缺点,提高了运算速度。介绍了利用遗传算法优化网络连接权值及阈值的步骤和煤质参数预测步骤。通过选取学习样本、确定网络结构、归一化处理数据,建立了基于 GA-BP神经网络的煤层气储层煤质测井评价模型。对26个样本数据的分析对比表明,该算法具有较高的预测精度和较快的运算速度。10多口井的实际应用表明,GA-BP神经网络模型预测结果与煤心测试数据匹配很好,且与体积模型计算结果具有良好的一致性。
测井解释;煤层气;煤质分析;地球物理测井;BP神经网络;遗传算法
0 引 言
煤层气储层具有很强的非均质性和各向异性,造成储层地质特征和测井响应之间的关系复杂,表现出明显的非线性特征,使得测井资料解释结果具有多解性、模糊性和不确定性[1]。煤层煤质参数的计算是煤层气储层评价的重要方面,是影响煤层物性和含气性的重要因素。利用统计模型法和体积模型法评价煤质参数只能用“显式”的函数表达式表达测井参数与煤层参数间关系,是对二者之间复杂关系的简化,且较难合理选择煤质组分测井响应参数,所以有时会产生较大误差。
BP神经网络是目前应用最为广泛的神经网络之一[2]。由于BP算法是基于梯度最大下降的搜索方法,其缺陷是易陷入局部极小点,从而影响网络训练精度。遗传算法是模仿自然界生物进化思想而得出的自适应启发全局搜索算法,它具有很强的全局搜索能力,但其不足之处在于,当搜索到最优解附近时,无法精确地确定最优解的位置,即局部搜索能力较差。因此,考虑将遗传算法和BP神经网络结合,使二者取长补短,提高网络训练精度。利用GA-BP神经网络评价煤层气储层煤质参数,具有综合利用多种测井参数,客观反映输入参数与煤层参数之间复杂规律和无需选择测井解释参数等优点。
1 神经网络与遗传算法
1.1 BP神经网络
标准BP算法是基于梯度下降法的学习算法,学习过程是通过调整权值和阈值,使输出期望值和神经网络实际输出值的均方误差趋于最小而实现。在实际应用中存在易陷入误差函数的局部最优、收敛速度慢、网络的学习记忆具有不稳定性等不足。针对这些缺点,目前已有不少人对此提出了改进方案,如修正学习率、增加动量项、引入陡度因子及改进神经元激励函数等[3]。
1.2 用遗传算法优化BP神经网络权值及阈值
遗传算法是一种全局优化搜索算法,可以有效克服BP神经网络易陷入局部最优的不足。利用遗传算法优化BP网络权值及阈值的基本思想是利用遗传算法全局搜索能力强的特点,先用遗传算法对神经网络的初始权值进行粗略的全局优化,并在解空间中定位出较好的搜索空间;然后利用BP算法在这些小的解空间局部搜索,最终使其快速搜索到全局最优值[5]。
遗传算法优化网络权值及阈值的一般步骤:
(1)确定BP网络结构及网络训练样本;
(2)对神经网络权值及阈值进行编码,初始化遗传算法控制参数,产生含 P个个体的初始种群(权值);
(3)确定适应度函数,一般以误差函数的倒数作为适应度函数,误差越小,适应度越大;
(4)输入样本训练集,经BP前向传播得到网络实际输出;
(5)计算每个个体的适应度,根据适应度的大小对种群中的个体进行优选操作;
(6)对优选出来的个体进行交叉、变异等遗传操作,生成新一代群体;
(7)重复步骤(4)~(6),一代一代繁殖种群,直到满足终止条件为止,得到经遗传算法优化的网络权值及阈值;
(8)将上述经遗传算法全局优化的权值及阈值,作为BP网络的初始权值及阈值,利用BP算法局部搜索能力强的特点进一步优化网络权值,训练网络,直至满足终止条件为止。
2 GA-BP神经网络在煤质测井评价中的应用
2.1 煤质参数预测的一般步骤
(1)煤心实验数据及测井数据的预处理包括煤心数据和测井数据的深度归位,测井数据的标准化、环境校正和归一化处理等;
(2)选取网络训练样本集;
(3)构建 GA-BP网络,用学习样本集训练网络,直到满足精度要求为止,保存网络,建立煤质参数预测网络模型;
(4)应用上述网络预测模型,预测未知煤层层段的煤质参数。
2.2 学习样本的选取
用神经网络评价煤质参数,就是寻求测井信息与煤质参数之间的某种非线性映射或拟合,通过给定的训练样本集进行学习得到解释模型。可见,网络的训练样本集的选取至关重要,它直接影响到网络训练的效果和预测模型的建立。学习样本选取应遵循的原则:①剔除个别明显异常的数据点;②适当减少相同特征点数;③适当补充特征明显的典型样点;④适当控制训练样本总量;⑤尽量避免选择在薄层和岩层界面处的数据点。
2.3 网络结构的确定
根据神经网络的连续函数映射定理,具有3层(1个输入层、1个隐含层和1个输出层)的网络结构,即可实现任意连续函数从输入空间向输出空间的映射。本文采用3层 GA-BP神经网络进行煤质参数的测井评价,输入层神经元数等于输入测井参数个数,输出层神经元个数为4个(即4种工业组分含量),隐含层神经元个数较难确定,无统一规律,一般通过反复试验确定。确定隐含层神经元数的经验公式为
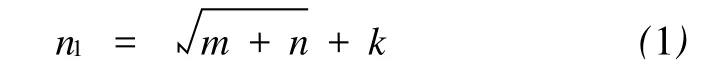
式中,n1为隐含层神经元数;m、n分别为输入层和
输出层神经元数;k为0~10之间的常数。
2.4 数据的归一化处理
由于各种测井数据量纲不一致,进入神经网络之前,无论是学习训练样本还是预测数据,都需先进行归一化处理,使其数值在一定范围之内,如[0,1]之间。对于具有近似线性特征的输入参数,如密度、中子、声波和自然伽马等,可以采用如下线性归一化公式
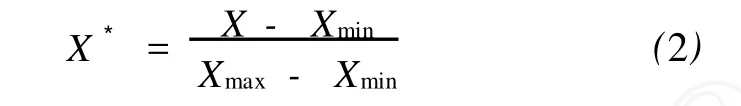
式中,X、X*分别是归一化前后测井值;Xmax、Xmin分别为该段测井曲线的极大值、极小值。
对于具有非线性对数特征的输入参数,如电阻率等,可以采用式(3)对数归一化公式
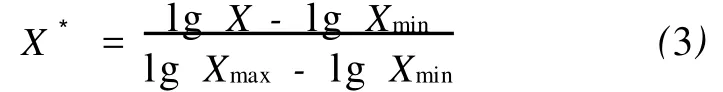
在归一化过程中,测井曲线的极大值、极小值的选取至关重要,不同的取值可造成归一化结果的差异,进而影响预测结果。一种较好的选取方法是在需归一化的层段内,将占据数据点总点数α%的较大值、较小值,按 Hodges-Lehmann统计均值原则,自动选取该层段极大、极小值。其中,α一般取1~5。
3 实例分析
选取反映煤质参数敏感的体积密度(D EN)、声波时差(AC)、补偿中子(CNL)和自然伽马(GR)等4种测井参数作为网络的输入,煤心实验室工业分析参数(固定碳、灰分、挥发分和水分)作为网络的输出,构建一个输入层神经元数为4、隐含层神经元数为10、输出层神经元数为4的3层 GA-BP神经网络,预测煤质参数。
将26个样本数据分为训练样本集(20个样本数据)和测试样本集(6个样本数据)2组。前者用于训练神经网络,后者用于测试网络的训练效果及网络的泛化能力。表1列出了经归一化处理后的全部样本数据。
GA-BP神经网络的主要参数设计为:染色体编码采用实数编码,适应度函数为误差平方和的倒数,种群规模为50,遗传代数为100,网络最大训练次数为100,训练误差精度为1×10-5。
用训练样本训练网络,经过100代遗传操作,得到遗传算法优化的BP网络初始权值和阈值,适应度函数值为0.45(见图1)。再用改进的BP算法训练网络,经35次迭代,网络总误差达到精度要求(1 ×10-5),网络训练停止(见图2)。
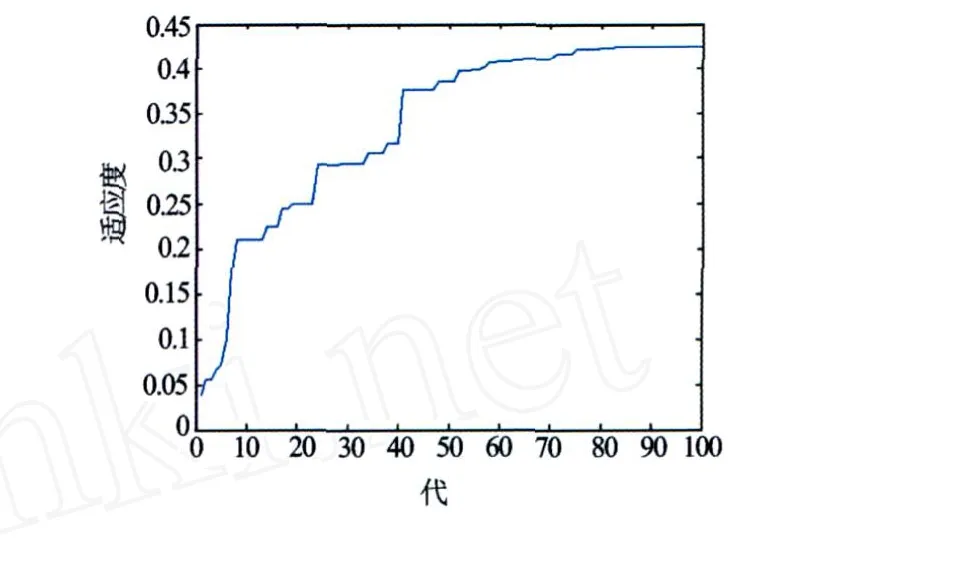
图1 GA-BP网络适应度变化曲线

图2 GA-BP网络总误差传播曲线
为了测试网络预测煤质参数的效果,分别用训练样本的测试样本作为训练好的网络的输入,网络输出结果及其与期望输出的对比见表2。从表2可见,训练样本输出结果的绝对误差都很低,说明网络的训练精度较高;训练样本输出结果的绝对误差较前者有所增加,固定碳含量误差最大,但也只有0.020 5,说明网络具有很好的泛化能力,对训练样本之外的数据也可以给出较准确的预测结果。
利用该方法对研究区10多口井煤层煤质进行了评价,取得了较好的效果。图3为研究区B井某煤层煤质评价成果图。可见神经网络模型预测结果与煤心测试数据能够很好地匹配(见表3),且与体积模型计算结果具有很好的一致性,说明利用 GABP网络预测煤质参数是可行的,且具有较高的精度。
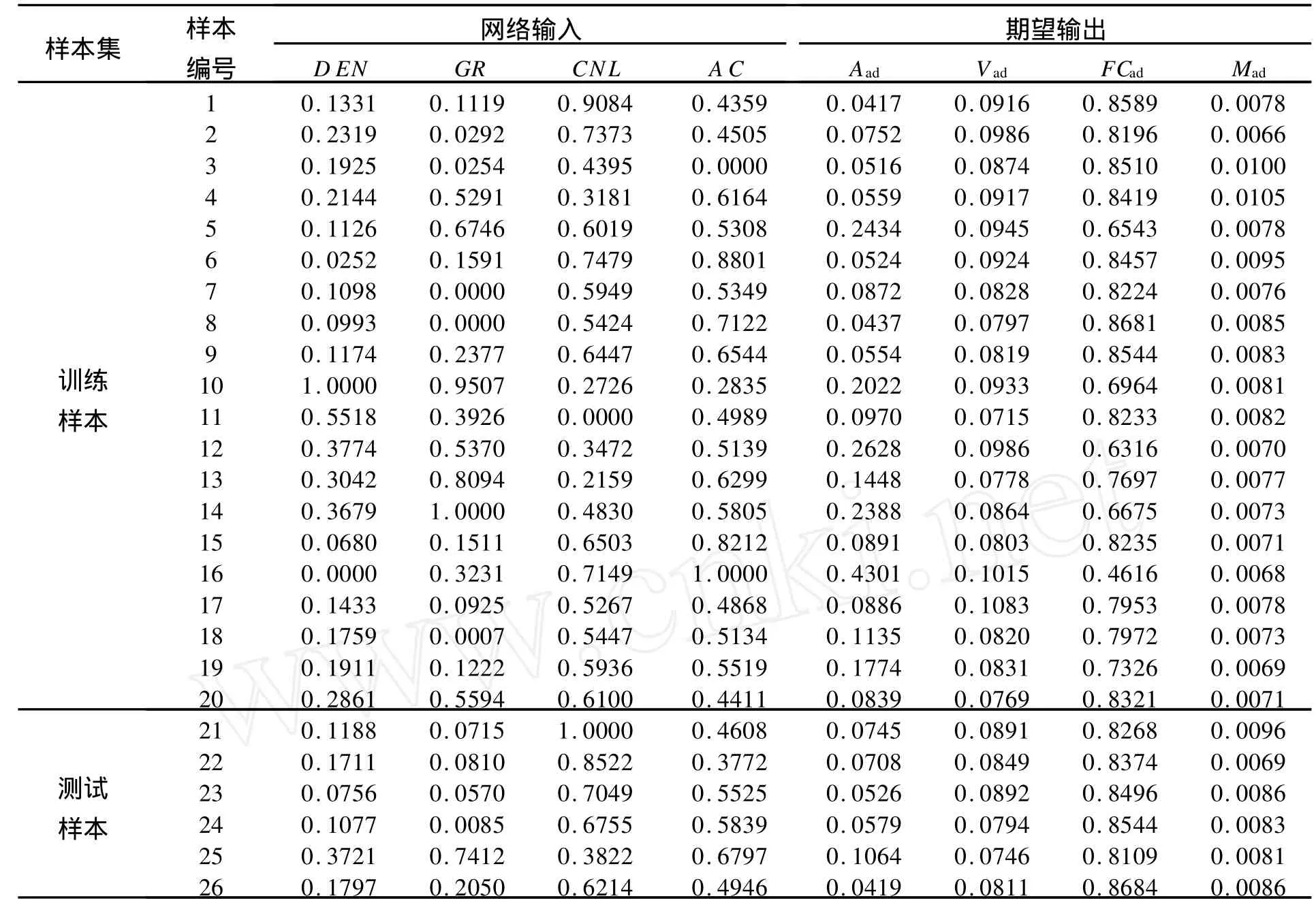
表1 GA-BP网络样本数据(已归一化)
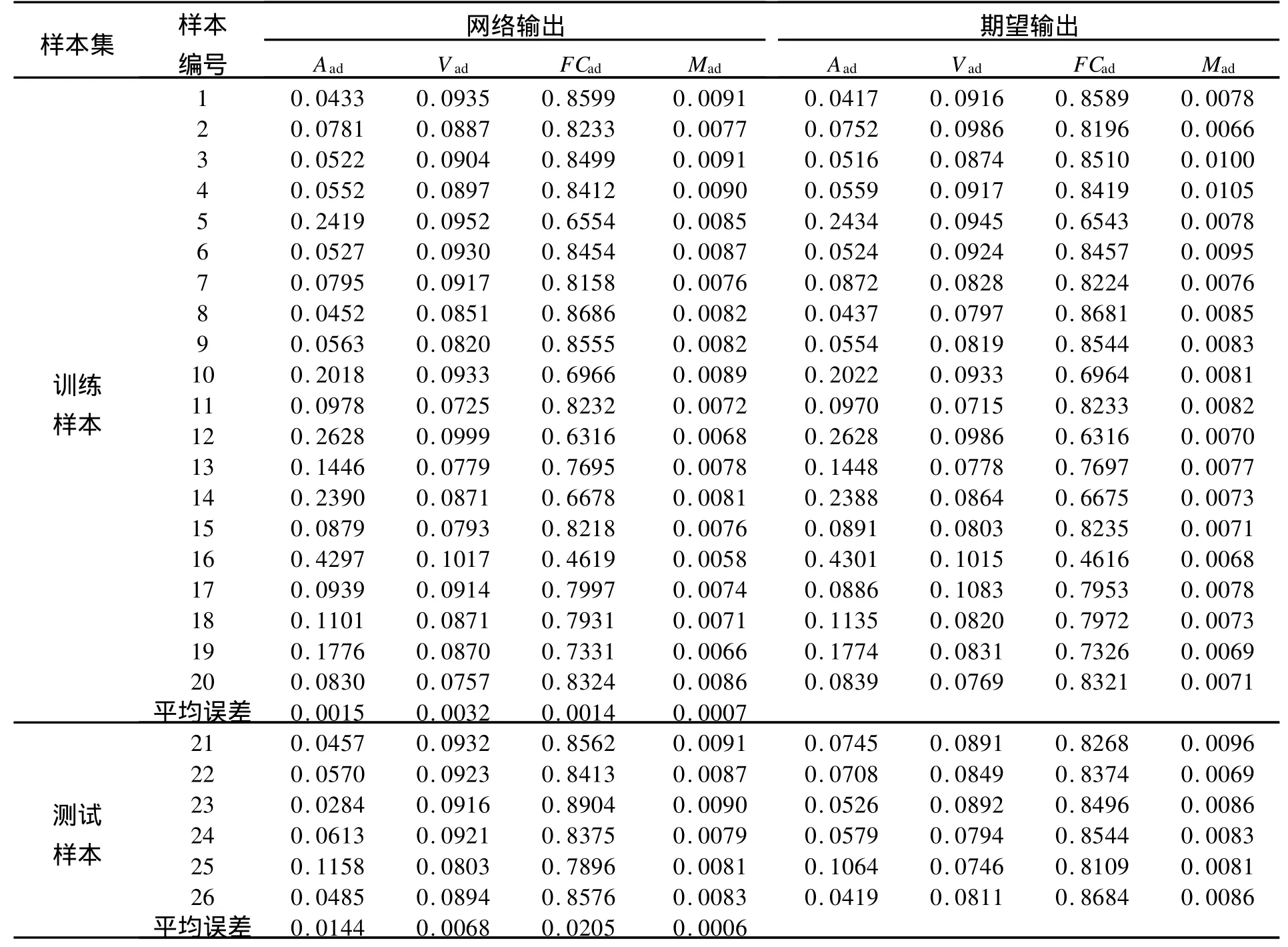
表2 网络测试结果及误差分析表
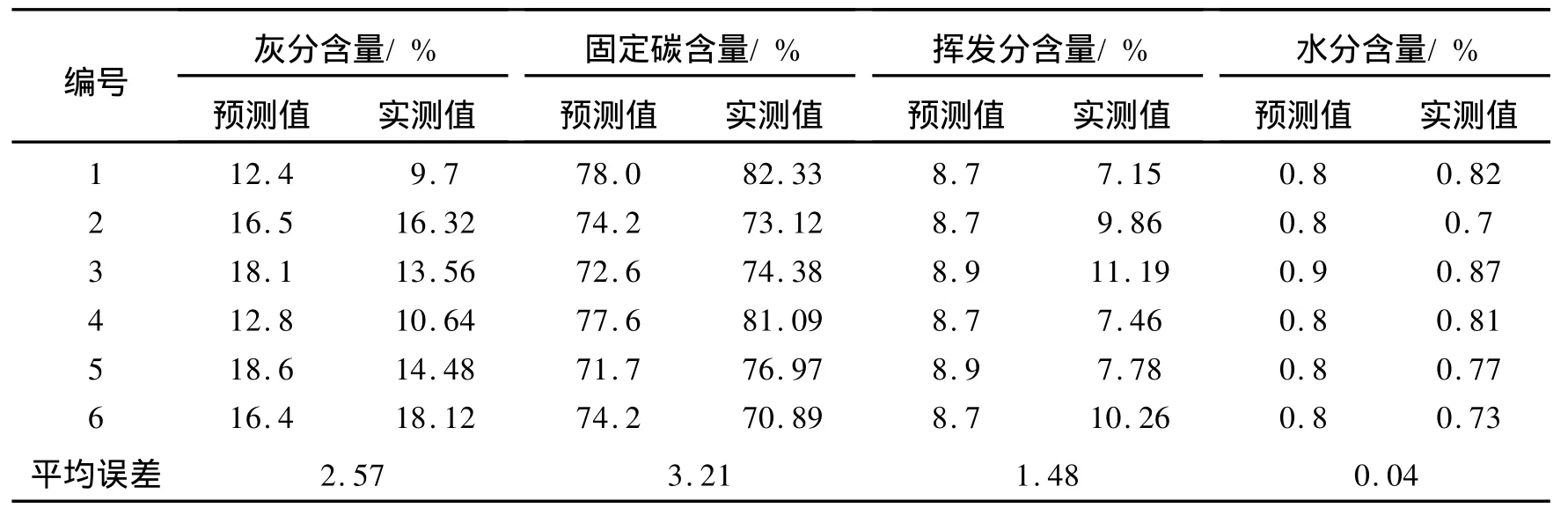
表3 研究区B井煤质分析对比表
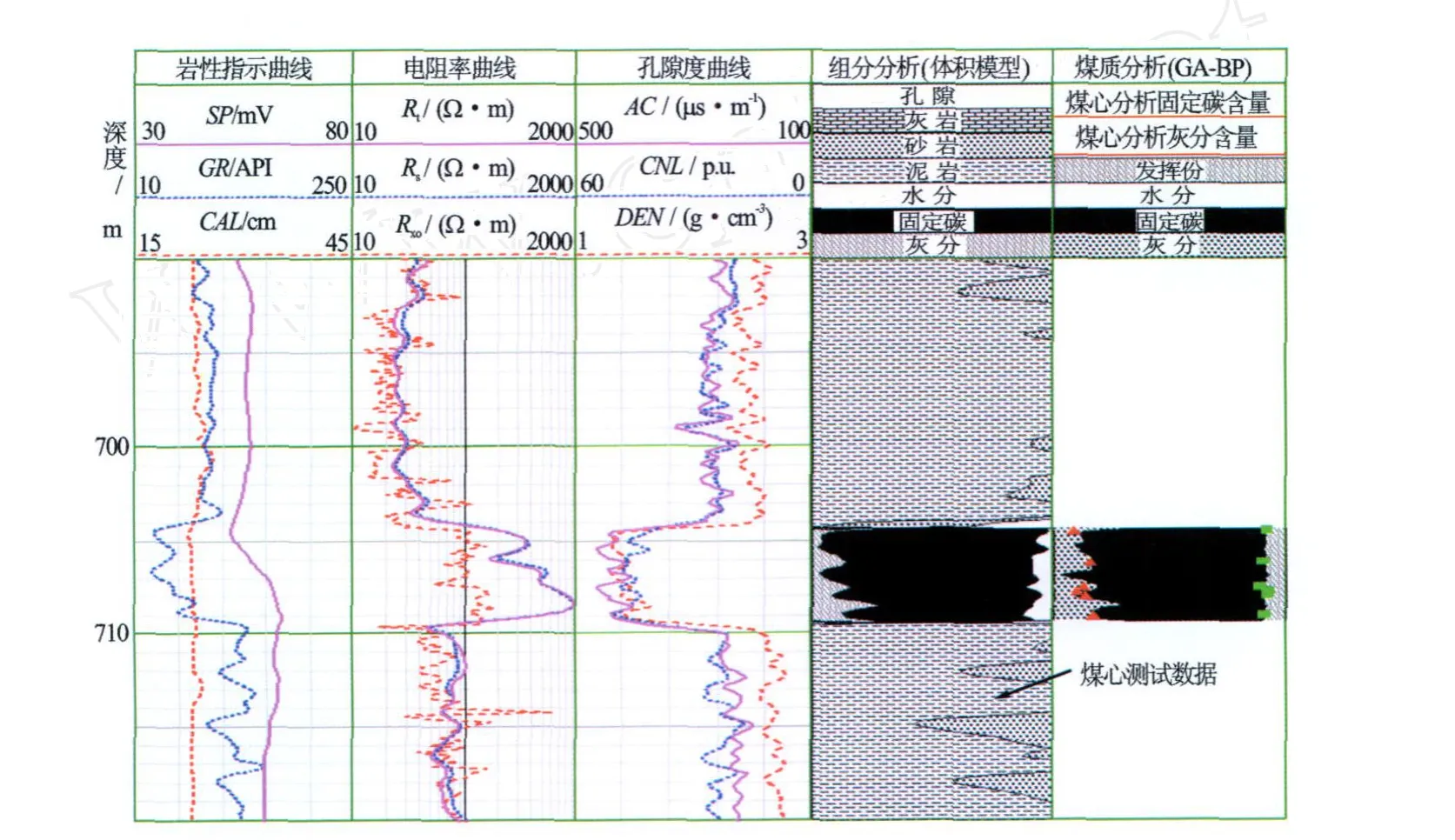
图3 研究区B井某煤层煤质评价成果图
4 结 论
(1)将遗传算法应用到BP神经网络中,通过优化神经网络的连接权值及阈值,解决了由于BP神经网络初始权值的随机性以及标准BP算法易陷入局部最小的问题,网络训练精度及运算速度都得到提高。
(2)将GA-BP神经网络引入煤质测井评价中,基于GA-BP神经网络的煤质参数预测方法可不考虑具体数学模型,可以综合利用多种测井参数,能够“隐式”表达出煤质参数与测井响应信息间的复杂非线性关系,且避开了选择测井解释参数的难点。
(3)应用 GA-BP神经网络模型对研究区10多口井煤层进行了煤质测井分析,预测结果与煤心测试资料能够很好匹配,具有较高的预测精度。但这种方法对样本数据具有很大的依赖性,当样本资料较少或代表性较差时,网络的判断能力差,预测效果便会降低。另外,样本数据的选取及预处理、网络结构及网络参数的确定也很关键,有待进一步研究。
[1] 侯俊胜.煤层气储层测井评价方法及应用[M].北京:冶金工业出版社,2000.
[2] 章立清.基于遗传神经网络的煤层瓦斯含量预测[J].煤矿安全,2007(9):23-25.
[3] 魏俊超.BP神经网络算法改进研究[C]∥山东省计算机学会2005年信息技术与信息化研讨会论文集, 2005.
[4] 雷英杰,张善文,李继武,等.MA TLAB遗传算法工具箱及应用[M].西安:西安电子科技大学出版社, 2005.
[5] 刘明军.遗传BP神经网络模型在彬长矿区测井数据岩性识别中的应用研究[D].北京:煤炭科学研究总院,2009.
Application of Genetic Neural Network to Coal Quality Evaluation Based on Log Data
CHEN Ganghua,DONGWeiw u
(College of Geo-resources and Info rmation,China University of Petroleum,Qingdao,Shandong 266555,China)
Coalbed methane reservoir log data interp retation results often show multi-solutions, ambiguity and uncertainty due to its heterogeneity and anisotropy.Put fo rw ard is amethod to imp rove network training accuracy and coalbed methane reservoir evaluation accuracy by combining genetic algorithm and neural network.Thismethod uses genetic algorithm to op timize neural network connection weights and threshold.It increases computing speed by avoiding its disadvantages that standard BP algo rithm is ap t to trap in local m inimal solution,and genetic algo rithm is w eak at the locally searching capability.Introduced is the p rocess for op timizing neural network connection weights and threshold and coal quality parameters forecast.Established is a coal quality log evaluation model based on GA-BP neural network,learning-samp les selection and network structure determination,and data no rmalizing.Comparative analysis of 26 samp les show s that this algo rithm has higher accuracy and faster p rocessing speed.Practical app lications in mo re than 10 w ells indicate that the p rediction resultsof GA-BPmethod match w ellw ith coal co re test data, and have good consistency w ith volume model calculation results.
log interp retation,coalbed methane,coal quality analysis,geophysical logging,BP neural network,genetic algorithm
P631.84 文献标识码:A
十一五国家重大科技专项“煤层气地球物理勘探关键技术”(项目编号2008ZX05035)
陈钢花,女,1963年生,教授,主要从事测井数据处理与综合解释方面的教学与科研工作。
2010-10-18 本文编辑 王小宁)
猜你喜欢
选煤技术(2022年3期)2022-08-20
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
科技创新与应用(2020年6期)2020-02-29
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中国煤层气(2015年6期)2015-08-22
