
基于聚类和用户点击的在线多样化排序算法*
2011-08-02 05:51马千里林古立
华南理工大学学报(自然科学版) 2011年12期
马千里 林古立
(华南理工大学计算机科学与工程学院,广东广州510006)
互联网信息检索系统的一个核心问题是如何对检索得到的文档根据用户提交的查询进行排序以满足用户的需求[1].因此,排序算法的研究一直是信息检索领域的一个重要研究方向.现有的大多数互联网信息检索系统,无论是采用基于文档内容的相关度计算[2],还是基于链接分析[3]的排序方法,抑或是近几年兴起的排序学习方法[4],它们在对结果文档进行排序时通常都是根据概率排序原则[5]按照估计出来的文档与查询的相关度从大到小进行排序,以期望获得最好的检索性能.然而,随着信息检索研究的不断深入,越来越多的研究结果[6-8]表明,现有的基于概率排序原则的排序方法无法满足用户的多样化需求.
信息检索排序中的多样化需求主要源于两方面[9]:一是用户查询的不确定性,例如查询词有多义性,存在多种解释,搜索引擎无法确定用户的需求;二是用户查询所涉及的信息面可能较广,包含多个方面的内容,单个文档无法满足用户的需求.例如,查询词“Java”,既可以表示一种编程语言、也可以表示印尼的爪哇岛,这就是查询意图的不确定性;而即使查询词是“Java编程”,那也包含了很多方面的内容,例如与Java编程相关的书、源代码或者软件等.在这些情况下,信息检索系统在对检索结果进行排序时,必须挖掘用户查询所蕴含的各种潜在意图,在结果列表靠前的位置尽可能地提供满足用户各种需求的检索结果.
现有的多样化排序方法[10-12]大多采用启发式的方法,把多样化排序问题看作是文档的查询相关度与文档间的相似性的线性组合优化问题进行求解.这类相对静态的方法是从系统的角度对用户意图进行挖掘,无法真正把握用户的查询意图.Radlinski等[13]提出了一种基于在线学习的多样化排序算法RBA,通过与用户进行交互,从用户的点击中捕捉用户的查询意图,从而调整结果文档的排序,提高用户的满意度.但RBA算法需要将待排序的所有文档逐个进行选择,当结果文档数量较大时,RBA算法的收敛速度很慢,早期难以满意用户的多样化需求.针对这个问题,文中在RBA算法的基础上,利用文档之间的相似性,提出了一个基于聚类和用户点击的在线多样化排序算法CRBA(Cluster-Based Ranked Bandit Algorithm).该算法首先对候选网页文档进行主题聚类,接着选择类别中的文档形成排序列表,然后根据用户的反馈进行在线学习,动态调整类别的排列顺序以及类别内文档的选择,以更好地满足用户的多样化需求.
1 CRBA算法描述
CRBA算法的目标是解决这样的问题:给定一个查询及其候选文档集合D={d1,d2,…,dn},算法通过不断的学习得到一个包含k个文档的多样化排序列表,以满足各种不同的用户需求.假设存在一个用户群体,其中每一个用户ui都觉得D中的一个文档子集Ai是与其查询意图相关的,而剩下的其它文档则是不相关的.直观来看,抱有不同意图的用户所对应的相关文档子集是不同的,而抱有类似意图的用户所对应的相关文档子集则应该是类似的.在时刻t,CRBA算法将提供给用户ut一个排好序的k个文档列表Bt={b1(t),b2(t),…,bk(t)}.假设用户将会从头至尾按顺序浏览这k个文档,在浏览过程中,用户如果发现相关的文档,就会进行点击,然后停止浏览行为.这里假设用户点击相关文档的概率为1,即只要是相关文档就会进行点击.CRBA算法的目标是最大化从时刻1开始的整个过程的用户点击率,较高的点击率表示较多的用户点击了CRBA算法提供的文档列表,从文档列表中找到了相关的文档,也就是说,CRBA算法满足了较多用户的需求.
CRBA算法建立在多臂赌博机(MAB)[14]算法的基础上.MAB是一类决策优化问题:一个拥有K个臂的投币机器,赌博者在某一时刻从这K个臂中选择一个臂进行拉动来获得回报,这个回报可能是正值、零或者负值,一次拉动获得一个回报.在某一时刻,赌博者只能操作一个臂,目的是使赌博者的回报总和最大.将该问题对应到多样化排序中,可以把候选文档看成臂,用户的点击作为回报.RBA算法正是基于这一点,通过构建多个MAB实例实现多样化排序.与RBA算法不同的是,笔者提出的CRBA算法采用了两层MAB实例结构,一层用于选择文档类别,另一层用于选择类别内的文档.这样做的好处是可以先利用文档聚类将待排序文档进行一个简单的划分,在此基础上利用用户点击捕捉不同类别文档满足用户的需求程度,相比RBA算法,CRBA算法可以大大减少不必要的用户交互,从而提高早期的用户满意度.
CRBA算法包含4个输入参数:查询词q、候选文档集合D、用户浏览范围k(即前k个文档)和时刻s.CRBA算法的输出为到时刻s为止的用户点击率r,即有多大比例的用户对排序结果进行了点击.CRBA算法中的h是指MAB实例的一个臂,p是指该MAB实例获得的回报,MAB实例会根据回报调整各个臂的权重,以更新下一次选择各个臂的概率.CRBA算法的具体描述如下.
输入参数:q,D,k,s
输出参数:r
对D进行主题聚类得到m类,记为C1,C2,…,Cm
初始化 MAB1(m),MAB2(m),…,MABk(m);对于每一个类别Cj(j∈[1,m]),初始化对应的
fort=1 tosdo
fori=1 tokdo∥选择前k个文档供用户浏览c'i(t)=select-arm(MABi)∥选择类别
ifc'i(t)∈{c1(t),c2(t),…,ci-1(t)}ci(t)=任意类别∉{c1(t),c2(t),…,ci-1(t)}
else
ci(t)=c'i(t)
end if
ifb'i(t)∈{b1(t),b2(t),…,bi-1(t)}
bi(t)=任意文档∉{b1(t),b2(t),…,bi-1(t)}
else
bi(t)=b'i(t)
end if
end for
展示{b1(t),b2(t),…,bk(t)}给用户,记录用户点击
应该说,“首都餐饮业品质提升工作”是北京市餐饮业以习近平总书记关于食品安全系列讲话精神为指导,全面实施国家市场监管总局提出的《餐饮服务食品安全操作规范》的自律表现,是继北京餐饮业实现“明厨亮灶”、“阳光餐饮”后的一次全面提升,是为迎接2022年冬奥会打造餐饮业的首都标准、北京品牌,使北京餐饮业成为彰显首都文化魅力、良好生态环境、和谐文明社会、安定富裕生活的载体,成为体现首都城市内在品质的亮丽名片,在全国餐饮行业中做出了表率。下一步,中国烹饪协会将在北京市市场监督管理局的指导下,继续深入落实“首都餐饮业品质提升工作”,力争取得更大的成效,惠及更多的企业和消费者。
fori=1 tokdo
if用户点击了bi(t)&&ci(t) ==c'i(t)&&bi(t)==b'i(t)
update(MABi,h=c'i(t),p=1)
update(MABc'i(t),h=b'i(t)对应的臂,p=1)
break
end if
end for
end for
CRBA算法主要分为两个部分:
(1)初始化.对于给定查询词q,算法先对其候选文档集合D进行聚类,获得聚类结果C1,C2,…,Cm,每个类别包含的文档集合分别为Dc1,Dc2,…,Dcm.接着,算法初始化多个MAB实例,包括k个用来选择类别的含有m个臂的MAB实例(用MABi表示),和m个用来选择类别中的文档的MAB实例(用MABcj表示,这m个MAB实例的臂的数量等于对应类别的文档数).每个MABi都维护着每个类别的一个值,用于选择类别;而每个MABcj也维护着该类别下面每个文档的一个值,用于选择文档.
(2)交互排序.算法从时刻t=1开始,在每个时刻,都有一位用户提交查询词q,算法则会选择一个包含k个文档的排序列表给用户.然后用户浏览排序列表,根据文档相关性决定是否进行点击,算法会根据用户的点击对MAB实例进行更新操作,这样算法就完成了与用户的一次交互过程.此过程不断重复直至时刻s.
在整个交互排序的过程中,CRBA算法对文档的排序分两个阶段进行,每个阶段对应一层的MAB实例.首先是选择文档的类别,每个排序位置i对应一个选择出的实例MABi.选择类别时,从MABi中根据臂的概率随机选择一个臂c'i(t),如果该臂对应的文档类别尚未在位置i之前被选中过,则选择该类别作为排序位置i对应的类别ci(t),否则随机选择一个未被选过的类别对应排序位置i.然后是类别内文档的选择,从排序位置i对应的类别ci(t)所对应的MAB实例MABci(t)中随机选择一个臂b'i(t),如果该臂对应的文档尚未在位置i之前被选中过,则选择该文档作为排序位置i上的文档bi(t),否则随机选择一个未被选过的文档放在排序位置i上.这个过程持续到选好k个文档为止.
而当CRBA算法把k个文档呈现给用户之后,用户按顺序浏览k个文档直到他看到相关的文档并进行点击,至此整个查询过程完成;如果没有看到任何相关文档,用户将不进行点击,查询过程结束.接着,CRBA算法会根据用户点击对MAB实例的参数进行更新.假设用户点击了排序位置为i的文档bi(t),如果该排序位置的类别是由MABi选择的,即ci(t)==c'i(t),且该文档是由用MABci(t)选定的文档,即bi(t)==b'i(t),那么该文档对应的MABci(t)中的臂获得回报1,MABi中的臂ci(t)获得回报1,其它臂获得回报0.根据所获得的回报,函数update更新各个MAB实例中臂的权重,以便进行下一次排序.
在CRBA算法中,MAB算法是关键所在,它必须在保持用户点击率的同时,尝试选择其它类别或者文档供用户选择,以了解用户对更多类别或文档的喜好,据此调整类别和文档的排序,以得到更高的点击率.此外,由于采用了多个MAB实例,排序位置i上的文档的回报会受到该位置之前的文档的影响,故其回报不服从一定的概率分布,因此,采用文献[15]提出的Exp3算法作为MAB算法实例.
2 实验与分析
2.1 模拟数据分析
模拟数据集由用户模型和文档构建,用户模型采用CRP[16]进行生成,把用户和子主题(用户潜在意图)对应起来,即哪些用户与给定主题的哪些子主题相关.与文献[13]一样,实验时选择生成20个用户,设置CRP的参数θ为3,这样生成的数据集的平均子主题数为6.5,每个子主题上的用户数呈幂级递减.对于每一个主题,当用户和子主题的对应关系生成后,再生成一定数量的文档,并随机把文档按比例分配到各个子主题中.文档的分配与子主题所包含的用户数相关,用户数越多,文档就越多.最后,设置每个用户与他所相关的子主题下的所有文档都相关,而与其它文档则不相关.模拟数据集总共包含100个主题.
排序算法的结果通过用户点击率进行评价,即从时刻1开始到时刻t,有多大比例的用户点击了排序列表.在模拟数据的实验中,用户查询次数设置为300000次.一般来说,现实中查询次数在50000以上的就算常用查询词了,设置300000次是为了考察算法的性能变化趋势.实验时,在每一个时刻(每一次查询),随机抽取用户对排序结果进行查看和点击,并记录用户点击率,最后记录算法排序结果在100个主题上的平均用户点击率.
在第1个实验中,与文献[13]一样,设置生成的给定主题对应的候选文档数为50.在这个实验中,CRBA算法所采用的聚类是最优聚类,即所有聚类结果完全与子主题分配一致,其目的是想通过实验验证CRBA算法在聚类效果最优情况下的表现.实验结果如图1所示.从图1中可以看到,CRBA和RBA算法的平均用户点击率都远远高于下界OPT(OPT表示最优排序结果所取得的点击率),而且两个算法的性能都随着用户查询次数的增加而逐渐提高.但CRBA算法的结果很快就逐渐地逼近最优排序的结果了,而RBA算法的收敛速度明显比基于最优聚类的CRBA算法要慢得多,在时刻300 000的平均用户点击率还远没有达到CRBA算法在时刻50000的平均用户点击率.由此可知,在获得最优聚类结果的条件下,CRBA算法可以迅速地逼近最优排序的结果,相比RBA算法具有明显的优势.
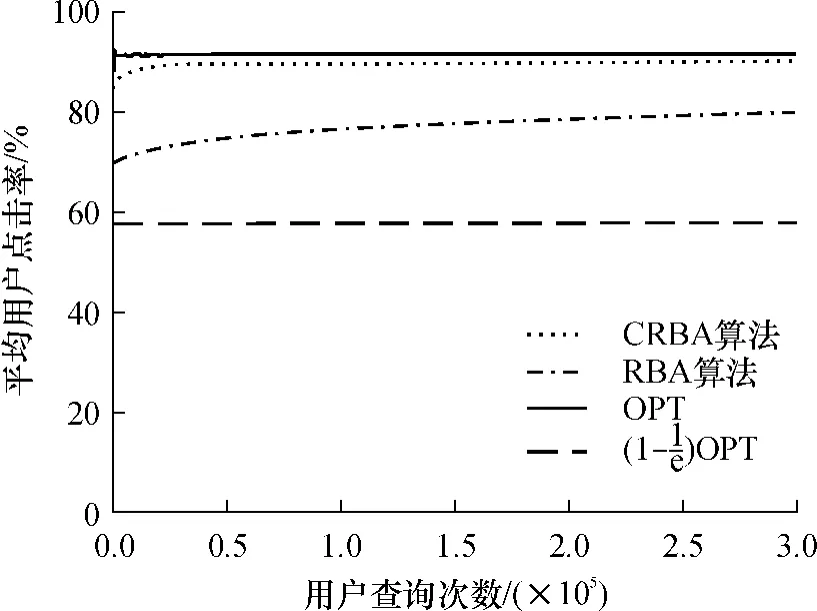
图1 算法RBA和CRBA在文档数量为50的虚拟数据集上的平均用户点击率Fig.1 Average user click rates of algorithms RBA and CRBA on a simulated dataset with 50 documents
第2个实验考察数据集文档数对两种算法的影响.为此,实验中构建了4个文档数不同的数据集.4个数据集采用相同的主题和用户模型,但文档数分别是20、30、50和100.也就是说,4个数据集中的主题及其子主题,还有子主题与用户的相关关系都是一样的,不同的只是候选文档的数量和分配到各个子主题的数量.实验中CRBA算法依旧采用最优的聚类结果.实验结果如图2所示,CRBA算法在4个数据集上的表现几乎完全一致,说明在类别没有变化的情况下,类别内部文档数量的大小对CRBA算法没有影响.而RBA算法则明显受到文档数量的影响,当文档数逐渐增大时,RBA算法的收敛速度也逐渐变慢.从这一点看,CRBA算法比RBA算法更具有实用价值.因为在互联网搜索的现实情况中,候选文档集的数量往往很大,类别个数往往比文档数小得多,此时,基于主题聚类的CRBA算法就能够减少不必要的用户交互次数,快速地获得让用户满意的排序结果.
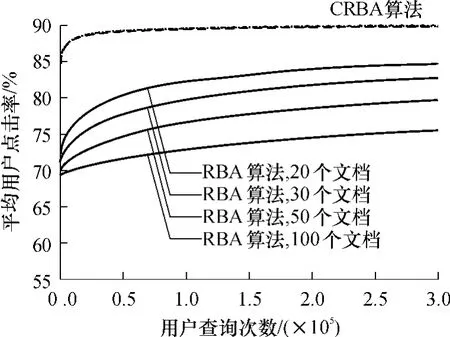
图2 算法RBA和CRBA在文档数量分别为20、30、50和100的虚拟数据集上的平均用户点击率Fig.2 Average user click rates of algorithms RBA and CRBA on simulated datasets with 20,30,50 and 100 documents
2.2 公开数据集实验分析
为进一步考察CRBA算法在实际应用中的有效性,在一个公开的数据集AMBIENT(AMBIgous ENTries)上进行实验,并采用现有的聚类算法对文档进行聚类.
AMBIENT 数据集(http://credo.fub.it/ambient)是一个用于子主题检索评价的公开数据集.它总共包含44个主题,每个主题包含一个子主题集合和100个排好序的文档.主题和子主题是从Wikipedia(http://en.wikipedia.org/wiki/Wikipedia:Links_to_%28disambiguation%29_pages)上获取的,而结果文档是以主题名作为查询词从Yahoo!搜索引擎获取的,并且根据Wikipedia上列出的每个主题对应的子主题信息,人工进行子主题相关性的标记.每个文档由搜索结果的URL、标题和页面文摘组成.更多的关于该数据集的信息可以参考文献[17].
在用户模型方面,仍然采用20个用户,且采用基于文档占比的用户模型,即与子主题相关的用户数跟该子主题所包含的文档数相关,文档数多的用户就多.
实验中采用k-means聚类算法作为CRBA算法中的聚类算法,聚类目标个数设置为10.为了验证CRBA算法的有效性,除了与RBA算法进行比较之外,还加上了经典的多样化排序算法MMR[10],文档的查询相关度用BM25进行计算.
算法的性能依然采用平均用户点击率进行评估,是在数据集所有44个主题上的用户点击率的平均值.实验结果如图3所示.由图3可见:MMR算法的平均用户点击率随着用户查询次数的增多,基本呈现稳定的状态,主要是由于其排序结果是不变的;而两种在线排序算法RBA和CRBA的性能都随着用户查询次数的增多而提高.这说明,随着跟用户的不断交互,在线算法可以逐渐获得对用户意图更为准确的估计,从而提高了用户的满意度.而CRBA算法的收敛速度明显比RBA算法要快,因此可以大大缩短与用户的交互次数,从而在早期也能较好地满足用户的需求.
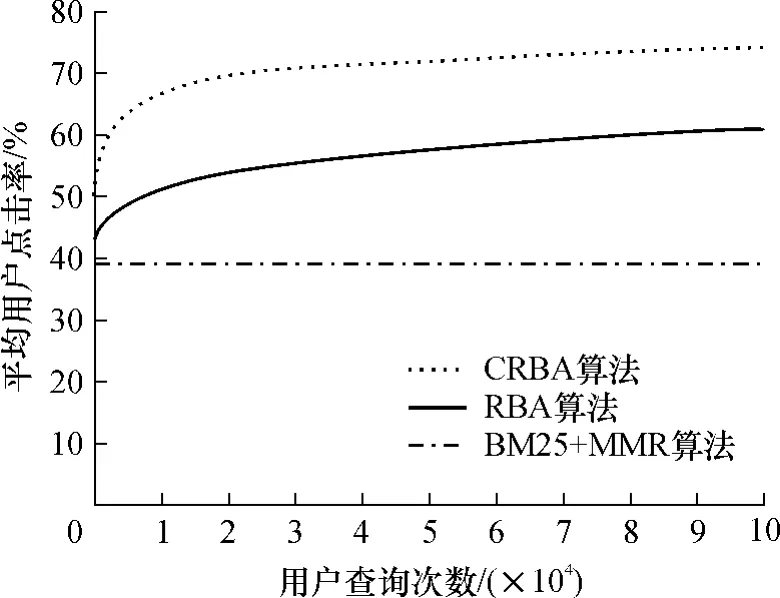
图3 3种算法在AMBIENT数据集上的平均用户点击率Fig.3 Average user click rates of three algorithms on AMBIENT dataset
3 结语
文中提出了一种基于聚类和用户点击的在线多样化排序算法CRBA,它既可以利用主题聚类的优点,根据主题对候选文档集合进行简单的划分,从而大大加快收敛算法的收敛速度,又能发挥在线排序算法的优点,利用用户点击反馈,获得对用户意图更为准确和完整的估计,为用户提供多样化的排序结果.实验结果表明,CRBA算法比其它在线排序算法收敛更快,且更能适应现实搜索环境中文档数量大的特点.
[1]Baeza-Yates R,Ribeiro-Neto B.现代信息检索[M].王知津,贾福新,郑红军,等,译.北京:机械工业出版社,2005.
[2]马晖男,吴江宁,潘东华.一种修正的向量空间模型在信息检索中的应用[J].哈尔滨工业大学学报,2008,40(4):666-669.Ma Hui-nan,Wu Jiang-ning,Pan Dong-hua.Application of a modified vector space model in textual information retrieval systems[J].Journal of Harbin Institute of Technology,2008,40(4):666-669.
[3]Page L,Brin S,Motwani R,et al.The pagerank citation ranking:bring order to the Web[R].Stanford:Stanford InfoLab,1998.
[4]孙鹤立,冯博琴,黄健斌,等.序关系优化的多超平面排序学习模型[J].模式识别与人工智能,2010,23(3):327-334.Sun He-li,Feng Bo-qin,Huang Jian-bin,et al.Ranking model of optimized multiple hyperplanes using order relations[J].Pattern Recognition and Artificial Intelligence,2010,23(3):327-334.
[5]Robertson S E.The probability ranking principle in IR[J].Journal of Documentation,1977,33(4):294-304.
[6]Yue Y,Joachims T.Predicting diverse subsets using structural SVMs[C]∥Proceedings of the 25th International Conference on Machine Learning.New York:ACM,2008:1224-1231.
[7]Santos R L T,Peng J,Macdonald C,et al.Explicit search result diversification through sub-queries[C]∥Proceedings of the 32nd European Conference on IR Research.New York:ACM,2010:87-99.
[8]Santos R L T,Macdonald C,Ounis I.Exploiting query reformulations for Web search result diversification[C]∥Proceedings of the 19th International Conference on World Wide Web.New York:ACM,2010:881-890.
[9]Radlinski F,Bennett P N,Carterette B,et al.Redundancy,diversity and interdependent document relevance[J].ACM SIGIR Forum,2009,43(2):46-52.
[10]Carbonell J,Goldstein J.The use of MMR,diversitybased reranking for reordering documents and producing summaries[C]∥Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM,1998:335-336.
[11]Zhai C X,Cohen W,Lafferty J.Beyond independent relevance:methods and evaluation metrics for subtopic retrieval[C]∥Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM,2003:10-17.
[12]林古立,彭宏,马千里,等.一种基于关键词的网页搜索结果多样化方法[J].华南理工大学学报:自然科学版,2010,39(5):102-107.Lin Gu-li,Peng Hong,Ma Qian-li,et al.A keywordbased method for diversification of Web search results[J].Journal of South China University of Technology:Natural Science Edition,2010,39(5):102-107.
[13]Radlinski F,Kleinberg R,Joachims T.Learning diverse rankings with multi-armed bandits[C]∥Proceedings of the 25th International Conference on Machine Learning.New York:ACM,2008:784-791.
[14]Cesa-Bianchi N,LugosiG.Prediction,learning,and games[M].New York:Cambridge University Press,2006.
[15]Auer P,Cesa-Bianchi N,Freund Y,et al.The nonstochastic multiarmed bandit problem[J].SIAM Journal on Computing,2002,32(1):48-77.
[16]Durrett R.Probability models for DNA sequence evolution[M].2nd ed.New York:Springer,2008.
[17]Carpineto C,Mizzaro S,Romano G,et al.Mobile information retrieval with search results clustering:prototypes and evaluations[J].Journal of American Society for Information Science and Technology,2009,60(5):877-895.
猜你喜欢
民族古籍研究(2018年1期)2018-05-21
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
海峡姐妹(2015年8期)2015-02-27
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中国中医药现代远程教育(2014年16期)2014-03-01
海外英语(2013年3期)2013-08-27
