
基于日志分析的中文输入法用户行为研究
2011-06-28 02:18许丹青刘奕群岑荣伟马少平茹立云
中文信息学报 2011年2期
许丹青,刘奕群,岑荣伟,马少平,茹立云,杨 磊
(智能技术与系统国家重点实验室,清华信息科学与技术国家实验室(筹),清华大学计算机系,北京 100084)
1 前言
随着互联网在中国的蓬勃发展,中国网民的比例越来越大,据统计,直至2010年初,中国网民已达到了3.84亿,位于全球首位[1]。中文输入法作为中国网民在互联网上必不可少的输入工具,其作用也变得越来越重要。与英文输入不同,中文的很多候选词条所对应的拼音输入相同,如果对于一个拼音输入而言,大多数用户都选择了某个词条作为最终的结果,那么我们就将这个词条排在越靠前的位置。这也是当前的很多输入法所采用的排序策略的主要思路。由于数据收集和分析的困难,以前对输入法的研究主要集中用自然语言处理的方法,将现有的一些分词算法和排序算法进行一些优化和改进[2-3],而对目前输入法的用户行为研究并不多见。我们主要对经过用户许可收集的某中文输入法一天的数据进行分析,希望可以从中得到输入法用户行为的一些普适特征,为当前的输入法日后的改进提供帮助。由于日志数据规模较大,所以结论具有一般性,能反映大多数用户的行为特征。
本文后续的内容组织如下:第2节是对前人相关工作的一些概述,第3节简单描述了我们采用的输入法格式,第4节从三个不同方面对输入法日志的用户行为进行分析,第5节从分析的结果中尝试得出一些对当前输入法改进有用的启示和结论,第6节是参考文献说明。
2 相关工作概述
由于Web数据规模庞大且数据格式等比较杂乱,因此,现有的输入法必须经过分词、过滤、排序等操作才能得到能够供用户使用的词条。同时由于与用户体验联系紧密,这部分的工作主要集中在产业界,目前研究界使用较多的是用户查询词日志,前人多次使用查询日志对用户需求进行分析[4],最典型的使用就是查询推荐和查询纠错。而目前的产业界的输入法分析改进主要集中在全局的词库生成算法和词条排序算法,通过词库生成算法生成格式规整的词库,然后再通过词频等一系列的特征进行权重计算,对候选词条进行最终的排序。
前不久,中国科学院研究生院的张玮[5]等人提出了一种结合分类模型的中文输入法,他们针对现有输入法很少用的候选词本身的特性,将输入法词库进行了类别标注,同时根据用户当前输入串的上下文判定当前的输入语境类别,提高属于当前类别词库的词条在整个词库中对应权重,这样符合上下文语境的词条就会排在相对靠前的位置。这种对输入法词库进行类别标注并在输入法系统中集成分类引擎的方法,可以在一定程度上提高用户的输入效率和体验度的,然而,其工作缺乏大规模数据集的训练和测试。
此外,输入法的用户交互行为也很重要。之前,我们就某中文输入法某一天的日志进行了简单的分析[6],主要从用户使用的应用程序的相对熵值和用户半径这两个特征简单分析了各个应用程序类别的用户行为,研究结果显示有着相同用户需求的应用程序之间有着相似的属性。基于之前的工作,本文将从其他多个方面对输入法的用户行为进行详细分析。
3 输入法日志格式说明
该实验中所采用的日志是来自于某中文输入法“用户体验提升计划”记录的用户行为日志,该部分日志得到了行为信息收集对象的同意,完全为匿名记录。我们选取了2009年11月1日当天的日志数据,其涵盖了4.1亿条用户输入条目,417万个独立用户和8 232个应用程序。其中每条用户输入条目包含的信息如表1所示。

表1 输入法日志格式
4 基于输入法日志的用户行为分析
4.1 词频与应用程序使用频度的分析
该实验中,我们对日志中的所有词条以及所有应用程序按照其使用频度进行了排序,并分析了使用频度和其对应的排序之间的关系,如图1所示。

图1 词条和应用程序的使用频度与对应排名的关系
图1显示,应用程序和词条的使用频度是符合幂律分布的,即极少数的应用程序和词条的使用频度占了所有应用程序频度的绝大多数。统计发现,排名前10的应用程序的频度占了输入法总数的77.4%,而排名第1的应用程序—— 腾讯QQ聊天程序的使用频度占了总使用频度的44.2%。这里,为了更加方便的对排名前10的应用程序进行深入的研究和分析,我们在表2列出了使用频度排名前10的应用程序的名称。
从表2可以看出,使用频度排名前10的应用程序主要分为四类:即时通信类、游戏类、浏览器类和办公编辑类。本文中, 我们将针对这四个主要类别和这10个应用程序的词频等特征展开分析。

表2 排名前10对应的应用程序
4.2 各个主要应用程序间一元,二元词频相似度分析
在这些主要应用程序的基础上,我们还分别对它们的一元与二元高频词进行统计,根据两个应用程序之间的一元(或是二元)词频的前200个词中所包含的相同词的个数,从而计算两个应用程序之间的相似度。假设应用程序a一元(或是二元)词频的前200个词的集合为Va,应用程序b的一元(或是二元)词频的前200个词的集合为Vb,我们定义a与b的相似度计算公式如公式(1)。
(1)
另外,除了对应用程序之间进行了词频相似度的计算外,我们还对两个类别之间的应用程序进行了平均相似度的计算。假设有k个程序属于某一类别A(i=1…k),n个程序属于某一类别B(j=1…n),类别A和类别B之间的一元(二元)词频的平均相似度计算公式如公式(2)。
(2)
我们对输入法中的主要应用程序(见表2)的一元词频的top200进行了提取,并分别根据公式(1)和公式(2)进行了一元相似度和二元相似度的计算,表3 显示了各个程序之间的相似度结果,其中上三角表示的是一元相似度的计算结果,而下三角表示的是二元相似度的对应的计算结果。
通过表3的词频相似度结果的对比, 我们可以很明显的看出: 有着相同的用户需求的应用程序的词频相似度要明显高于其他不同需求的程序。如程序“qq”与“fetion”的之间的相似度明显高于其和“dnf”,“winword”等程序。在本节中,我们主要就高频词条的相似度作为衡量应用程序的用户行为的一个特征。表3的结果显示,相同类别的应用程序之间的高频相似度很高,即相同类别的应用程序有着相似的用户行为。为了进一步深入探索用户需求与应用程序的关系,接下来我们对主要应用程序类别之间的一元平均相似度和二元平均相似度分类别进行观察比较。
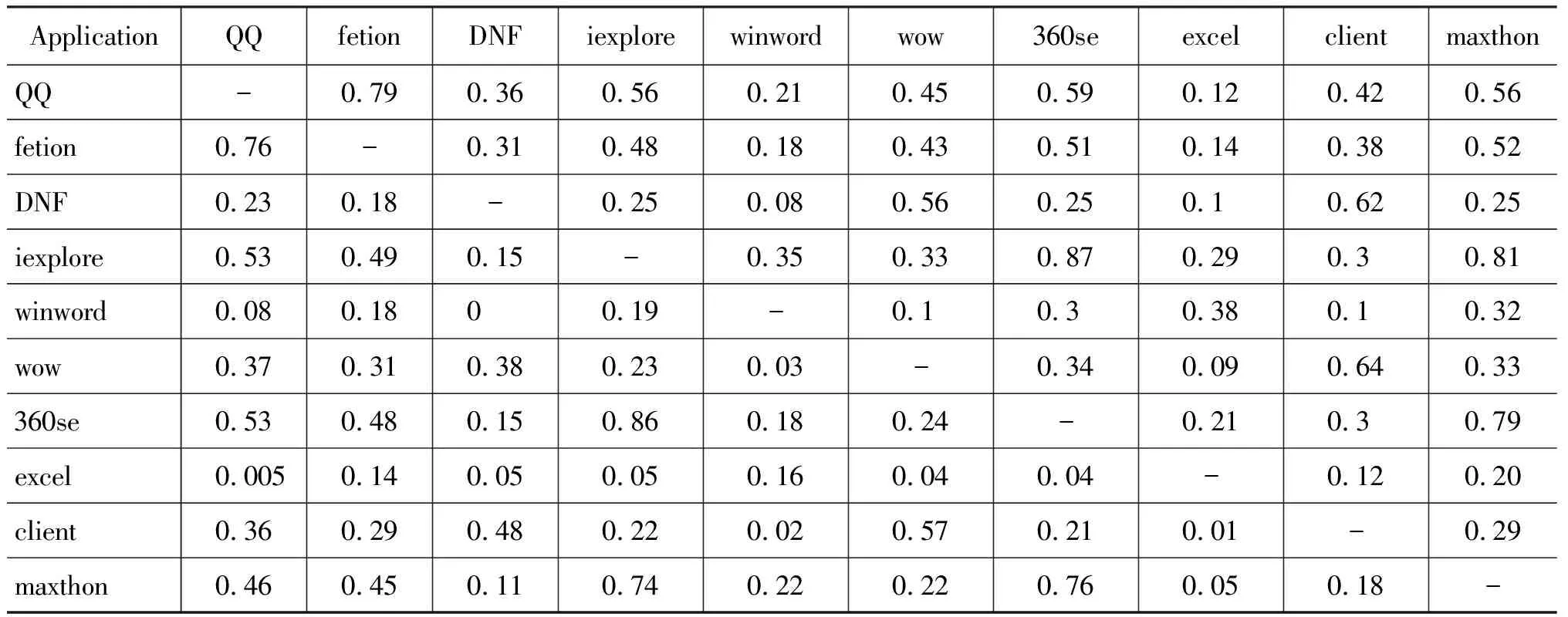
表3 主要应用程序的词频相似度
表3显示了相同类别的应用程序的词频相似度很高,因此,我们将各个主要应用程序根据其用户需求的不同进行了类别分类,并且对类别之间和类别之内的平均相似度按照公式(2)进行计算。类别内部的平均相似度是所有这个类别内部的应用程序相似度的平均值,与此类似,类别之间的平均相似度是分属于两个类别的应用程序相似度的平均值。图2显示了类别之间的一元词频的平均相似度的结果。
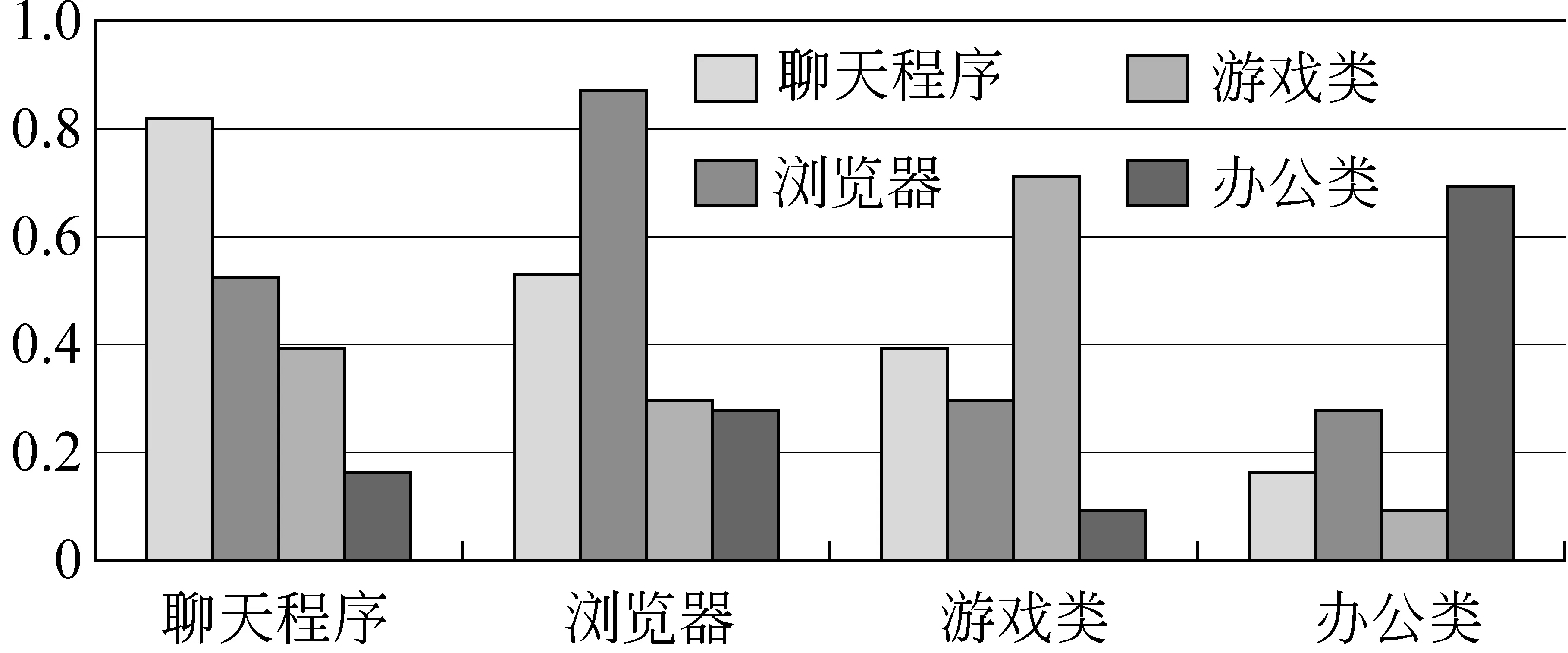
图2 不同类别之间的一元词频相似度
图2显示,不同类别内部的平均相似度也是不同的。其中,浏览器类的高频词条的相似度最高,达到了0.85。浏览器类的词频分布相对集中,需求比较明确,而办公和游戏类用户群体差异较大,需求比较分散,这也在一定程度上解释了浏览器内部的平均相似度最高,而办公和游戏类相似度较低的结果。另外,我们还发现,不同类别之间的相似度也是不同的,聊天程序和浏览器的相似度达到了0.5左右,而和办公编辑类的只有0.1。这表明了聊天类和浏览器类之间有着一定的相似度。为了进一步的对进行类别之间的比较,我们也按照类似的方法对二元词频相似度进行了统计,统计结果见图3。
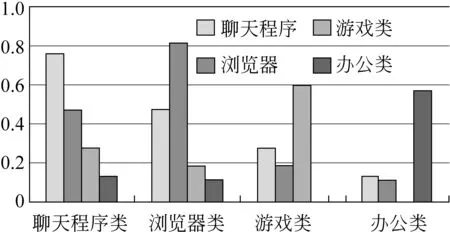
图3 不同类别之间的二元词频相似度
将二元词频的相似度和一元词频相似度进行对比,各类程序之间的相似度趋势几乎没有发生变化。浏览器类内部的相似度依然最高,而办公类和游戏类之间的平均相似度几乎为0,即办公类的高频词和游戏类的高频词几乎没有重合,这与办公类和游戏类用户需求相差较大的原因有一定的关系。通过上述的一元词频和二元词频相似度的分析,我们可以假设,如果对现有输入法词库和排序策略按照应用程序的类别属性进行更新和改进,应该可以在一定程度上提高用户的满意度。
4.3 各个主要应用程序之间的KL距离分析
上一节中,我们从高频词频的相似度对不同应用程序类别的用户行为习惯进行了分析,下面我们将选定相对熵和用户半径这两个指标作为另一种衡量应用程序之间的差异的特征[7]。首先,相对熵的定义如下:
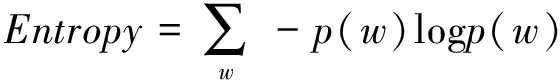
其中p(w)代表某个词w的概率分布,Entropy代表的是整个应用程序的相对熵。如果某个应用程序的相对熵很小,表示其对应的用户行为相对较为集中。
用户半径衡量的是应用程序中的每个用户到该应用程序总体词频分布的中心点的距离,每个单独的用户半径作为一个独立的点,没有统计意义,因而我们将应用程序的用户半径定义为此应用程序中所有用户半径的平均值,其是衡量用户行为另一个重要的指标。用户半径越小,代表此应用程序的用户群的行为特征有着较高的相似性。应用程序对应的用户半径定义如下:


表4 主要应用程序的熵值与半径
4.4 其他用户行为分析
首词条命中率,即排在第一位的候选词条被命中的比例,翻页率则是用户在输入法提供的候选结果中进行翻页的比例。首词条命中率和翻页率一直被认为是衡量输入法效率很主要的两个指标,因此,我们将对各个类别对应的首词条命中类别和翻页率进行了统计,统计结果如图4。

图4 各种应用程序的首词条命中率和翻页率对比
上述的图表显示,即时通信类两者的质量评估总体是最好的,而游戏类的则相对较差。同时,首条命中率和翻页率随不同的应用程序类别也是不同的。究其原因,可能是因为不同的拼音串在不同的应用程序类别中,用户所需要的中文候选词条互不相同。这样可能导致在一些类别的应用程序中首次命中率下降,翻页率上升,从而导致用户体验度下降。
5 结果与讨论
衡量中文输入法产品的优劣有很多指标,其中包含首条词条命中率、翻页次数、内存占用量、简拼词使用率等,这些都直接影响着用户的满意度。本文主要从两个方面对输入法日志进行了分析:首先,就一元、二元词频相似度分析而言,我们发现有着相似用户需求的应用程序(同一类别)之间的词频相似度要明显高于不属于同一类别的相似度;不同类别内部的平均相似度也是不相同的。其中,浏览器类别内部的相似度最高(达到0.85),表明浏览器类的词条需求较为集中。其次,我们对应用程序的熵值与用户半径进行了定义,并用其对各大主要应用程序进行分析。分析发现,用户需求相似的应用程序在熵值和用户半径有着相似的属性。其中游戏软件类和即时通信类的熵值和用户半径比较小,表明这两类所对应的用户群相对较为集中。同时,我们发现,当前的首词条命中率和翻页率也是随着应用程序类别发生变化的。即时通信类别的效果最好,而游戏类别相对较差。
词库和排序策略是整个输入法的核心。目前输入法对所有应用程序均采用了同样的词库和排序算法,然而很多情况下能够达到全局最优的条件未必会是局部最优。目前即时通信类用户占了整个输入法用户的50%左右,于是当前的词条排序大都是基于即时通信类用户最优的,而其他类用户和即时通信类用户需求之间有一定的差异,从而导致了当前的词条排序不能很好的满足其他类用户的输入需求。通过我们的分析发现,如果我们可以对于不同用户需求的应用程序,选用不同的词库和排序算法,
则会使得不同应用需求的用户的满意度都得到一定的提升。
用户需求是输入法最切实的质量评估,然而也是最抽象的,有时可能一个应用程序会对应着不同的用户需求,所以为应用程序定位其对应的用户需求,从而进行针对性改进,是我们下一步研究的方向。
[1] 中国互联网络信息中心(CNNIC),第25次中国互联网络发展状况统计报告[EB/OL],2010年1月,http://www.cnnic.net.cn/uploadfiles/pdf/2010/1/18/141029.pdf.
[2] Z. Chen and K. Lee. A new statistical approach to Chinese pinyin input[C]//The 38thAnnual Meeting of the Association for Computational Linguistics, 241-247, Hong Kong, 2000.
[3] CD Manning, H Schutze. Foundations of Statistical Natural Language Processing[M]. The MIT Press, Cambridge, Massachusetts, 1999.
[4] D Downey, et al. Understanding the relationship between searchers’ queries and information goals[C]//CIKM’08, 449-458, California, 2008.
[5] 张玮,孙乐,冯元勇,等.一种结合分类模型的中文输入法[C]//中国中文信息学会二十五周年学术会议,2006:586-593.
[6] R Cen, et al. Study Language Models with Specific User Goals[C]//The 19thinternational conference on World Wide Web, 1073-1074, USA, 2010.
[7] J Lin. Divergence measures based on the Shannon entropy[J]. IEEE Transactions on Information Theory, 1991, 37:145-151.
猜你喜欢
小雪花·初中高分作文(2021年3期)2021-08-27
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
电脑爱好者(2018年7期)2018-04-23
电脑爱好者(2018年7期)2018-04-23
电脑爱好者(2017年5期)2017-05-04
妇女之友(2017年3期)2017-04-20
中国知识产权(2016年11期)2016-11-11
中国药物应用与监测(2015年5期)2015-12-11
网友世界(2009年12期)2009-03-05
