
Excel在水质监测数据处理及评价中的应用研究
2011-07-09 06:53杨艳艳薛庆云
浙江水利科技 2011年5期
杨艳艳,薛庆云,朱 江
(杭州市水文水资源监测总站,浙江 杭州 310016)
1 Excel取代计算器作为原始数据处理工具
1.1 传统方法的弊端
从事一线水质分析人员较为头痛的就是在样品越来越多的情况下,计算各类原始数据的繁琐。传统方法是运用计算器来计算结果,有固定的原始记录表格,如滴定法要按照计算公式出结果,分光光度法需要在回归曲线的基础上出结果,所有数据手工逐个计算、输入和输出,而且碰到小于检出限的时候还要进行判断后计为“<DL”,当每次需要计算的项目和样品都很多的时候,出错的概率就会增加,而且校核和审核人员负担也重。
1.2 Excel实现原始数据的分析处理
运用Excel表来实现以上数据处理,只需要将程序按照每个项目的原始记录格式一次性的编制好表格,确定“输入列”和 “输出列”,并用颜色标示。这里分别例举了高锰酸盐指数和总磷来分别代表容量法和分光光度法进行数据处理分析,其余项目雷同。
1.2.1 高锰酸盐指数数据处理
高锰酸盐指数的原始记录计算,依据酸性高锰酸钾法(GB 11892—89《水质 高锰酸盐指数的测定》)[1]的分析计算公式,通过键入 “=”编辑公式和算术运算符完成 (见表1)。

表1 高锰酸盐指数原始记录运算表[2]
如表1所示,输入项即分取水样体积(F4∶F9)、K值(I4)以及由滴定分析出的终点 (C4∶C9,C66∶C69)和始点(D4∶D9,D66∶D69)用量;输出项即需要在原始记录表里填写的中间成果 (E4∶E9,E66∶E69,F66∶F69,G66,H66,I66)和最终成果(J4∶J9),根据计算方法分别由加减乘除公式组成;最终结果J4可以计算为 “=(((10+E4)*I4-10)-((10+H4)*I4-10)*G4)*80/F4”[1], 回车得到需要的含量。
需注意的是,公式编辑好需经过一系列验证,而后每次运算就可直接输入输入项数据,索取输出项的运算结果,样品多可以在中间行多插入几行,再将公式整体下拉即可,但是下拉公式如果引用某固定单元格时,需要采用绝对引用,即在行和列前加“$”符号。
1.2.2 总磷为代表的分光光度计算程序
总磷的原始记录计算依据钼酸铵分光光度法(GB 11893—89)[3]进行,对标准系列建立“X浓度—Y吸光度”回归曲线,通过散点图、直线相关分析、直线回归分析完成曲线的相关性分析和含量的计算(见表2)。

表2 总磷原始记录运算表[2]
如表2所示,按照总磷的原始记录设计了分光光度法的分析计算表格,输入项为 (D11:K12,F19:G24,K21:K24),输出项为(D13:K13,A15:D15,H19:J24)。对行11、13求回归曲线,先进行回归图分析,选取表格中的散点图,选取这些正态分布的点系列添加直线回归趋势线,并显示截距和相关系数的平方值;若参与计算,则可直接通过函数实现,其中相关系数r的结果A15处可通过函数得到,即 “=SQRT(RSQ(D11:K11,D13:K13))”,取绝对值;斜率 a的结果 C15处通过函数 “=SLOPE(D13:K13,D11:K11)”得到,截距b的结果D15通过函数“=INTERCEPT(D13:K13,D11:K11)” 得到。针对J列含量结果,根据 “C=(A-b)/a”、算术运算公式,并结合检出限,得出J21处含量为 “=IF((H21-$D$15)/$C$15*25/K21*2<$K$7, “<DL”,(H21-$D$15)/$C$15*25/K21*2)”[3]。
该分光光度法计算可同时运用插入散点图并添加趋势线、函数RSQ(返回根据known_y′s和 known_x′s中数据点计算得出的 Pearson乘积矩相关系数的平方)、SQRT(绝对值)、SLOPE(返回根据 known_y′s和 known_x′s中的数据点拟合的线性回归直线的斜率)、INTERCEPT(利用现有的x值与y值计算直线与y轴的截距)[4];当含量结果有最低限制要求即检出限限制时,需要结合IF语句,并把符合条件的直接输出为“<DL”,否则直接返回计算结果的数值;另外公式也涉及到$绝对引用。
2 运用Excel自动评价
水质各项数据在原始记录计算的基础上,需要手工录入表格形成月报和年报,并对其进行单项和综合评价,在大量的站点和项目面前,手工评价过程的效率和质量都很难保证,以下介绍运用Excel表格函数对地表水水质监测结果进行自动单项类别评价、综合评价及湖库富营养化评价分析研究。
2.1 单项水质类别评价
对于该项评价,主要是运用了“IF叠加语句”,评价依据为GB 3838—2002《地表水环境质量标准》,并可以通过2种形式实现。2种单项评价的原理是一样的,不同的是,当IF判别的时候,将判别标准直接输入还是自动引用。前提是以固定格式将数据原值列入表 “评价数值汇总”中(见表3)。

表3 监测结果原值表
首先是直接输入判别标准,对应 “IF公式自动评价”表,以 E6位置CODMn为例 (见表4),当 (IF)CODmn数值处为空缺时,评价位置也是空;当出现小于检出限(<DL)的时候,默认为最好水质I类;当结果≤2的时候,水质为I类,当……,以此类推,超过V类的情况视为劣V类。此类评价简单易懂,一目了然,但是要每个项目列编一程序,繁琐。

表4 IF语句单项自动评价表
其次是引用自动评价判别标准的IF判别语句(见表5),先建立1个 “自动评价判别标准表”,即按照 “评价数值汇总”一栏的表头格式一一对应。
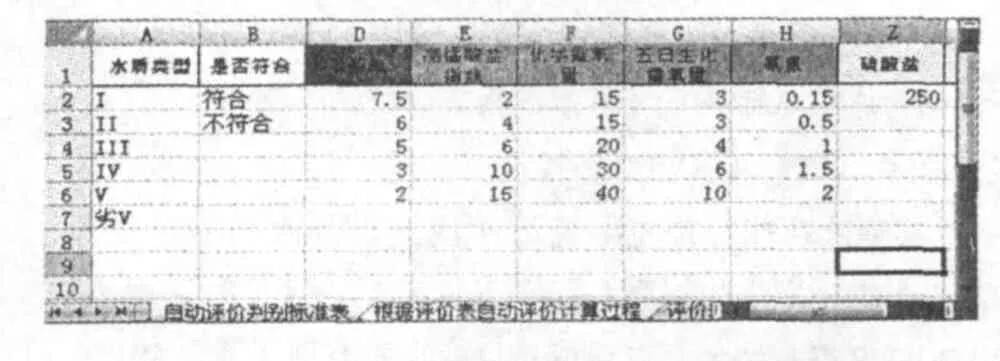
表5 自动评价标准判别表[5]
然后在另一张 “根据自动评价表自动评价计算过程”表里进行IF语句编程,仍以E6位置的CODMn为例 (见表6),IF语句里I~V类之间的标准值就直接索引 “自动评价判别标准表”里的标准值即可,只要编制第1行第1列的单项评价,即可横向纵向下拉。
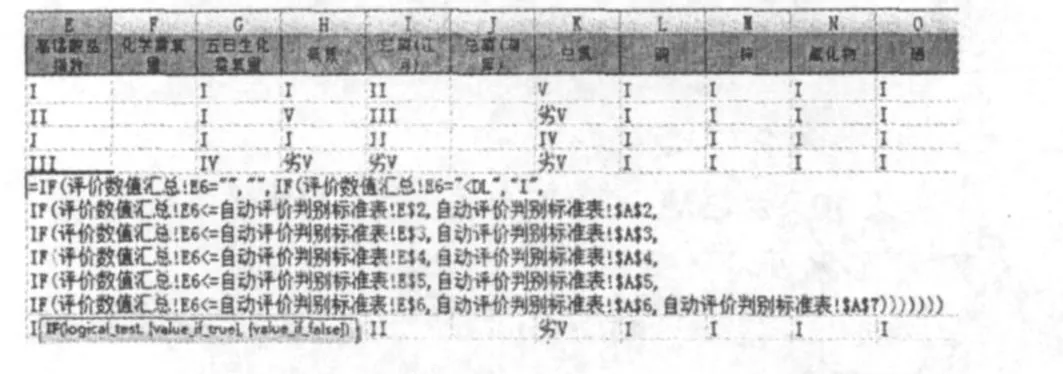
表6 通过引用标准表的IF语句单项自动评价表
需注意的是,原值、标准值和评价值的sheet表里,表头所在的行列一定要一一对应;要特别注意特殊项目pH值、溶解氧和集中式饮用水源地补充项目的评价差异性和特殊性;判断次序:空白—<DL—标准类别。
2.2 综合水质评价
综合评价包括综合评价类别、超标项目以及超标倍数的计算。根据水资源公报的需求,每年评价结果中的超标项目需要按照超标倍数由大到小排列,且需要列出超标项目的极值,表现形式为 “超标项目 (超标倍数)[极值]”。该项内容以年均值为例,同时介绍以上功能函数。
2.2.1 综合水质类别评价
综合评价过程运用到函数IF语句和求极值MAX函数。将单项评价类别的罗马数字“I~劣V类”分别运用IF函数替换成阿拉伯数字的1~6(见表7),然后根据单因子评价原理,对每个站点全部项目最大值化,得到的数字再通过IF语句替换回罗马数字,即得到综合评价结果(见表8)。

表7 单项评价结果替换成数字程序表

表8 综合评价结果替换成类别程序表

表9 水功能区目标类别表

表10 函数VLOOKUP自动查找目标水质类别表
2.2.2.2 函数MAX建立极值表
将每个站点的全年极值通过MAX函数计算结果,列入“极值表”,与 “评价数值汇总”表保持统一站名,统一表头,统一位置,以保证索引极值时不出错。
2.2.2.3 判别和计算超标项目和倍数
利用IF语句对每个站点的每个项目进行逐个计算超标倍数,如表11里J4所示,索引“评价数值汇总”里的原值和“自动评价判别标准表”的标准,如果单项原值评价类别大于目标水质类别,则超标,计算超标倍数,否则均为空。

表11 单项超标倍数判别与计算表

表12 运用数组公式格式化超标项目表
其中函数 “LARGE($C2:$AD2,AJ$1),” 意为找出C2~AD2中第AJ1大的结果,因AJ1为1,即为第1大的结果;而函数 “SUM(IF($C2:$AD2=LARGE($C2:$AD2,AJ$1),COLUMN($C2:$AD2)))” 意为如果C2~AD2之间有等于C2~AD2序列里第1大结果的,返回为该列列号,否则就返回FALSE,计为0,得到这样一个已找到的列号和0组成数组,然后用SUM对该数组求和,结果就是C2~AD2里超标倍数最大的数值所在的列号(氨氮列)。同理,上表中SUM所求的结果就是C2~AD2里超标倍数第2大的数值所在的列号。而函数 “INDEX($A$1:$AD$1,1,SUM(IF($C2:$AD2=LARGE($C2:$AD2,AJ$1),COLUMN($C2: $AD2))))” 即 为“INDEX($A$1:$AD$1,1,氨氮列)”,意为返回成第1行氨氮列的结果,即为 “氨氮”2个字。而函数TEXT(LARGE($C2:$AD2,AJ$1),” #0.00”)意为返回 C2~AD2里超标倍数最大的数值,且该数值保留2位小数位数;函数 “INDEX(单站极值!$A$1:$AH$806,ROW(),SUM(IF($C2:$AD2=LAR GE($C2:$AD2,AJ$1),COLU MN($C2:$AD2))))”,同理意为返回单站极值表里的本行 (2)氨氮列的数值,即为氨氮的极值;最后AJ2的公式可以概括为,当AJ1(1)<=AI2(3)时,该位置显示 “本行最大结果列(氨氮列)的第1行结果”&“(”&“本行氨氮列保留2位的数值”&“)[”&“单站极值表里的本行、氨氮列的数值”&“]”,显示出来就是“氨氮(0.58) [0.39]”。其中 AI2超标个数运用了函数 “=COUNTIF(C2:AD2,” >0”)”, 意为 C2~ AD2里>0结果的个数,即为超标个数。
但是需要明确的是,以上复杂函数运用了SUM+IF数组公式,编辑好以后的公式需要“ctrl+shift+enter”结束,而不是常规的 “enter”。
只要编辑好AJ1,直接向下向右将公式下拉即可。
最后在超标项目如AH2栏将AJ~BH系列用 “&组合”,即得到需要的超标结果——超标项目 (超标倍数)[极值]按照超标倍数的由大到小排列 (见表13)。

表13 &组合超标项目表
3 运用Excel进行水质数值统计
水质数据统计过程中主要用到“数据透视表”。使用数据透视表可以汇总、分析、浏览和提供汇总数据。使用数据透视表可显示汇总数据,并且可以方便地查看比较、模式和趋势。
该项功能广泛地应用于水质资料会审、水资源质量通报、水资源公报的前期数据处理中。同时可以计算均值、极值、计数等,这里例举水资源公报中不同水资源分区不同评价类别的河流长度统计。首先将监测断面的基本信息列出 (见表14)。

表14 水资源公报监测站点基本信息表[6]
现需按水资源4级分区统计不同水质类别的河流长度,就是对4级分区里各个类别的长度分别求和 (见表15)。综合评价全年和所属4级分区中的下拉框可以筛选显示;当统计口径需要变更,可以通过报表字段进行打钩筛选;当汇总方式变更,可以通过值字段设置重新选择(见表16)。

表15 按河长、类别透视结果表

表16 数据透视值字段设置表
按照以上的例子,当需要统计年报表中多个站点的全年均值、汛期均值、非汛期均值以及特征值 (最大值及出现时间、最小值及出现时间等)时,只要将全部数据放在同一张sheet表中,统一站点名称,将分析时间按照4—9月为汛期、1—3月和10—12月为非汛期的规则增加一列时期属性,就可以进行同等透视了。
4 结 语
Excel具有强大的试算表、统计图表、资料分析等功能,将其运用在水资源水质监测评价中,实现了工作的高效率、高准确性。本文根据实际工作的需要,运用算术运算、回归曲线、散点图、直线相关分析、IF语句等实现了原始数据的分析处理;并运用 IF叠加语句、MAX语句、VLOOKUP查找语句、SUM+IF数组公式、&组合语句等实现了水质自动评价;运用数据透视表实现了数值的统计。这些语句真实地应用在水质监测评价工作的各个环节,具有极强的指导性。
[1]尚邦懿.GB 11892—89水质 高锰酸盐指数的测定 [S].北京:中国标准出版社,1991.
[2]董华.浙江省水资源监测中心程序文件[Z].杭州:浙江省水资源监测中心,2009.
[3]袁玉璐,姚元.GB 11893—89水质 总磷的测定 [S].北京:中国标准出版社,1991.
[4]宇传华,颜杰.Excel与数据分析 [M].北京:电子工业出版社,2002.
[5]国家环境保护总局.GB 3838—2002地表水环境质量标准 [S].北京:中国环境科学出版社,2002.
[6]周定炎.杭州市水资源公报2010年度[R].杭州:杭州市林业水利局,2011.
猜你喜欢
中国纤检(2022年3期)2022-11-13
新世纪智能(数学备考)(2021年10期)2021-12-21
河北理科教学研究(2020年3期)2021-01-04
语数外学习·高中版中旬(2020年10期)2020-09-10
新世纪智能(语文备考)(2020年4期)2020-07-25
商品与质量(2019年44期)2019-11-28
中学数学杂志(2019年1期)2019-04-03
小学生·多元智能大王(2014年6期)2014-07-09
中国民族民间医药(2011年17期)2011-08-15
小雪花·初中高分作文(2009年8期)2009-11-16
