
LTE系统中Turbo编码的研究与DSP实现*
2011-07-02 10:48李小文
电子技术应用 2011年8期
李小文,许 虎
(重庆邮电大学 通信与信息工程学院,重庆400065)
信道编码是消除或降低信息传输错误概率的有效手段之一。根据Shannon有噪信道编码定理,在信道传输速率R不超过信道容量C的前提下,只有在码组长度无限的码集合中随机地选择编码码字并且在接收端采用最大似然译码算法时,才能使误码率接近为零。Turbo编码[1]巧妙地将卷积码和随机交织器结合在一起,获得了接近Shannon理论极限的译码性能。
Turbo码又称并行级联卷积码PCCC(Parallel Concatenated Convolutional Code),它将卷积码和随机交织器结合,实现了随机编码的思想,在实现随机编码思想的同时,通过交织器实现了由短码构造长码的方法。Turbo码由分量码经由交织器级联而成。分量码和交织器设计的好坏是决定Turbo码性能的关键因素。Turbo码的提出,不仅提供了一个性能优越的编码方法,还更新了编码理论研究中的一些概念和方法。由于Turbo码具有接近Shannon理论极限的性能[2],尤其是低信噪比下的优异性能,使Turbo码成为第三代移动通信高质量、高速率信道中的首选编码方法。
1 LTE系统中的Turbo编码
LTE作为准4 G技术,以正交频分复用OFDM和多输入多输出MIMO技术为基础,下行采用正交频分多址(OFDM)技术,上行采用单载波频分多址(SC-FDMA)技术,在20 MHz频谱带宽下能够提供下行100 Mb/s与上行50 Mb/s的峰值速率。
在LTE系统中,Turbo编码主要应用于上行共享信道、下行共享信道、寻呼信道和多播信道的信道编码[3]处理。由MAC层传来的数据和控制信息比特流经过添加CRC以及码块分割后进入编码单元,编码完成后进行速率匹配[3-4]。
TD-LTE系统中Turbo编码器采用了以2个8状态编码器构成的并行级联卷积的形式,编码速率为1/3,8状态编码器的传输函数为其中 g0(D)=1+D2+D3,g1(D)=1+D+D3。移位寄存器的初始状态是全0。为了让编码器从0状态开始且编码之后回到0状态,编码后的输出比特数为D=K+4,最后的4个比特被称为栅格停止尾比特。Turbo编码器结构如图1所示。

图1 LTE Turbo编码器结构
2 Turbo编码算法分析
Turbo编码原理相对简单,主要由两个子编码器和内交织器组成。每次输入一个码块数据流,两个子编码器结构一样,可以并行处理,其中输入在进入第二个编码器之前要先进入一个交织单元,经交织后作为输入比特序列,然后进入第二个编码器处理[2]。输出三路数据,分别为信息比特流、校验比特流1、校验比特流2。本文提出采用查表法来实现Turbo编码的算法。
具体算法描述如下:
(1)码块分割完后可能出现不同码块大小(K+,K-),算法采用每个码块单独处理。所以需要定义一个标识来查表当前码块需要交织时的参数。
(2)Turbo编码时有反馈的影响,即每个输入比特与反馈值做了“异或”后才能作为移位寄存器的下一个状态,故在实际DSP实现过程中使用了逐位比特处理的方式。
(3)由于Turbo编码器上下两部分处理方法一样,所以在处理上半部分编码器时同时并行处理下半部分,而下半部分输入是经过交织之后的输出比特序列。
(4)根据不同的 f1和 f2可以有不同的结果。f1和 f2一共有188种配对,规律性低,本文只能采用一比特一比特按照公式计算出对应位置,然后进行交织。
(5)采用查表的方式,每输入一个比特加上现在寄存器里面的3个比特作为一个状态(一共4个比特16种状态,输入比特作为最低位),可以查出一个输出比特和下一个寄存器状态。
(6)在尾比特的处理上,每一路的最后3位尾比特与输入无关,只与现在寄存器的状态有关(3 bit一共8种状态)。本文全部列出了8种状态下可能出现的结果。在DSP实现功能时直接判断现在的寄存器处于哪种状态,然后利用查表可以得出3个尾比特。
(7)最后对四路输出的尾比特(3×4=12 bit)按标准做一个赋值处理,然后移位接到之前的比特序列中去就可以得到最终的三路输出比特序列。
3 Turbo编码算法的DSP实现
3.1 硬件
TMS320C6000系列DSP是TI公司推向市场的高性能DSP,综合了目前性价比高、功耗低等优点。TMS320C64系列在TMS320C6000×DSP芯片中处于领先水平,它不但提高了时钟频率,而且在体系结构上采用了VelociTI甚长指令集 VLIW(Very Long Instruction Word)结构[5],芯片内有8个独立功能单元的内核,每个周期可以并行执行8条 32 bit指令,最大峰值速度为 4 800 MIPS,2组共 64个32 bit通用寄存器,32 bit寻址范围,支持8/16/32/40 bit的数据访问,芯片内集成大容量SRAM,最大可达8 Mbit。由于其出色的运算能力、高效的指令集、大范围的寻址能力,使其特别适用于无线基站、测试仪表等对运算能力和存储量要求高的应用场合。
3.2 Turbo编码的DSP实现
由于码块分割完之后可能出现不同码块大小(K+,K-),所以本模块按每个码块单独处理。Turbo编码是作为一个子函数模块,因此,本方案定义输入输出变量及其调用格式如表1所示。

表1 输入输出参数
调用格式:Turbo_Code(int*,int,int,char*,int*),其中 int分别表示TxSegOutTurboIn为输入序列的首地址、TxTurboCodeBitLen;int* 分别表示 TxSegOutTurboInOffset、TxTurboInterMatrixRows;char*表示 TxTurboDataOut为输出序列首地址。
具体实现流程描述如下:Turbo编码时有反馈的影响,即每个输入比特与反馈值做了“异或”后才能作为移位寄存器的下一个状态,故在实际DSP实现过程中使用了逐位比特处理的方式。C语言编写主函数main(),使用汇编编写Turbo编码的实现函数。因为DSP C6455可以直接存取处理32bit,在具体实现中,输入编码比特序列、输入序列比特长度K、用于计算交织查表的指数可以作为函数的输入。在内存中定义了三段长度为码块K+4的 Xk、Zk、Zkp作为暂时存放输出序列的内存空间,并且建立了4张查找表,分别为:(1)交织表格 TxInterleaver,交织表格TxInterleaver占用内存空间为188 B,每个字有32 bit,码块长度 K、f1、f2各自所占比特为 13、9、10;(2)寄存器状态和输出比特表格 turbo_coding,一共4个比特16种状态,占用16个字;(3)尾比特状态和输出比特表格 1turbo_Xk_tail,一共 3个比特 8种状态,占用4个字;(4)尾比特状态和输出比特表格2turbo_Zk_tail,一共3个比特8种状态,占用4个字。
定义一个标识来查表当前码块需要交织时的参数,这样不仅减少任务繁琐,而且减少了系统的代码量,更给代码测试和维护降低了难度。在汇编函数中,利用32作为内循环次数,可以处理完一字(32 bit)就存放在寄存器中。外循环次数使用输入比特所占的双字个数N-1来控制,而可能出现的多出的比特数则需要另作一次(N-32×N)的循环,得到编码结果。
外循环中,在每次内循环之前从输入比特序列中取出32 bit输入比特放入一个寄存器作为一个内循环的输入,这次内循环结束后,取出下一个32 bit输入比特更新这个寄存器,为下一次内循环做准备。每次内循环结束之后,将编码好的32 bit做好存放处理,同时控制外循环次数的寄存器减1,直到循环结束。
内循环中,编码过程采用查表的方式,每输入一个比特加上现在寄存器里面的3个比特作为一个状态,一共4个比特16种状态,输入比特作为最低位,可以查出一个输出比特和下一个寄存器状态。需要注意的是,考虑到下面的速率匹配中需要加入null bit而1 bit的信息不能表示出null bit,所以输出 1 bit的信息就用 8 bit的内存空间来存放。考虑到Turbo编码器上下两部分处理方法一样,所以在处理上半部分编码器时同时并行处理下半部分,而下半部分输入是经过交织之后的输出比特序列。图2给出了Turbo编码实现编码流程图。
值得注意的是,交织器是Turbo编码的重要部分,Turbo编码交织器采用二次多项式(QPP)交织器,其位置对应关系如下:π(x)=(f1x+f2x)mod

图2 TD-LTE系统Turbo编码程序流程图
其中,x=0…K-1,f1和 f2分别可以查表得出。据递推公式:

而g(x)≡f1+f2+2f2x mod K也能够化成:
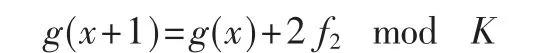
所以可以得出:在DSP中实现时可以不使用乘法和除法取得对应位置,代替使用比较、加法和移位来获得相应的对应位置。
具体做法如下:
(1)根据不同的 f1、f2可以有不同的结果,f1、f2一共有188种配对,规律性低,本文只能采用一比特一比特按照公式计算出对应位置,然后进行交织。
(2)输入比特序列作为交织块的输入,其长度K用来控制交织的循环次数。因为在DSP C6455中寄存器的大小为32 bit,这里32也作为一个循环次数,控制以整双字处理完之后的存取。
(3)进入循环之后,首先判断 π(x)和 g(x)的值是否大于或等于输入比特序列长度K,如果≥K,应该减去K之后再次判断,直到<K之后,进入下一阶段。因为在DSP中存取比特都只能在32 bit之内处理,所以还要判断 π(x)的值是否小于 32,如果不是,则需要减去 32,同时在控制双字偏移的寄存器需要加1,使取值指针指向下一个双字,以达到从下一个双字中取值的目的。此时需要继续做判断直到π(x)<32为止。
(4)得到了控制双字偏移的值和比特偏移的值π(x)之后,便可以从内存中输入的比特序列中取出一个比特作为交织之后的输出比特。通过“异或”移位,完成32次循环之后,寄存器32 bit可以刚好存放下32 bit交织输出比特,然后存放进内存。注意每做一次交织比特,控制输入总长度的寄存器应该减1直到为0时,跳出交织循环,存放输出数据,完成交织。
4 性能分析与总结
在DSP软件实现中,通过指令并行,尽量优化程序循环体,减少或消除程序中的’NOP’指令[6]。对于不同大小的码块长度,根据所用的环境,通过程序仿真运行,可以得到统计结果如表2所示。

表2 不同数据长度的Turbo编码速率
表2数据长度仅为个别举例,但不失一般性。从表中可以看出,虽然查表法的运算量较大,但是当运用TMS320C64×DSP芯片实现时,由于处理器的超高主频一般为 1 GHz,一个指令周期耗时为 1 ns,其运算速率也非常快,完全可以忽略它的计算量。因此,本实现方案采用查表法不仅简化了程序实现方法,还减少了模块程序代码,节约了系统存储空间。
本文从理论分析出发,根据TD-LTE系统特性,提出了一种简单有效的Turbo编码实现算法,详细介绍了该算法在DSP的实现方法,并在TMS320C64×芯片上加以实现。程序运行结果表明,该算法能够满足TD-LTE系统的需求,具有可行性和高效性,并已应用于LTE-TDD无线综合测试仪表的开发中。
[1]王新梅.纠错码原理与方法[M].西安:西安电子科技大学出版社,2003.
[2]BERROU C,GLAVIEUX A,PUNYA T.Near shannon limit error-correcting coding and decoding:TurboCodes[C].IEEE International Conference Communications,1993.
[3]3GPP TS 36.212 v9.0.0 evolved universal terrestrial radio access(E-UTRA)multiplexing and channel coding(Release 9)[S].2009-12.
[4]JIM Z.Overview of the 3GPP long term evolution physical layer[J].2007(7).
[5]Texas Instruments Incorporated.TMS320C64x/C64x+DSP CPU and instruction set referenceguide[EB/OL].Http://www.ti.com.cn,2008.
[6]Texas Instruments Incorporated.TMS320C6000系列DSP编程工具与指南[M].田黎育,何佩琨,朱梦宇,译.北京:清华大学出版社,2006:32-50.
猜你喜欢
美食(2022年2期)2022-04-19
有色金属设计(2022年4期)2022-02-04
计算机应用(2020年5期)2020-06-07
女报(2019年3期)2019-09-10
成都信息工程大学学报(2018年3期)2018-08-29
成都信息工程大学学报(2018年6期)2018-03-21
制造技术与机床(2017年7期)2018-01-19
华人时刊(2016年17期)2016-04-05
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
