
语料库检索的模式、问题及启示
2011-12-05 06:38:16陈功
当代外语研究 2011年10期
陈 功
(北京外国语大学,北京,100089)
1.引言
目前语料库已经被越来越多的研究者所接受,成为语言研究的“默认数据源”(Teubert 2005)。通过语料库检索软件对语言现象进行检索,能够系统地对海量的文本进行审视,并且快速获得该语言现象使用的基础数据,如频数信息,使我们有可能发现一些过去从未有机会发现的语言事实(Sinclair 1991)。可以说,语料库检索已经成为语言研究的重要手段之一。研究者若能对语料库进行有效、准确的检索,不仅可以观察到丰富的语言现象,还可以从语料库中获得科学、准确的基础数据。
然而,在语料库语言学研究飞速发展的过程中,语料库检索这一看似简单实则重要的问题被搁置了下来。本文认为,在语料库用户结构逐渐多元化的今天,语料库检索方面的问题开始凸显。主要基于以下两个现实:(1)语料库研究不再局限于本领域或相关领域的研究者,不同学术背景的研究人员纷纷介入(卫乃兴2009)。新的研究群体对语料库研究方法的完全接纳需要一个过程,而且并不是所有人都能最终完全掌握。(2)具体到语料库检索方面,如今网络搜索引擎的强大影响力让很多研究者误认为,语料库检索操作很简单。但是,在实际检索过程中,我们往往容易忽略很多重要的细节,从而导致语言现象的漏检或误检。因此,如果我们对语料库检索的有效性和准确性不给予足够的重视,语料库研究的价值可能会大打折扣。
2.语料库检索模式
对不同格式的语料库①进行检索,需要相应检索工具的支持,这是语料库检索的一个重要前提。检索工具的性能和局限暂且不论,作为语言研究者,我们更应该关注的是如何最大限度地利用好已有的检索工具,从语料库中准确查找出符合研究目的所需的语言信息。这就要求我们要有针对性地使用不同的检索模式,以达到预期的研究目的。
按照用户所使用的检索语言,我们将常用的语料库检索分为以下三种模式:自然语言检索、人工语言检索、自然语言和人工语言相结合的检索。
2.1 自然语言检索
自然语言检索,顾名思义,即通过构成语料库文本的字面字符串(literal string)进行的语料库检索。检索项可以是任意的单词、短语或句子。是三种模式中最简单易学的检索方式,主要有以下两方面的优势:(1)该检索模式的操作方式简单,往往是研究者在研究初期观察语料时最常用、最便捷的检索方式。通过观察索引行可以帮助研究者判断该语言现象是否具有深入研究的价值;(2)对于语料库初学者来说,直接使用自然语言进行检索更符合其行为习惯,而且容易上手,因此他们大多倾向于使用自然语言检索。目前,我国语料库研究者能够从互联网获取的通用性英语语料库检索工具已经达10余种(李亮2007),基本上都支持自然语言检索。
然而,自然语言检索模式往往无法满足较为复杂的研究需求。例如,在英语三词复杂介词②的研究中,如果使用自然语言检索模式,研究者首先需要解决的问题就是如何穷尽所有的三词复杂介词。在这种模式下,语料库检索反而变得复杂、繁琐,而且无法充分利用语料库研究方法的优势。可见,自然语言检索模式虽简单易懂,但其有限的检索表达能力在实际研究中局限性较大。
2.2 人工语言检索
所谓人工语言检索,其实是相对于自然语言检索而言的。这里探讨的人工语言主要有两种③:语料库标注码和正则表达式。两者产生的目的和发展阶段虽各不相同,但都是根据自然语言设计的规范性人造语言,为语料库研究突破自然语言检索模式的局限提供了最大限度的可能性。
2.2.1 语料库标注码检索
多层级标注是对语料库进行深度分析的必备条件(梁茂成2006)。因此,标注码检索模式下,首先要求对语料库生文本(raw text)做进一步加工,按照制定好的标注方案对语料库进行标注,如词性标注、句法标注、语义标注等,才能“从语言学的角度对语料库进行解释”(Leech 1997:2)。目前通行的英语语料库大部分都为研究者提供了带有词性标注的语料(POS tagged data)。
标注给语料库增加了信息,也就意味着,研究者可以充分利用这些信息拓展自己的研究。Tognini-Bonelli(2001)认为标注使得语言的结构容易把握,方便从抽象层面进行语言研究。这是该检索模式的一大优势。以词性标注为例,词性赋码大多是在传统语言学词类划分的基础上设计的,因此,同类词的赋码便具有共同的特征,如在CLAWS赋码集中,情态动词的码为VM。也就是说,只需检索VM就可以得到包含所有情态动词的索引行和相关数据。Hunston(2002/2006:79)把这种通过标注码进行语料库研究的方法称为“基于类”(category-based)的研究方法。其检索项可以是单个码或者多码序列,取决于研究者的研究目的。
显然,与基于自然语言的检索相比,使用标注码进行语料库检索在研究某一类语言现象上优势明显,但在使用中也存在一些问题。首先,对于多数初级用户而言,对不同格式标注码的熟悉和灵活使用需要一个过程。其次,任何一种语料库标注码的设计都不是完美的,这也会给研究带来不可避免的问题。我们将在第三部分做进一步探讨。
2.2.2 正则表达式检索
正则表达式成熟于计算机程序汇编工作中对文本处理的需求。有着同样需求的语料库语言学研究者正是看到了正则表达式出色的文本处理能力,而将其应用到了语料库研究中来。“这种技术简洁而功能强大,可以用为数不多的几个符号来匹配各种存在一定规律的字符串。……可以极大地提高检索效率,因此正则表达式是语料库检索和文本清洁过程中必备的技术”(梁茂成等2010:17)。
与语料库词性赋码的类属相比,正则表达式的一些符号可以表示比字符串更大范围的“类”的概念,如S(表示所有非空格)、w(表示所有的字母、数字和下划线)、d(表示所有的数字);还可以表示字符串的数量等,如{1,}表示字符串使用一次以上,那么very{1,}可以匹配very使用一次以上的情况。不过,单单使用正则表达式往往无法实现对具体语言现象的检索。因此,在实际的语料库应用研究中,正则表达式通常会和语料库标注码或字符串一起作为检索项使用,以便更准确地定位检索目标,实现较好的查准率。例如,如果要在CLAWS赋码文本中观察have所有形式的使用情况,则可以通过两种人工语言相结合的方式,检索“w+_VHw”④轻松得到观察语料。目前,大部分语料库检索软件和文本处理工具都支持正则表达式。
近年来,越来越多的语料库研究者已经意识到了正则表达式在语料库检索和文本处理中的强大功能。但是,对于大多数非计算机专业背景的研究者来说,正则表达式是一种完全不熟悉的语言,加之其易读性差,导致用户在理解和接受方面还存在困难,这在一定程度上也限制了该检索模式的推广。为了让更多的研究者能够享受正则表达式带来的便捷,国内学者,如梁茂成教授,为此做了一系列的努力,编写出了国内第一款免费的正则表达式编写辅助工具Pattern Builder(参见梁茂成2009;梁茂成等2010),不仅可以方便初学者了解正则表达式在检索中的作用,还为中高级用户提供了正则表达式测试功能。
2.3 自然语言和人工语言相结合的检索
在实际的语料库研究中,除了自然语言检索和人工语言检索之外,还有一种非常重要的检索模式,即将自然语言和人工语言相结合进行检索。简单来讲,就是将“字符串+语料库标注码”、“字符串+正则表达式”或“字符串+语料库标注码+正则表达式”作为检索项的检索模式。目的是为了最大限度地准确完成研究者制定的检索任务。
例如,在CLAWS赋码的文本中观察“it is+形容词+that…”结构,可将检索项写为:
it_(S+)sis_(S+)s(S+)_JJsthat_(S+)
这个检索项包含了字符串(it,is,that)、语料库词性标注码(JJ,表示普通形容词)和正则表达式(S+和s,其中S+用于匹配未知的标注码或词,s表示空格)。检索结果如下图所示:

不难看出,组合检索模式不仅突破了自然语言有限的检索表达能力,还发挥了人工语言在类属关系等方面的优势。具体来说,组合模式一方面利用字符串或标注码进行精确定位,另一方面借助正则表达式强大的匹配功能进行查找,有效实现了对某一语言现象的检索。可以预见,这种组合模式的检索将在语料库研究中发挥愈加重要的作用,应该引起研究者的关注。
3.语料库检索中可能存在的问题及原因
在语料库研究中,我们不仅需要根据研究内容选择有效的检索模式,同时也要确保检索过程的科学性和检索结果的准确性。作为语料库研究的前期工作之一,语料库检索对后续的研究意义重大。因为通过初期检索获得的基础数据,如频数,往往成为研究者进一步进行统计检验和分析的基础,基础数据一旦出现问题,将会给整个研究带来颠覆性的后果。而“作为语料库研究的一个基本前提,数据及其算法的准确性具有至高无上的重要性”(陈功、梁茂成2010)。因此,我们对语料库检索需持科学谨慎的态度。
3.1 语料库检索的问题
语料库检索过程中可能发生这样或者那样的问题,对各种因素或细节的忽视都会导致检索结果的不准确。下面分别用两个简单的案例说明:
案例一:
检索对象:英语三词复杂介词,如bymeansof,intermsof等;
检索文本:经过CLAWS自动词性赋码后的语料库(LOCNESS),其中三词复杂介词有统一的赋码,如:in_II31terms_II32of_II33;
检索项:根据CLAWS三词复杂介词赋码的特性,将检索项设置为:
(S+_II31)s(S+_II32)s(S+_II33)
检索结果:经过人工核对,能够全部检索出带有相应标注码的三词复杂介词,说明该检索模式还是有效的。但是通过反向随机检查⑤却发现,部分研究内容由于被赋予了其他形式的标注码而被遗漏,如by_IIvirtue_NN1of_IO,for_IFpurposes_NN2of_IO等。
案例二:
检索对象:形容词最高级中使用most的情况,如themostsignificant;
检索文本:WECCL(1.0)赋码语料库;
检索项:根据已知项和待检项,设置如下:
(the_AT)s(most_RGT)s(S+_JJ)
检索结果:未找到匹配的检索对象。检索失败的原因是:检索项编写格式与文本标注格式不一致,即WECCL(1.0)语料库词性赋码格式为:“单词+空格+<词性标注码>”,如“the
(thes
3.2 语料库检索问题之原因分析
通过上述两个简单的案例可以发现,语料库检索需要考虑许多方面的因素,有时即便是忽略一个空格都会造成检索结果的不准确,而“检索的效果会直接影响到研究的信度”(梁茂成等2010:70)。因此,在语料库检索中,研究者要结合研究目的设计准确的检索模式,做到精确检索。当然,还要找出容易导致检索失误的原因,这对提升语料库检索的准确性意义重大。本文认为,语料库检索结果不准确可能是由客观和主观两方面因素造成的。
3.2.1 客观因素
研究者有时会在语料库检索的实际操作中发现,有些困难和问题是难以避免的。然而,不论如何,我们都应对其根本原因有客观充分的认识。
(1) 不论是语料库加工者还是语料库应用研究者,对语言的认识都是有限的。相应地,为语料库添加语言学信息的深度也是有限的,标注码的设计也无法做到尽善尽美。例如,what在CLAWS词性赋码文本中被标注为DDQ(wh-determiner),而what在具体使用中绝非只有这一种用法,如what在感叹句中的标注就值得我们考虑(What_DDQa_ATterrible_JJlife_NN1 !_!)。那么,标注码的设计到底应该细致到何种程度才算合适?过于宽泛,则无法反映语言的特殊现象;过于细致,却容易失去分类的意义。在大量的语料面前,这个矛盾让语料库加工者很难找到一个合理的平衡。而这个问题对语料库应用者的实际操作来说也有不小的影响,很多时候,我们只能通过人工判断来筛选合乎研究目的的检索结果。
(2) 自然语言是在不断发展变化的,相对而言,语料库标注码的设计则略显滞后。在面对一些尚处在发展过程中、或尚未进入词典的语言现象时,标注码的设计者可能会有所忽略。例如,案例一中CLAWS对英语三词复杂介词的标注,就可能遗漏了一些语言现象。其中inregardto被标注为in_II31regard_II32to_II33,而inregardsto则被标注成了in_RPregards_VVZto_II。显然,CLAWS词性标注码的设计者将inregardto放在了固定复杂介词之列,而未给inregardsto一个合理的身份。然而,通过BNC在线检索系统(http:∥corpus.byu.edu/bnc/)检索发现,inregardto使用频率为3次,而inregardsto出现了7次;只不过两者出现的语体有所差异,前者均出现在书面语正式文体中,而后者则多出现在口语中。由此,我们至少可以肯定,inregardsto在语言使用中的地位已经基本确立。对于我们语料库应用研究者来说,一旦发现类似的、由于语言演变造成的标注码滞后问题,唯一的补救办法就是在经过考证之后,修改语料库中的赋码,并加以说明,使检索结果尽可能科学准确。
(3) 语料库标注的误差。冯志伟(2009:xxviii)总结了学术界对语料库标注的批评,其中一种批评认为,“手工标注的语料库准确性高而一致性差,自动或半自动的标注一致性高而准确性差,语料库的标注难以做到两全其美。”以自动词性标注为例,CLAWS7对英语本族语者书面语进行自动标注时,赋码准确率可达到96%~97%(梁茂成2006)。虽然达到这样的准确率已实属不易,但误差是客观存在的,如CLAWS将in_RPregards_VVZto_II中的regards标为动词第三人称单数显然是不对的。因此,作为研究者,我们在检索中要注意细心观察索引行,及时排除类似问题。尤其在使用人工标注的语料库时,更要警惕标注一致性的问题。
3.2.2 主观因素
客观因素虽然存在,但主观因素往往是导致语料库检索出现问题的直接原因。主要有以下几个方面:
(1) 未做好检索项的设计。在考虑检索需求时,语料库研究者应该尽可能全面地考虑某一语言现象的各种使用情况。比如,理论上,修饰名词的形容词可以有无穷多个,那么我们在编制检索项时就应该尽量照顾到这个现象。只有充分考虑各种可能性,才能使语料库检索结果尽可能穷尽所有的相关语言现象。但是规则之后总是潜藏着一些例外。比如,绝大部分的形容词都在名词之前做修饰语,但也有一些只能位于名词之后。而哪些问题可解决,哪些问题不可避免,都是我们在研究前期的不断尝试中应该考虑清楚的。
(2) 未了解语料库文本的特征。在进行语料库检索之前,研究者首先需要认识文本,确定研究应使用生文本还是经过标注的文本。如果是经过标注的语料库,则要确认标注内容(是词性标注,还是句法标注、语义标注,或错误标注等)、标注格式⑥(即单词和标注信息的组合呈现方式),以及所依据的标注集(tagset)分别是什么。案例二中的检索失败就是由于不了解语料库赋码文本的格式导致的。
(3) 未了解检索工具的设置。检索工具启动之后均表现为系统的默认设置,如AntConc3.2.2w启动之后,Search Term默认设置为Words,不区分大小写,File Setting为.txt文件,Tag setting为Show tags等等。如果研究有特殊要求,我们就应该对检索工具进行重新设置。如果想用AntConc3.2.2w检索What一词在句首的使用情况,就应将Search Term的第二个选项Case选中,同时在检索框中输入首字母大写的What(参见下图)。
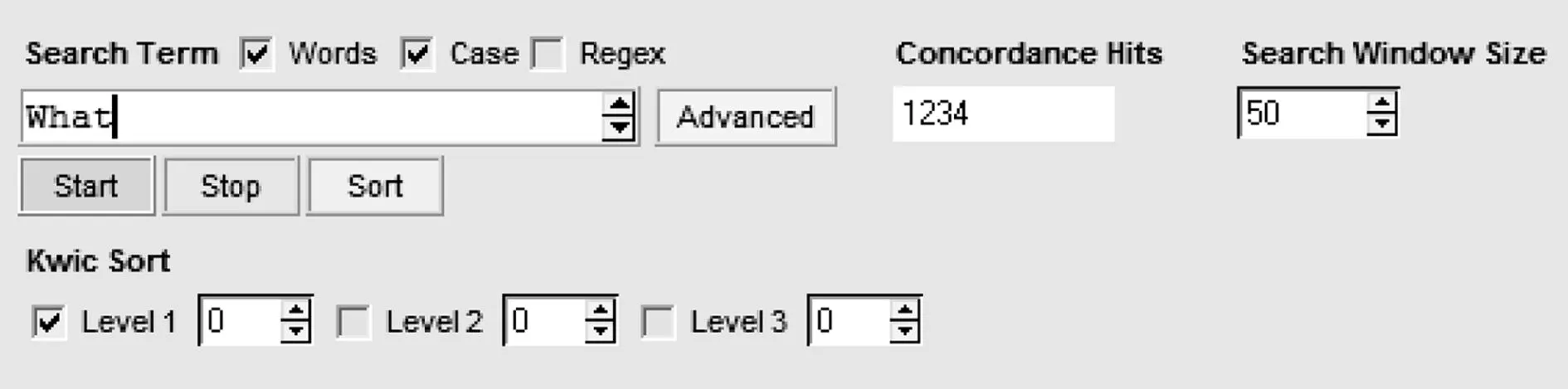
同理,需要使用正则表达式进行检索时,也要点击Regex的复选框进行设置。
(4) 未做好人工核准工作。语料库研究有了工具的辅助,并不意味着单靠工具就可以得到准确的结果,相反,语料库检索的每一步都离不开研究者的检查核对。首先,检索项编写好之后要反复测试,以便尽可能穷尽相关内容,在使用正则表达式时尤其应该注意其匹配范围。其次,要对检索结果进行反查,以便及时发现遗漏问题。另外,需要注意的是,为了不遗漏任何一例语言现象,检索项设置时往往需要扩大匹配目标,但同时也不可避免地导致了冗余语例的出现。因此,还需要人工判断检索结果,剔除不相关内容。
4.结语
语料库检索是一个反复的、循环式的、不断完善优化检索结果的过程。语料库检索的有效性和准确性应该成为研究者密切关注的问题。“能否使用正确的方法对不同格式的语料库文本进行检索是语料库数据分析和提取的关键”(梁茂成等2010:57)。做好一次语料库检索,其实现过程要比听上去复杂得多,这其中的每一个环节都需要研究者认真对待。我们反对唯工具论,语料库研究工具固然是研究的有力助手,但却愈发需要研究者深刻思想的指引和严谨细致的科学态度的规范。正像Hunston(2002/2006:214)的感慨一样:“语料库使生活变得更加简单,但语料库同时也使生活变得更加复杂”,语料库研究不仅仅让我们“更加无法忽略语言本身无限的复杂性”,也需要我们能够正视研究过程的复杂性并谨慎对待之。
附注:
① 主要指未经过标注(raw)或经过标注(tagged)的语料库。其中,标注过的语料库也可能有不同的呈现方式,详见附注⑥。
② 英语复杂介词(complex preposition)指的是在语义和句法功能上与单个介词相同的多词序列,包括两词组合(becauseof)、三词组合(bymeansof)以及四词组合(asaresultof)等(Biberetal.1999:75)。
③ 严格来讲,一些检索工具指定的通配符也可以在语料库检索中发挥积极的作用,但是由于各个检索工具的通配符并不一定有统一的设置标准,因此,本文在此暂不做讨论。
④ 在“w+_VHw”这个表达式中,w+匹配have所有的形式,VH为have各形式词性标注码中共有的前两位,后面的w匹配一个字母、数字或下划线,也就是说“VHw”可匹配have所有形式的词性标注码,如VH0(have原形)、VHZ(has)、VHG(having)等。
⑤ 得到检索结果后,通过观察所有三词复杂介词的组合规律,发现第一位上的介词通常为in,by,for,on,with,as,而最后一位上的介词通常为of,from,to,for,with。这样,便可以通过这些已知信息反过来对检索结果进行核查,如(in_S+)s+(S+_S+)s+(of_S+)。
⑥ 以词性标注为例,呈现方式主要有以下几种:word_tag,word
Biber, D., S.Johansson, G.Leech, S.Conrad & E.Finegan.1999.LongmanGrammarofSpokenandWrittenEnglish[M].London: Longman.
Hunston, S.2002/2006.CorporainAppliedLinguistics[M].Beijing: World Publishing Corporation.
Leech, G.1997.Introducing corpus annotation [A].In R.Garsideetal.(eds.).CorpusAnnotation:LinguisticInformationfromComputerTextCorpora[C].London/New York: Longman.1-18.
Sinclair, J.1991.Corpus,Concordance,Collocation[M].Oxford: Oxford University Press.
Teubert, W.2005.My version of corpus linguistics [J].InternationalJournalofCorpusLinguistics10(1): 1-13.
Tognini-Bonelli, E.2001.CorpusLinguisticsatWork[M].Amsterdam/Philadelphia: John Benjamins.
陈功、梁茂成.2010.首届全国学习者语料库专题研讨会综述[J].外语电化教学134:77-80.
冯志伟.2009.导读[A].R.Mitkov.牛津计算语言学手册[M].北京:外语教学与研究出版社.
李亮.2007.英语语料库检索工具的设计理念及其深层化[J].外语电化教学118:16-20.
梁茂成.2006.学习者英语书面语料自动词性赋码的信度研究[J].外语教学与研究(4):279-286.
梁茂成.2009.词性赋码语料库的检索与正则表达式的编写[J].中国外语教育(2):65-73.
梁茂成、李文中、许家金.2010.语料库应用教程[M].北京:外语教学与研究出版社.
卫乃兴.2009.语料库语言学的方法论及相关理念[J].外语研究(5):36-42.
猜你喜欢
吉林电力(2022年2期)2022-11-10 09:24:38
疯狂英语·初中天地(2021年8期)2021-11-20 05:59:44
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
高中生·天天向上(2018年2期)2018-04-14 09:33:14
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
语言与翻译(2015年4期)2015-07-18 11:07:45
印刷技术·包装装潢(2015年11期)2015-02-16 08:25:49
印刷技术·包装装潢(2014年5期)2014-08-27 16:56:19
印刷技术·包装装潢(2013年7期)2013-04-29 00:44:03
当代外语研究(2010年3期)2010-03-20 14:36:38
