
基于人工鱼群优化的支持向量机的水文预报系统
2011-11-20 08:19晋美次旦
水利信息化 2011年1期
晋美次旦
(西藏自治区水文水资源勘测局,西藏 拉萨 850000)
0 引言
机器学习是使计算机能模拟人的学习行为,自动地通过学习获取知识和技能,不断改善性能,实现自我完善[1]。机器学习中最实用的理论和算法包括概念学习、决策树、神经网络、遗传算法、规则学习、基于解释的学习和增强学习等。
人工神经网络主要是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。该算法发展较早,并得到了广泛的应用,比较典型的网络模型和学习算法有单层感知器、Hopfield网络、Boltzmann 机和反向传播算法(BP)等[2-3]。遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
水文预报是根据已知信息对未来一定时期内的水文状况做出定性或定量的预测[4]。庞博[5]等人将人工神经网络技术运用到水文预报中,提出了总径流线性响应模型的模拟径流和降雨作为人工神经网络模型的输入来预报径流;隋彩虹[6]等人提出了人工神经网络模型的渭河下游洪水预报。
Vapnik 等人于 1995年在统计学习理论的基础上首次提出支持向量机(Support VectorMachines,SVM)的新学习算法,2001年李晓磊[7]等人根据动物自治体的寻优模式,提出了人工鱼群算法。本文对支持向量机提出一种改进算法,提出基于人工鱼群优化的支持向量机,并将其应用于拉萨河流域水文预报系统中。
1 支持向量机算法
1.1 支持向量机基本理论
支持向量机算法是在有限样本条件下对统计学习中的 VC 维理论(Vapnik Chervonenkis dimension)和结构风险最小原理的实现。与传统的神经网络学习方法相比,SVM 方法以最小结构风险代替了传统的经验风险,求解的是二次型寻优问题。
该算法主要涉及2个概念,即 VC 维和最优分类超平面。VC 维是统计学习理论定义中有关函数集学习性能指标中最重要的指标,VC 维反映了函数的学习能力,VC 维越大则学习机器越复杂;最优分类超平面对高维空间而言,是要求分类超平面不但能将 2类正确分开,而且使分类间隔最大,以确保经验风险和置信风险最小化,这是支持向量机的核心思想之一。
1.2 支持向量机特点
1)是专门针对有限样本情况的,其目标是得到现有信息下的最优解,而不仅仅是样本数趋于无穷大时的最优值。
2)算法最终将转化成为二次规划问题,二次规划问题是研究较早、已有比较成熟的求解方法的非线性规划问题之一,从理论上说,得到的将是全局最优点,解决了在神经网络方法中无法避免的局部极值问题。
3)一般的升维都会带来计算的复杂化。由于应用了核函数的展开定理,所以根本不需要知道非线性映射的显式表达式;支持向量机算法同时将实际问题通过非线性变换转换到高维的特征空间,在高维空间中构造线性判别函数来实现原空间中的非线性判别函数,特殊性质能保证机器有较好的推广能力,巧妙地解决了维数灾难问题,同时也解决了算法复杂度与样本维数无关。
6)少数支持向量由训练样本集的1个子集样本向量构成,在子集的拉格朗日乘子均不为零,只有这些少数支持向量对最终结果起决定作用;而那些拉格朗日乘子为零的样本向量的贡献为零,对选择分类超平面是无意义的。这可以帮助抓住关键样本,“剔除”大量冗余样本,该方法不但算法简单,而且具有较好的鲁棒性。
7)由于有较为严格的统计学习理论作保证,应用支持向量机方法建立的模型具有较好的推广能力。SVM 方法可以给出所建模型的推广能力的确定的界,这是目前其它任何学习方法所不具备的。
虽然支持向量机算法的性能在许多实际问题的应用或相对于其他的算法都有明显的优势,但该算法在计算时也存在着一些问题,包括训练算法速度慢,算法复杂难以实现,以及检测阶段运算量大等。
2 基于人工鱼群优化的支持向量机算法
本文提出利用人工鱼群的并行性、简单性、快速性等优点来克服支持向量机的缺点。基于人工鱼群优化支持向量机算法(AFSVM)是人工鱼群算法和支持向量机算法的一种混合算法。
2.1 人工鱼群算法基本理论
基本鱼群算法中,主要利用鱼的觅食、聚群和尾随行为,从构造单条鱼的底层行为做起,通过鱼群中各个个体的局部寻优,达到全局最优值在群体中突现出来的目的。因而人工鱼群算法首先要构造人工鱼(AF)。
觅食行为:在自然界中鱼儿在水中随机移动,当发现食物时,会向食物浓度高的地方迅速移动,故人工鱼也需要模拟此种行为。
聚群行为:鱼在游动过程中会自然地聚集成群,这也是为了保证群体的生存和躲避危害而形成的一种生活习性。Reynolds 认为鸟和鱼类的群集的形成并不需要1个领头者,只需要每只鸟或每条鱼遵循一些局部的相互作用规则即可,然后群集现象作为整体模式从个体的局部的相互作用中突现出来。Reynolds 所采用的规则有3条:1)分隔规则,尽量避免与临近伙伴过于拥挤;2)对准规则,尽量与临近伙伴的平均方向一致;3)内聚规则,尽量朝临近伙伴的中心移动。
尾随行为:鱼儿在觅食时,当1条或几条鱼发现了食物,其他鱼会尾随这些鱼向食物浓度高的区域靠近,最终得到食物。
算法中设1个公告板,用以记录最优人工鱼个体状态及位置的食物浓度值。每条人工鱼在行动1次后就将自身当前状态与公告板进行比较,如果优于公告板则用自身状态取代公告板状态。
人工鱼群算法已经应用到很多实际问题的寻优过程中,在寻优速度和防止陷入局部最小量都有明显优点[7-10]。
2.2 AFSVM 算法
AFSVM 算法的基本思想是:首先初始化人工鱼群的规模。在权值可行域内随机生成人工鱼个体,每条人工鱼代表不同输入权值的1个支持向量机,从而形成初始鱼群,通过支持向量机计算出相应的预测值,并通过预测值和实测值的误差计算出各个人工鱼个体当前位置的食物浓度值,并与公告板的值比较大小,取食物浓度为最小值者进入公告板,将此鱼赋值给公告板。各个人工鱼分别模拟追尾和聚群行为,选择行动后食物浓度值较小的行为实际执行,缺省行为方式为觅食行为。各个人工鱼每次行动后检验自身的食物浓度并与公告板比较,如果优于公告板,则以自身取代之,直到判断迭代次数是否已达到。
1)在基于支持向量机的建模中,核函数的选择直接关系到所建立的模型的性能。本文是将 AFSVM算法应用到水文预测系统中,考虑到多数预测都是输入与输出之间存在高度非线性关系,所以拟选用径向基函数作为 SVM 的核函数,其形式为式中:xi为需要优化的输入变量;σ是由用户决定的核宽度,每个基函数的中心对应 1 个支持向量,它们及输出权值都是由算法自动确定的。
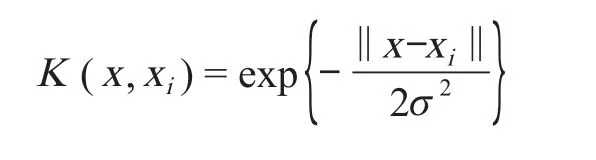
2)人工鱼的个体状态可以表示成Xi= {x1,x2,…,xn},其中xj为输入值;人工鱼当前所在环境的食物浓度为Y,该变量的值为通过以径向基函数为核函数的支持向量机预测出的值与实际值之间误差的平方;人工鱼之间的距离为dij= |ωij-ωij|next|,而ωj是各个输入值xj的权值,也是寻优值;人工鱼的感知距离为H;步长为K;δ为拥挤度因子。
3)AFSVM 算法步骤如下:
a.输入人工鱼群的群体规模N,最大迭代次数Mmax,人工鱼的可视域H,人工鱼的最大移动步长Kmax,拥挤度因子参数δ;
b.设置初始迭代次数m= 0,在控制变量可行域内随机生成人工鱼个体,形成初始鱼群;
c.计算初始鱼群各人工鱼个体当前位置的食物浓度值,并比较大小,取食物浓度为最小值者进入公告板,将此鱼食物浓度及各个xj(j= 1,2,…,n),分量的权值ωj(j= 1,2,…,n)赋值给公告板;
d.各人工鱼分别模拟追尾和聚群行为,选择行动后食物浓度值较小的行为实际执行,缺省行为方式为觅食行为;
e.各人工鱼每行动1次后,检验自身的与公告板的食物浓度,如果优于公告板,则以自身取代之;
f.中止条件判断,判断迭代次数是否己达到预置的最大次数,若是,则输出计算结果(即公告板的食物浓度值及各分量的权值),否则迭代次数 + 1,转步骤 d。
由以上算法可以看出,AFSVM 利用人工鱼群算法的并行性和快速性等优点,理论上,能够提高SVM 的训练速度,能够加速函数的拟合速度。
3 拉萨河流域水文预测系统总体框架
3.1 系统功能结构
定义1个输入空间X,X是水文实测值的集合。对于每个水文实测,具有n个特征信息,显然有X∈Rd。用一维向量x表示一次实测值,Xi= {x1,x2,…,xn,ω1,ω2,…,ωn},
式中:xj表示样本X的第j个特征值;ωj表示为样本X的第j个特征值的权值;R为实数。
Y'i为实测值用于训练向量机,Y'i∈R。在水文预测过程中,由于只需要通过 SVM 预测机、1组水文实测值及权值计算出1个预测值,所以定义Yi为预测值,并且定义Yi为大于零的实数值。基于人工鱼群优化的支持向量机的拉萨河流域水文预测系统的基本结构图如图1所示。
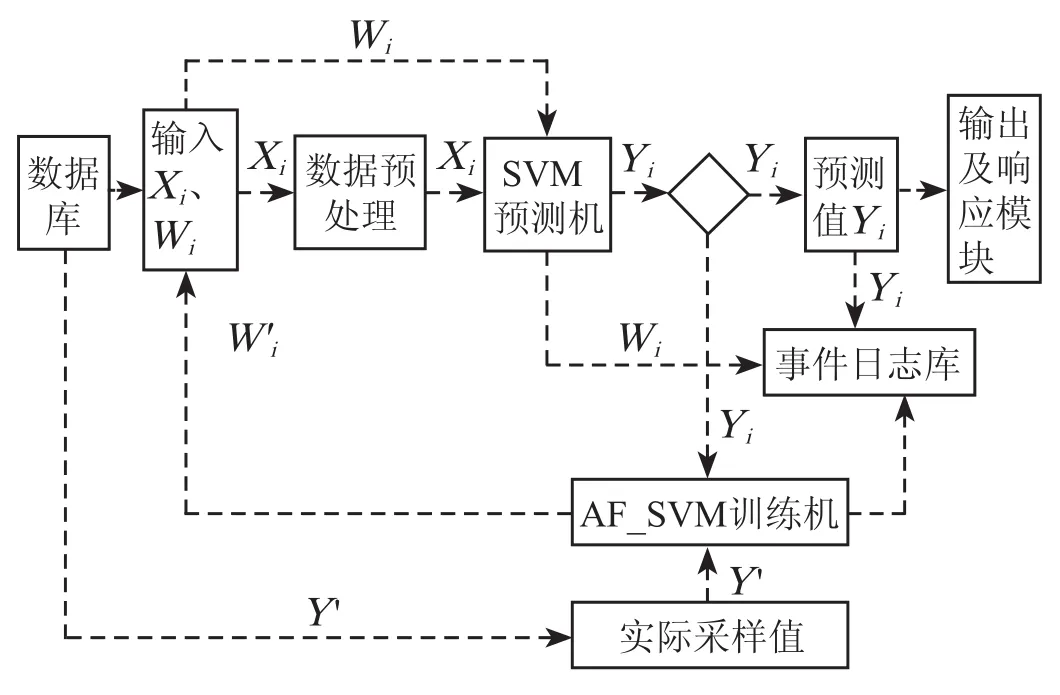
图1 基于 AFSVM 的拉萨河流域水文预测系统的基本结构图
处理流程为:首先从数据库查询几组数据,并从这几组数据提取出特征信息,特征信息由数据预处理模块进行数据预处理,得到 SVM 的输入向量形式,作为训练数据,如果处于 SVM 训练状态,则利用训练数据集经过 AF_SVM 训练器训练得到训练后的结果,即1组权值,这个部分称为 AF_SVM 的训练部分,然后利用训练部分得到的1组权值存入数据库中;如果处于 SVM 预测状态,由 SVM 预测模块对输入向量进行预测,得到预测输出值Yi,预测后将结果存入事件日志库,即这里的Yi代表着下一个时刻的水文预测值,就是1个大于零的实数值。并根据设置执行相应的响应操作,如发出警报、短信等。
系统分为5部分,具体如下:
1)AFSVM 训练机模块。对预先从数据库选定的训练数据集进行训练,并由数据预处理模块进行预处理。
2)SVM 预测机模块。该模块是整个系统最重要的部分,是预测系统的核心部分。利用 SVM 训练模块得到的 SVM 权值向量组对实测水文数据记录进行预测,预测的结果即1个大于零的实数值。
3)SVM 支持向量机库。用于存放 AFSVM 训练模块训练后在 AF_SVM 训练模块公告栏上的最终1组权值,这组各水文特征信息的权值从理论上讲应该为全局最优解。
4)事件日志库。用于存放已经预测出的历史事件,以便系统管理员日后审查历史记录。
5)输出及响应模块。该模块是整个系统的重要组成部分,它利用 SVM 预测模块预测得到的信息,通过将预测值与划分的各类警戒线比较,当有超过警戒线发生时,触发相应的各类警报,进行报警等各种必要的相应措施。
3.2 系统信息流
系统中各组件之间的信息流如图2所示。

图2 系统的信息流图
在图2中,实箭头代表系统的控制流,虚箭头代表系统的数据流向。因此,可以从数据流和控制流2个角度对系统处理流程进行分析。
1)从数据流向分析系统。首先从数据库中提出输入样本Xi= {x1,x2,…,xn} 及各个分量的初始权值ωi= {ω1,ω2,…,ωn},并设置训练控制量,然后将Xi= {x1,x2,…,xn} 传入数据预处理模块。在此对输入样本进行合理性和完整性检查,检查完后判断是否进行训练,如果是,则将输入样本和初始权值传入 AF_SVM 训练机中,在此对支持向量机的权值进行训练,训练后所得的全局最优解,即最优的权值,存入数据库中;如果否,则将输入样本和初始权值传入 SVM 预测机中,通过计算得出预测值,将预测值传入输出及响应模块中,通过比较预设的警戒值,做出最后的响应。在训练期间的每次迭代值存入事件日志库中,在预测期间,将预测值、权值及响应的事件也存入事件日志库中,以备为日后的维护和调试而查阅。
2)从控制流向分析系统。用户通过控制 的值来导向样本数据流和权值数据流的流向,是否流向训练机还是流向预测机;AFSVM 训练机训练结束后,向数据库发出更新权值表的信息;AFSVM 训练机和输出及响应模块发出更新事件日志库的信息。
3.3 系统的原型设计实现
本文模型主要针对拉萨河流域,根据拉萨河流域的自然条件[17],本文拟采用二水源新安江模型的产流模型的参数作为预测系统的输入量。
在 AFSVM 算法中,影响模型性能的有8个参数,容许误差b、惩罚因子C、核函数参数σ、人工鱼的群体规模N、人工鱼的可视域H、人工鱼的最大移动步长K和拥挤度因子δ。本文在选择参数时首先考察了参数对模型性能的影响。容许误差b= 0.2,C= 100,经过交叉检验法对参数选择,最终确定σ= 12,鱼群算法的感知距离H= 2.5,步长K= 0.3,拥挤度因子δ= 0.618,人工鱼个体数为50时模型有最好的表现。
系统原型设计后形成一些界面,主要包括水文数据列表、水位趋势图、流量图和信息显示窗口等,其中图3为系统的总界面,图4为流量详细图。
3.4 预测系统的评估和检验
本次对预测系统的评测采用拉萨实验站 1994年 1月 到 2003年 12月 120个月份 的实测流量数据为原始数据。以 1994年1月至 2002年12月的实测流量数据作为训练样本,以 2003年7月1~31日的实测流量数据作为预测样本。经过 AFSVM 和 SVM 这2种方法计算的流量预测值与实测值比较后所得的误差如表1所示。
实验结果表明 AFSVM 与标准 SVM 模型的预测精度差不多,并可以保证大部分预测出来的数据与实测数据之间的误差在《规范》要求的限度内。但训练速度 AFSVM 明显快于标准 SVM,AFSVM 对1994年1月至 2002年12月的实测流量数据训练模型时所需的运行时间为 73~82s,而标准的 SVM 用同样的数据训练所用时间为 147~152s,由此可以得到以下结论:
1)AFSVM 通过对历史样本的学习来建立预测模型,由于历史资料有限,能够得到的模型训练样本并不充足,可能会影响模型的预测性能,增多训练样本会使预测模型的性能更好。
2)支持向量占训练样本总数的比例较大,若能通过改进参数优化过程,构造1个支持向量数相对较小的分类面,将会得到更高性能的预测模型。
图3 系统的总界面

图4 流量详图

表1 实测流量与预测流量统计表
3)AFSVM 的训练算法明显优于标准的 SVM 的训练算法,尤其在训练速度上明显优于标准的 SVM学习算法,能够为水文预报提供更快捷的技术支持。
5 结语
机器学习是一个十分活跃、充满生命力的研究领域,同时也是一个困难的、争议较多的研究领域。在这个领域中,新的思想、方法不断地涌现,取得了令人瞩目的成就,但是还存在大量未解决的问题。当前人工智能研究的主要障碍和发展方向之一就是机器学习,因此机器学习有着广阔的研究前景。另外,由于机器学习与其他各种学科有着密切的联系,研究者应该从不同的研究环境和领域寻找多种学习体制和方法,同时机器学习的研究也在等待着有关学科的研究取得进展。
而水文预报方法也是不够成熟,影响水文预报的各种因素十分复杂,如太阳运动规律和大气环流影响等。鉴于水文要素历史演变趋势的预测也可能随着掌握资料的条件、分析规律的深入程度及综合各种方法进行合理取值时的可靠程度而存在相当的误差,因此在做水文预测时,必须参考诸多因素(尤其是气象因素),不断积累经验,探讨更为科学而实用的预报方法,以提高水文要素预报的精度。
因而,希望能够通过机器学习和人工智能技术的日益成熟,能够更好地模拟水文的复杂规律,从而能够更好地预测水文情报,以确保国家和人民的财产安全。
[1] Mitchell.Machine Learning[M].北京:机械工业出版社,2003: 45.
[2] 李鸿雁.人工神经网络峰值识别理论及其在洪水预报中的应用[J].水利学报,2002(6): 17-18.
[3] 王文圣,丁晶,刘国东.人工神经网络非线性时序模型在水文预报中的应用[J].四川水力发电,2000,19(增刊 1): 7-10.
[4] 包为民.水文预报[M].北京:中国水利水电出版社,2006: 131-137.
[5] 庞博,郭生练,熊立华,等.改进的人工神经网络水文预报模型及应用[J].武汉大学学报,2007(1): 33-36.
[6] 隋彩虹.基于人工神经网络模型的渭河下游洪水预报[M].北京师范大学,2006.
[7] 李晓磊,邵之江,钱积新.一种基于动物自治体的寻优模式:鱼群算法[J].系统工程理论与实践,2002(11): 20-22.
[8] 李晓磊,基于人工鱼群算法的参数估计方法[J].山东大学学报:工学版,2004(3): 32-33.
[9] 陈俊清,朱文兴.基于人工鱼群算法的分类规则发现[J].福州大学学报:自然科学版,2006(1): 47-49.
[10] 李晓磊,路飞,田国会,等.组合优化问题的人工鱼群算法应用[J].山东大学学报:工学版,2004,34(5): 64-67.
[11] 刘天仇.雅鲁藏布江水文特征[J].地理学报,1999(增刊 1):23-24.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
河北地质(2021年3期)2021-11-05
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
中外文摘(2017年19期)2017-10-10
河南水利年鉴(2017年0期)2017-05-19
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
电测与仪表(2016年3期)2016-04-12
