
基于改进ReliefF算法的Honeynet告警日志分析
2011-09-07 10:16蒋玉娇安和平
计算机工程与设计 2011年7期
毕 凯, 周 炜, 蒋玉娇, 安和平
(空军工程大学导弹学院,陕西三原713800)
0 引 言
Honeypot是一种安全资源,其价值体现在被探测、攻击或者摧毁的时候[1]。Honeypot是一个被严格控制的欺骗环境,由真实的或者软件模拟的网络和主机构成,但其系统中存在许多虚假的文件信息,用以实现对入侵者的诱骗。在诱骗环境中,我们可以收集入侵信息,观察入侵者行为,记录其活动,以便分析入侵者目的、手段、工具等信息。Honeynet是一种高交互的Honeypot系统,它提供了整个操作系统和软件,用于和入侵者进行交互。真实的环境,使诱骗系统更具有迷惑性,而高度的交互性,使得Honeynet非常适合捕获未知的入侵行为。
目前针对Honeynet的研究主要集中在其部署以及捕获入侵上,但在对捕获数据的分析方面还很薄弱。HoneynetProject对使用高交互度Honeypot进行数据分析所需的时间做过一次研究。根据他们的发现,对于攻击者花费在被黑系统上的每30分钟时间,若要对捕获数据加以较为详细的分析大约要花费40小时[1]。可见,数据分析已经成为影响甚至制约Heneynet快速发展的瓶颈。Kreibich等人提出了一种比较简单LCS(longest-common-substring)算法[2],但是提取的质量较差。Thakar通过可视化、统计分析等方法辅助人工筛选出可疑数据,然后采用LCS算法自动提取攻击特征[3]。Yegneswaran等人利用协议的语义实现从Honeynet数据中自动提取攻击特征[4]。本文提出了一种基于PCA和改进ReliefF算法的模式识别方法,用以分析Honeynet告警日志,并用实验证明了其可行性。
1 模型结构
Honeynet结构如图1所示,包括3个主要功能:数据控制,数据捕获,数据分析[1]。
数据控制是Honeynet必备的核心技术之一,它通过限制入侵者的行为,以保护Honeypot自身以及内部主机的安全。目前常用的数据控制方法有基于IPTables的外出连接数限制和snort-inline入侵防御系统。
数据捕获的目的是隐蔽的捕获入侵者的攻击行为,包括入侵者的身份、攻击的手段和工具以及在被黑主机上的操作等行为。Honeynet技术通常结合 Argus、Snort、p0f、Sebek 对攻击数据进行多层次捕获,以保证为数据分析提供丰富的资料。
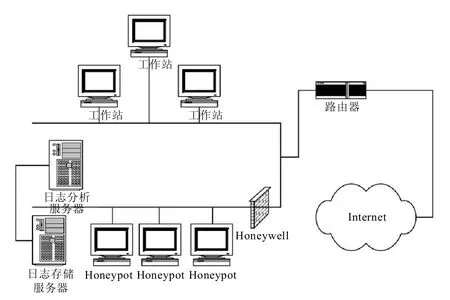
图1 Honeynet结构
针对捕获到的入侵行为高度复杂性的特点,提出了DAPR(dataanalyzebasedonPCAandReliefF)数据分析模型,如图2所示。

图2 DAPR数据分析模型
由于捕获的数据来自分别来自于防火墙、入侵检测系统和Honeypot,格式存在较大差异,因此我们首先需要进行数据融合,统一格式,以方便数据处理。我们将融合后的数据用n维向量(x1,x2,…,xn)表示,每个维度表示该数据的一个特征。
对于同一个入侵行为,在防火墙、入侵检测系统以及Honeypot都留有痕迹,这样不可避免造成大量数据的冗余。就是单一入侵行为,其不同特征之间,也存在相关性,这些数据的冗余性和相关性,给数据分类分析带来了不必要的工作量。我们利用基于PCA和改进的ReliefF的特征选择方法,对数据进行特征选择,降低数据维度,以减少分类的时间复杂度。而后利用SVM对入侵行为进行分类,判断攻击类型,生成报警信息。
2 改进的ReliefF算法
根据是否以分类精度作为评价函数,通常可以将特征选择方法分为两大类:过滤方法(filter)和封装方法(wrapper)[5],Relief算法是公认的效果较好的filter式特征评估算法[6]。
Relief算法是Kira和Rendell在1992年提出的,但是该算法主要用于解决二分类问题。1994年Kononenko扩展了Relief算法,并提出了ReliefF算法,将分类视为一类对多类关系,可以解决多类问题以及回归问题。
ReliefF算法根据特征值在区分临近样本点的能力上对特征赋予权值。首先将训练数据集D中各特征的权值赋0,然后随机选取样本X,在训练数据集D中找出与X同类的k个最近邻样本pj,j=1,2,…,k,分别从其余各类中找出X的k个最近邻样本 Mj(c),j=1,2,…,k,c=1,2,…,C 更新每一个特征,C 为样本类别总数,c≠c(X),c(X)表示样本X的类别。然后利用权值更新式(1)更新a的权值

式中:d(a,X,Y)——在特征a下,样本X和样本Y的距离;p(c)——c类目标的概率,可以简单记为Mj(c)——第c类目标的第j个样本;m——算法迭代次数,m和k可根据样本数量以及样本维数进行设定。而后反复执行迭代过程,直至满足迭代的次数要求。算法流程图如图3所示。

图3 ReliefF算法流程
但是,经典的ReliefF算法仍然存在不足之处:
(1)随机选取样本会使小类别被选中进行权值计算的概率小,有时可能完全被忽略[7];
(2)在无小类别参与的情形下,所得到的特征权值是不科学的,从而对分类精度产生一定负面影响。在Honeynet数据分析中,小样本往往具有潜在威胁的攻击,不能将其忽视[8]。
一种解决方案就是增加迭代的次数。因为每次迭代都要随机选择样本,在较多选择机会下,可以降低小样本被漏选的可能性。但是,这将大大增加系统的开销,降低时效性。
为解决上述问题,这里我们采用多次分类的方法。由于自动化攻击手段的广泛应用,Honeynet捕获的大部分攻击都是已知的和重复性的攻击。我们可以把所有的小样本作为一个整体,以扩大其在样本空间中所占比例,通过第一次分类,分离出绝大部分的入侵行为,并将其从分析数据源中剔除掉。这样单个小类别样本在样本整体中的比例将大大增加。针对余下的包含小类别和未知攻击的活动,进行再分类分析。我们可以根据实际需要设置合理的分类次数n或者直至符合分类精度要求。算法流程如图4所示。
3 主成分分析 (PCA)
ReliefF算法虽然能够进行特征选择,但其不能避免各特征之间存在的冗余现象。对于所有和类别相关性高的特征,算法都会赋予较高的权值,而不考虑特征之间的冗余性。
鉴于此,结合主成分分析方法(principle component analysis,PCA),去除特征之间的相关性,以达到简化算法复杂性的目的。

图4 多次分类流程
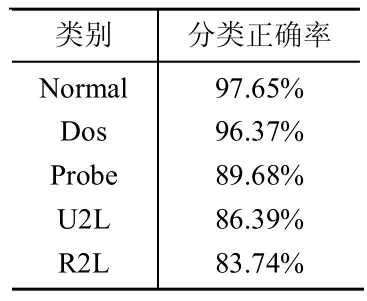
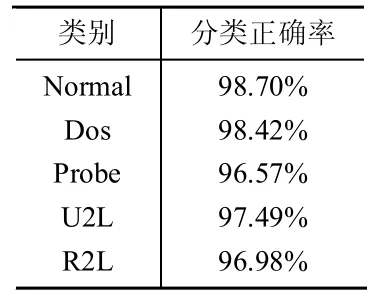
PCA,一种简化数据集的技术,为一种线性变换。这个变换把数据变换到一个新的坐标系中。对于一个n m的矩阵,PCA的目标是寻求r(r 设输入的数据矩阵 X∈Rmn已经按列零均值化或标准化,其中m为样本个数,n为特征向量个数。定义X的协方差矩阵为 正交分解,得 式中:D=diag(1,2,…,n)——i降序排列所构成的对角矩阵,Pn=[p1,p2,…,pn]——与特征值 相对应的特征矩阵,其中pi为特征值i所对应的特征向量。前k个主元所涵盖的测量变量的信息量可由前k个主元的方差贡献率来表示。若前m个主元的方差贡献率大于或等于某阈值Q(通常选取Q>85%),而前m-1个主元的方差贡献贡献率小于Q,则可令k=m,以此来确定符合条件的主元。当主元确定后,即可得主元模型 而原测量矩阵可以重构为 式中:X~——X 的残差,X~=TPTk,T——主元矩阵;Pk——负荷矩阵。 通过Rn—>Rk的线性变换,用包含X绝大部分信息的前k个特征向量构成的PCA子空间来代替X,以达到了特征提取和降低变量维数的目的。 本文所用的实验数据为KDD-CUP-99数据集。该数据集是哥伦比亚大学WenkeLee研究组为1999年举行的第三次国际KDD竞赛而提取的数据集,是对MIT98数据集提供的9周tcpdump数据进行了适当处理和特征提取。该数据集包括训练数据集和测试数据集两部分。其中训练数据集包括了500万个连接数据,测试数据集包括了200万个连接数据。其包括5类数据:normal数据,Probe攻击,DOS攻击,U2L攻击,R2L攻击。每个连接共有41种定性和定量的特征,其中有7个特征是离散型变量,34个特征是连续性变量。 首先,我们构造训练样本集。对于原始数据集,由于规模较大,我们随机选取其8057个数据记录,进行处理。经统计发现,Normal、DOS、Probe、R2L、U2L所占比例分别为51%、38%、6%、3%、2%,与实际情况基本相符。 然后,我们进行数据预处理。由于上述特征包括数字型和字符型,为了训练和测试所设计的分析系统,需要对原始数据进行预处理。首先将特征中的字符型数据做数据化处理,即为每个字符进行十进制编码。而后对这些特征的取值范围进行规范,控制其取值范围在[0,1]中。一些字符属性如protocol_type(3 个不同的标记)、flag(11 个不同的标记)、service(70个不同的标记)都将各符号映射到0和N-1之间,N为标记的个数。然后再将其映射到[0,1]区间内。连续的数值型数据也按比例缩映到[0,1]。其它属性要么是逻辑值,其值为1或0,要么是在[0,1]范围内的连续数据,不需要进行预处理。这样预处理的优点主要在于:一方面可以均衡不同取值范围的特征,避免取值范围大的特征支配那些取值范围小的特征;另一方面可以提取算法的运行效率。 在选取的数据集中,我们发现第9、15、20、21属性值全为0,对于分类分析没有意义,可以将其设为0,剩余37个属性。 对于本数据集,由于只包含5种类别,且小类别数量差异较小,我们令n=2,m=10。下面将处理好的数据进行主成分分析,结果如表1表示。 表1 主成分分析结果 在特征贡献率Q≥85%的基础上,我们选取前12个属性。 利用改进的ReliefF算法,对经过PCA简化的数据集进行特征选择。权值如表2所示。 选取8个权值最大的属性用于分类,结果如表3所示。 由表3可见,经过第一次分类,可以以较高的正确率最常见的Normal和Dos行为检测出来。而对于Probe、U2L、R2L,由于在训练数据集中,所占比例偏小,分类正确率偏低。 将检测出的Normal、Dos数据剔除,对余下的小样本数据进行第二次特征选择以及分类,综合两次分类,结果如表4所示。 表2 特征权值 表3 首次分类结果 由表4可以看到,经过第二次的分类,精度较第一次分类显著提高,能够将各种行为区分开来。 表4 再次分类结果 由实验我们可以看到,经过特征提取和特征选择,对数据属性进行约减,去除冗余和与分类无关的属性,能够在保证分类精度的基础上有效简化计算的时间和空间的复杂性,提高数据分析的效率。 本文针对蜜罐中分析系统的不足,提出了基于PCA和改进ReliefF算法的告警日志分析方法,通过特征提取和特征选择,在保证分类精度的基础上,减少数据属性的冗余性和无用性,有效简化了数据分析的规模。通过多次、不断细化的分类操作,可以将网络攻击中不常见的小类别攻击方式从大量的攻击中较为准确的提取出来,这些小类别的攻击行为,往往是我们了解较少,具有巨大潜在威胁的攻击行为。然而对于特征选择和分类的次数,要视分析数据的规模和特性等情况给出,没有一个较易得到的方法,这将成为今后研究中解决的一个问题。 [1]The honeynet project:know your enemy:honeynets[DB/OL].http://www.Honeynet.org/papers/honeynet/,2005. [2]Kreibich C,Crowcroft J.Honeycomb:creating intrusion detection signatures using honeypots[J].ACM SIGCOMM Computer Communication Review,2004,34(1):51-56. [3]Urjita Thakar.HoneyAnalyzer:analysis and extraction of intrusion detection patterns&signatures using honeypot[C].Dubai,UAE:The 2nd Int'l Conf on Innovations in Information Technology,2005. [4]Yegneswaran.An architecture for generation semanties-aware signatures[C].Baltimore,MD:Usenix Security Symposium,2005. [5]Liu Y,Zheng Y.F1 FS_SFS:A novel feature selection method for support vector machines[J].Pattern Recognition,2006,39(7):1333-1345. [6]张丽新,王家钦,赵雁南,等.基于Relief的组合式特征选择[J].复旦学报(自然科学版),2004,43(5):893-898. [7]吴艳文,胡学钢,陈效军.基于Relief算法的特征选择学习聚类[J].合肥学院学报(自然科学版),2008,18(2):45-48. [8]吴浩苗,尹中航,孙富春.Relief算法在笔迹识别中的应用[J].计算机应用,2006,22(1):174-177.



4 实 验


5 结束语
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
民族古籍研究(2018年1期)2018-05-21
自动化学报(2017年5期)2017-05-14
自动化学报(2017年7期)2017-04-18
电子制作(2017年23期)2017-02-02
西夏学(2016年2期)2016-10-26
智能系统学报(2015年4期)2015-12-27
浙江大学学报(工学版)(2015年1期)2015-03-01
中国中医药现代远程教育(2014年16期)2014-03-01
