
DSP语音识别电梯控制系统的设计和实现
2011-06-30 07:55:00陈卫兵何必都黄永坤邹豪杰张洪波
湖南工业大学学报 2011年4期
陈卫兵,何必都,黄永坤,邹豪杰,张洪波
(湖南工业大学 计算机与通信学院,湖南 株洲 412007)
0 引言
语音识别是将原始语音经过预处理后进行特征提取,再与事先经测试和训练后所得并存储到计算机的标准参考模型进行比较,最后得出判定和识别结果。20年来,语音识别技术取得了较大发展,它经历了从孤立词、小词汇量、特定人到大词汇量、非特定人的发展历程[1]。但语音识别的计算量较大,难以实时实现,此问题制约着它在各个领域内的应用。目前,随着数字信号处理(digital signal processing,DSP)专用集成电路技术的迅速发展[2-3],语音识别,尤其是计算量较小的非特定人的孤立词识别的实时实现成为可能。
电梯行业中,传统的电梯控制器要求人们通过按电梯的楼层按钮来确定需要到达的区域。当电梯中人数较多、较拥挤时,按键很不方便。考虑到语音的非接触传输特点,将语音识别和控制技术用于电梯中,将使传统的电梯更加人性化、便捷化。因此,本文拟以TMS320C6713 DSP芯片作为系统运算控制中心,TLV320AIC23B芯片作为语音输入、输出的模拟前端,EP2C5Q208C8 FPGA芯片作为系统IO扩展,将这3个部分有机结合,开发基于非特定人、孤立词、小词汇量的嵌入式语音识别电梯控制系统,以解决多人乘坐电梯时按键不方便的问题。
1 系统设计方案

图1 系统总体结构框图Fig.1 Block diagram for the overall system
从图1可看出,所设计的语言识别控制系统主要由TMS320C6713 DSP语音识别处理芯片、TLV320AIC23B语音输入/输出的模拟前端芯片、电梯控制接口扩展FPGA芯片和其他辅助芯片(外部储存器SDRAM选用MT48LC4M16A2,大小为64 MB,对应地址为:0x80000000H~0x82FFFFFFH。
FALSH采用AM29LV800B,大小为2 MB,对应地址为0x90000000H~0x90200000 H组成。TMS320C6713为高性能32位浮点DSP,适用于专业音频信号处理,主频达300 MHz,处理速度达2400 MIPS/1800 MFLOPS,能满足快速运算和处理时间的语音识别要求。
TI公司的TLV320AIC23B是一款集成ADC(application data center),DAC(digital analog canverter)于一体的模拟接口电路,采用先进的Sigma-delta过采样技术,可在8 kB~96 kB采样率范围内提供16,20,24,32 位采样,ADC和DAC的信噪比可分别达90 dB和100 dB。其与外围音频输入设备的接口电路如图2所示。

图2 音频输入电路Fig.2 Audio input circuit
TMS320C6713与TLV320AIC23B连接方式见图3。
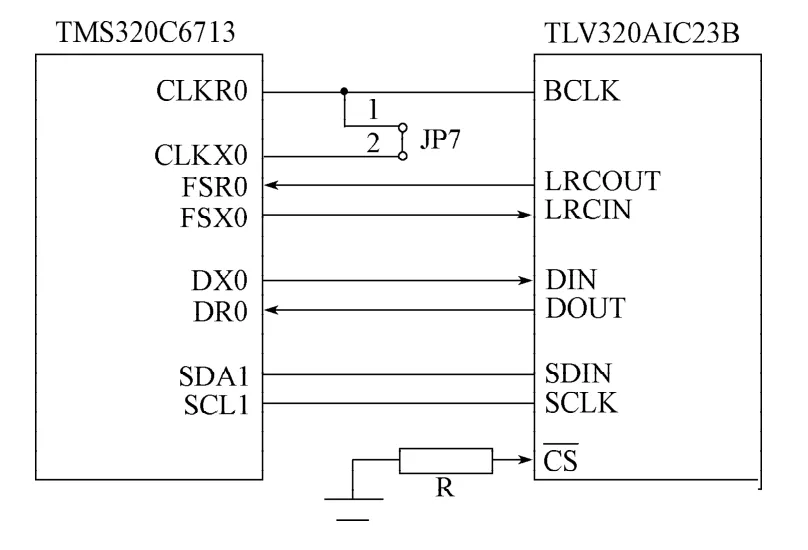
图3 TMS320C6713与TLV320AIC23B硬件连接Fig.3 The hardware connection between TMS320C6713 and TLV320AIC23B
TLV320AIC23B的控制口用于设置其工作参数,采用I2C总线口1实现;数据口用于传输TLC320AD50B的A/D,D/A数据,TLV320AIC23B的数据口与TMS320C6713的McBsp0接口连接,用于芯片间的数据交换。
2 算法及软件实现
2.1 语音识别算法
语音识别系统的总体方案见图4。
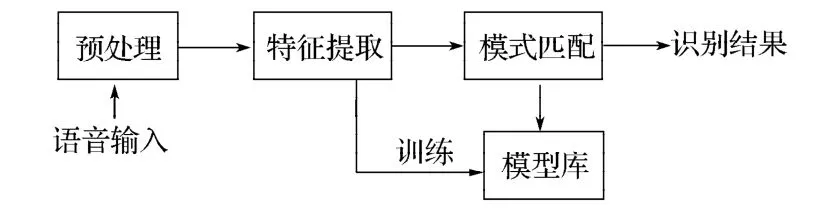
图 4 语音识别方案Fig.4 The program of speech recognition
语音识别系统首先将收集到的语音信号进行预处理,包括预加重、加窗、端点检测等;然后进行特征提取,即从语音波形中提取出随时间变化的语音特征序列;最后,将其训练为声学模型,并且在模式匹配中运用识别算法进行匹配,得到最佳识别结果。
2.2 端点检测
端点检测之前先对采集到的语音信号进行预加重,以去除语音信号中的低频噪声,然后选用hamming窗做加窗处理。主要依据为hamming窗主瓣比矩形窗的主瓣宽度大1倍,同时其带外衰减也比矩形窗大1倍多,因而不会损失信号中的高频成分。加窗后将语音信号分割为帧。
端点检测就是从含噪声的信号中检测出说话人语音信号的起始点和结束点。只有正确检测出语音信息段才能正确地进行语音处理。端点检测的时域处理方法是:首先在当前环境情况下,采集一段无声语音,求出平均过零率。由于采集声音信号的最初的短时段为无语音段,仅有均匀分布的背景噪声信号。这样就可以用已知为“静态”的最初几帧(一般取10帧)信号计算其过零率阈值,以此作为无语音段,当过零率变化时作为语音的起始。语音结束点的获得方法与此相同,从后向前搜索,当超过过零率的变化时作为语音的结束。
2.3 特征提取
特征参数提取[4]是指从语音信号中抽取有效的语音信号特征,提取算法如下:
1)对信号进行短时傅里叶变换得到频谱。
2)求频谱幅度的平方得到能量谱,再用一组三角形滤波器在频域内对能量谱进行带通滤波;设滤波器数为M,滤波后得到的输出为X(k),k=1,2,…,M。
3)对滤波器组的输出取对数,然后对它做2M点逆离散傅里叶变换,得到Mel频率倒谱系数(mel frequency cepstrum coefficient,MFCC)。因为对称性的关系,变换式可简化表示为:
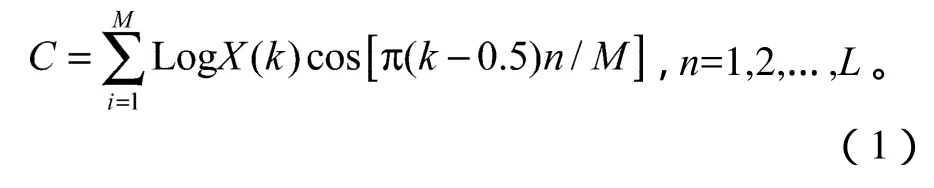
式中L 为MFCC系数的个数,本系统取24个。
2.4 模板匹配
采用动态时间弯折(dynamic time warping,DTW)算法[5]进行模板匹配:假设参考模板的MFCC系数向量序列为X=(x1, x2,…, xi),输入语音的MFCC系数向量序列为Y=(y1, y2,…, yj),i≠j。DTW 算法就是要寻找一个最佳的时间规正函数,使待测语音的时间轴j非线性地映射到参考模板的时间轴i上,因而总的累计差值最小。算法过程如图5所示。
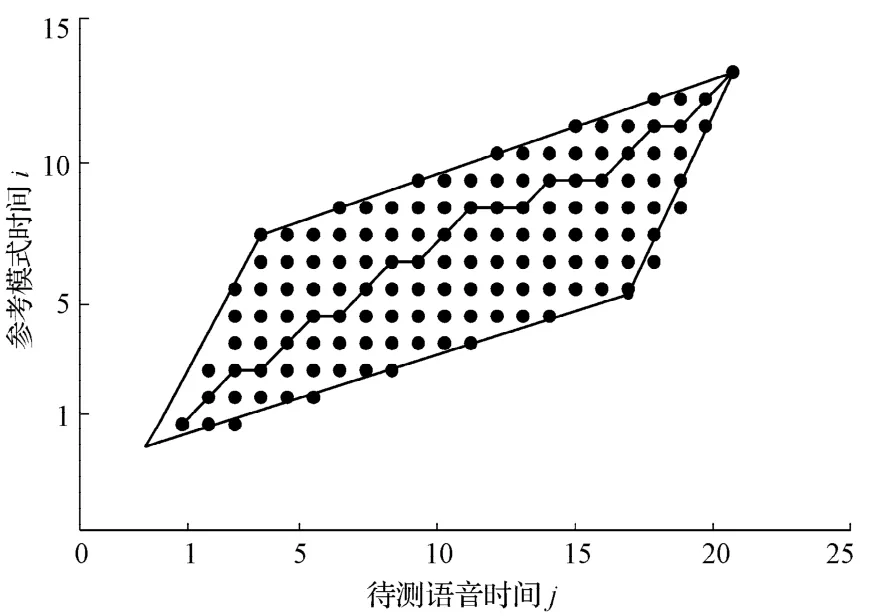
图5 DTW算法过程Fig.5DTW algorithm process
图5中曲线连接起来的点就是模板与待测语音信号间的距离d(xi(n),yj(n)),亦称为局部匹配距离。DTW 算法就是通过局部优化的方法实现加权距离总和最小,也就是相似度最大,即
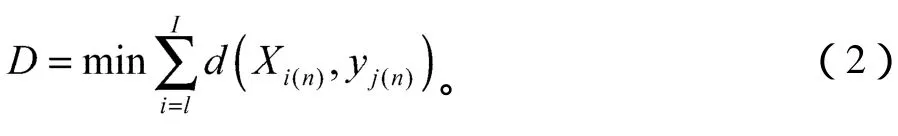
2.5 软件实现
软件设计以TI DSP/BIOS实时多任务操作系统为软件设计基础,采用图像界面配置DSP/BIOS,在开发环境中自动生成.cmd文件。使用TI的TMS320C6000 Chip Support LibraryAPI Reference Guide进行EMIF,McBsp,PLL等初始化操作。通过I2C总线端口1配置TLV320AIC23B芯片,McBsp0口与TLV320AIC23B相连实现语音信号采集。端点检测、MFCC和DTW模板匹配用C语言编写。系统实现的主流程见图6。
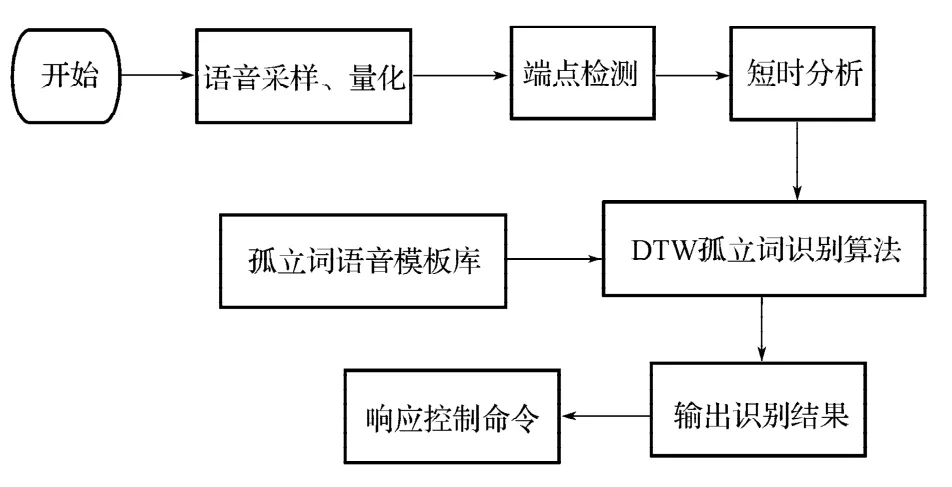
图6 程序主框图Fig.6 The block diagram of main program
TLV320AIC23 内部有11个16位寄存器,这16位控制字中,B[15~9]为寄存器的地址,B[8~0]为要写入寄存器的数据。写入11个寄存器的数值如下:左声道输入控制=0x17;右声道输入控制=0x17;左耳机通道控制=0x7F;右耳机通道控制=0x7F;模拟音频通道控制=0x1C;数字音频通道控制=0x1;启动控制=0;数字音频格式=0x4F;样本速率控制=0x3F;数字界面激活=0x01;初始化寄存器=0。设置完成后,启动A/D 转换,将转换后的数据存储在DSP的内部存储器中,每次采样128点。数据采集流程见图7。
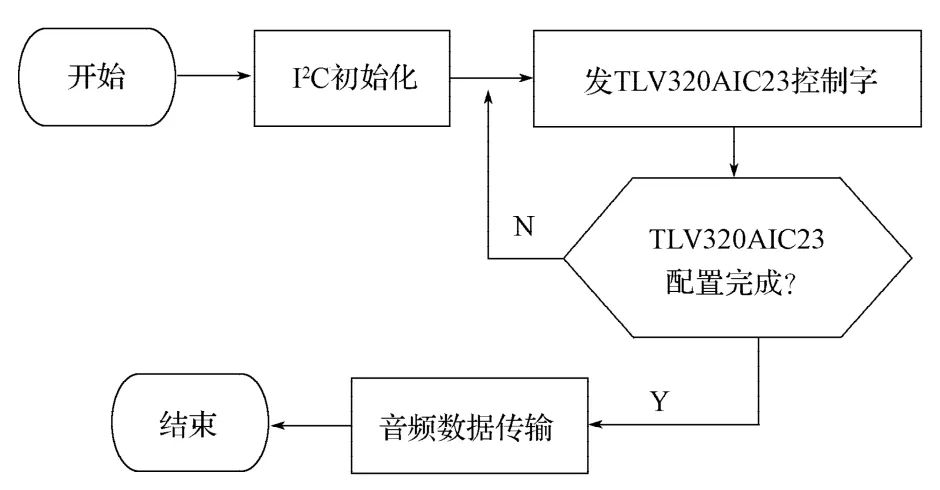
图7 音频数据采集Fig.7 Audio data acquisition
3 测试结果
每次测试的采样数为128点,采样频率设为44.1 kHz,样本大小为16位。在类似电梯的环境中进行测试,所得结果见表1。
从表1中可以看出,所设计的控制系统总的平均识别率大于80%。且女性的测试结果普遍比男性好,这应该归属于男性声音中浊音分量比女性重,导致在系统识别时难度加大。

表1 语音识别电梯控制测试结果Table 1Test results of elevator speech recognition control
4 结语
本研究是在以TMS320c6713为控制核心,TLV320AIC23B芯片为语音输入、输出的模拟前端,EP2C5Q208C8 FPGA芯片为系统IO扩展的情况下,设计和实现了非特定人、孤立词、小词汇量的嵌入式语音识别电梯控制系统。测试结果表明:所设计的系统的识别和控制效率达80%以上,该系统具有较好的应用前景。
[1]赵 力.语音信号处理[M].北京:机械工业出版社,2009:114-117.Zhao Li.Speech Signal Processing[M].Beijing:Mechanical Industry Press,2009:114-117.
[2]周 霖.DSP通信工程技术应用[M].北京:国防工业出版社,2004:145-189.Zhou Lin.DSP Communications Engineering Technology[M].Beijing:National Defence Industry Press,2004:145-189.
[3]邹 彦.DSP原理及应用[M].北京:电子工业出版社,2005:114-117.ZouYan.DSP Principles and Applications[M].Beijing:Electronic Industry Press,2005:114-117.
[4]侯雪梅,田 磊.基于Mel倒频特征和RBF网络的孤立词语音识别方法[J].西安邮电学院学报,2008,13(3):114-117.Hou Xuemei, Tian Lei.Speech Recognition Method of Isolated Words Based on Mel Cpestrum Feature and RBF Neural Network[J].Journal of Xi’an University of Post and Telecommunications,2008,13(3):114-117.
[5]万 春.基于DTW的语音识别应用系统研究与实现[J].集美大学学报,2002,7(2):104-108.Wan Chun.Research and Application of DTW-Based Speech Recognition[J].Journal of Jimei University,2002,7 (2):104-108.
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:34
计算机应用(2020年5期)2020-06-07 07:06:44
中学生数理化·教与学(2019年8期)2019-09-18 15:08:40
小学生学习指导(低年级)(2018年3期)2018-01-31 02:18:58
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
数学物理学报(2017年1期)2017-06-05 09:12:28
小学生时代·综合版(2016年7期)2016-05-14 17:53:49
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:52
红蜻蜓·低年级(2015年11期)2016-02-02 10:54:54
小说月刊(2015年4期)2015-04-18 13:55:18
