
适合话音服务平台的结构化小文本搜索引擎的研究
2011-06-27 03:00:40陈晓勤
电信科学 2011年12期
杨 震,夏 艳,陈晓勤
(中国电信股份有限公司上海研究院 上海200122)
1 引言
电信运营商在转型过程中一直谋求在增值服务领域进行突破。信息服务从接入平台看有传统互联网 (宽带internet)、移动互联网(含客户端)、话音、短信4大渠道,其中传统互联网的信息服务模式最为成熟,而移动互联网的信息服务模式还在探索和发展阶段,话音信息服务渠道历史最为悠久,也是目前可见的、运营商可以发力的渠道。如何在新形式和技术背景下,把先进的信息技术引入到话音信息服务平台,从技术实现和业务研发角度为话音信息服务注入新活力是值得探索的问题。
中国电信集团公司以号码百事通为主导,在话音信息服务平台进行了转型业务的探索,几年以来取得了不俗的成绩,其中不但有业务模式的创新,更重要的是在传统话音“114”信息服务平台上引入搜索引擎的思想,使用先进的搜索引擎技术手段整合信息资源,开发并升级适合于增值话音信息服务平台的信息查询系统,为用户提供更精准的信息服务,无疑是一个亮点。
2 话音信息服务平台对于信息搜索的需求分析
随着互联网的发展,搜索引擎技术和应用逐步占据互联网应用的核心,以Google为代表的搜索引擎引领了互联网信息服务的发展方向。其主要特点是采集互联网上不同网页的信息,经过信息加工、分析,提取网页中的关键词,之后建立关键词和出现网页的索引,供用户进行互联网信息的搜索和使用。
但是面向互联网非结构化信息的搜索引擎设计方法如果不加改造,是不适用于话音信息服务平台的,相比较而言,两者有两个显著的差异点。第一,信息资源的差异:话音平台的信息服务资源是可以通过人工整理并进行设计的,是有限的、结构化的,并且信息相对精炼。而互联网信息是海量的、非结构化的,数据量大且信息质量难以控制;搜索引擎是利用网页之间的链接及Pagerank技术进行信息的评价和排序。因此,如何利用好话音平台信息资源定义及整理的优势,是话音平台搜索引擎设计所必须考虑的问题。第二个差异是话音信息服务的用户界面小,通过话音信息交互每次播报给用户的查询结果只有有限的几条,要求结果十分准确。而互联网的搜索引擎是通过浏览器与用户进行信息交互,一页有10条结果,用户可以通过翻页、调整关键词自由地与引擎进行交互,学习并适应互联网搜索引擎的特性,使搜索更加有针对性。因而话音平台的信息服务的准确率较互联网信息服务要求更高,对搜索算法的设计更加苛刻。
3 号码百事通搜索引擎的设计思想
在号码百事通搜索引擎设计和开发之前,以“114”为代表的话音信息服务平台是基于传统数据思想进行设计和开发的,是数据库全文检索。而传统数据库的发展是面向报表类信息,即物料的进销存而设计和发展的,把数据库能力用于信息服务领域是其应用的延伸,但是从本质上讲,其自身的局限性很难适应号码百事通这类苛刻的信息服务的需求。主要有以下局限性。
·不能很好地满足模糊查询需求:传统的“114”信息查询是一种编码查询,信息的排序也只是简单地依据拼音或是笔画排序,这无法满足越来越多的模糊的语义或同义词查询需求。另外编码查询座席的培训成本较高,且服务的种类、灵活性支持有限,信息服务扩展能力不强。
·多字段组合查询:数据库全文检索只是简单地把若干个字段信息进行合并后的检索,没有考虑各个字段的信息定义及相互关系。而话音平台的搜索引擎需要能够利用话音平台的结构化信息定义,设计出符合信息表达本质的联合查询算法,即考虑到关键词在某个字段出现的情况,又考虑到这个字段的定义对于一条完整信息表达的贡献度。
·信息搜索的精确性:信息搜索精准的直观表达即是信息的排序。由于话音信息服务平台的特殊性,因此要求话音信息服务平台的搜索引擎具备极高的查准率,这样不但适合每次只能播报几条信息的苛刻要求,还能节省用户获取信息的时间。而传统的“114”信息查询只能实现基于拼音或是笔画的排序,无法按照服务内容的相关程度进行排序。
·不能很好地实现各种业务模式:后向经营的业务模式,对报号(排序和播报)提出很灵活的要求,如按次、天、概率进行符合搜索需求的信息轮循排序,这点传统数据库支持能力也有限。
·不能很好地支持后向企业信息发布服务:由于话音服务平台的界面限制,要求信息发布更加具有针对性,使企业发布的信息有效地传达到目标用户群。因此用户信息需求特征的识别和发布信息的匹配显得越发重要。
·不能很好地支撑经营分析:查询用户需求取向、被查询客户的客户分析,各类排行榜和分布图等原有系统都不支持。
·平台并发能力弱:基于数据库的信息查询服务,在大并发量和复杂业务模式下支持能力有限,查询时间长。
本文应用搜索引擎基本原理和技术,并考虑“114”信息服务的特点,创新地提出了结构化小文本搜索引擎的信息搜索系统和方法,对传统“114”查号服务进行改造提升,同时考虑了平台后向商家信息发布的需求,从而打造出以话音为基础的双向综合信息服务平台。
4 基于结构化小文本搜索引擎的设计
为了克服传统数据库信息搜索方面的缺陷,本文引入基于内容的信息检索到话音服务系统中。基于内容的信息检索不只是简单地考虑是否包含某一个词条,还要考虑这个词条在文档中的含义,可以有效去除那些对文档内容没有贡献但是与需要检索词条相同的文档噪音(词条);同时,把话音信息服务平台中信息的定义也考虑到检索模型的设计中,因为模型的构造对基于内容搜索的效率有重要的影响[1]。目前比较成熟的检索模型主要有布尔逻辑模型、向量空间模型、概率推理模型等[2,3]。其中Salton等提出的向量空间模型相对较适用于话音服务信息平台的需求。该模型将查询条件和文档分别抽象成多维向量空间中的向量,通过比较两个向量之间的关系来判断查询与文档的相似程度,再根据相似度的大小返回满足条件的结果集合[4~9]。
通过发展向量空间模型,在模型的建立过程中考虑话音信息服务平台结构化信息的表达方式,考虑话音平台信息的定义明确、信息资源文本量少、可计算参数少,但是服务针对性强,服务种类相对可规范的特点,最大限度地发挥话音平台结构化信息的优势。同时应用服务的积累能力,完善模型的构建及相关权值的计算。
本文中的结构化是指话音信息服务平台的信息是经过整理和定义的,信息描述的各个维度是结构化的,有定义的;而小文本是指信息包含的文本量少、精炼,按照传统文本搜索计算模型的可计算参数相对较少。总体设计思路是建设基于结构化小文本搜索系统,包括:
·结构化小文本搜索算法设计;
·结构化小文本搜索引擎设计。
4.1 结构化小文本搜索引擎算法设计
基于结构化小文本的相关度计算模型如下。
假设:一个关键词d1经过同义词、近义词扩展后,获得查询的目标向量为D′={d1,d2,…,dn},其中D′既是查询向量,也是获得的查询结果需要匹配的查询目标向量,而dn是D′中第n个关键词;x代表系统对一个关键词的评价值,即权重,xn为对查询目标向量D′中第n个关键词的评价,则查询目标向量D′扩展后为 D,表示为D={(d1,x1),(d2,x2),…,(dn,xn)}。在实际开发中,同义词、近义词扩展,权重的评价值可以在服务过程中,根据话音信息服务平台的特点逐步积累获得。
检索服务器基于查询目标向量D={(d1,x1),(d2,x2),…,(dn,xn)}在数据库中查询,获得M条记录,这些记录的各个字段中或多或少地包含查询扩展之后的查询目标向量中的关键词,其矩阵表示形式如下。
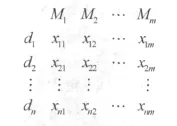
其中xnm代表第n个关键词在第m条记录中出现,并且其对应的权重为xnm。
设一条记录有j个字段,按字段对查询的贡献程度,目前定义服务特征级、户名级、地址级和其他级4个级别,并综合计算。各个字段的贡献程度以贡献系数表示,分别为 α、β、ε、η,则:

其中 α+β+ε+η=1;1≥α>β>ε>η≥0;参数可以动态调整。j1代表关键词在服务特征字段出现;j2代表关键词在户名字段出现;j3代表关键词在地址字段出现;j4代表关键词在其他字段出现。虽然在此给出的例子中仅使用了4个级别及其对应的贡献系数α、β、ε、η,但是根据实际需要,可以使用任意数量的级别及其对应的贡献系数。
在确定了xnm之后,查询目标向量D与第m个记录Mm之间的相似度Y就可以计算了,例如取向量之间的夹角,相似度越大,两个向量间的夹角越小,cos→1,计算式如下:

在实际使用过程中,可以根据实际情况,调整用于计算两个向量之间的相似程度的数学公式,对于语义相对简单的情况可以采用欧式语义距离等简单公式。欧式语义距离是在进行结构化小文本相关度计算中采用的另一种计算公式,其来源于矩阵分析、模糊数学,目的是计算多维空间中两个向量的相似程度。本文中选取的具体应用式子和其中关键参数的选择都是根据号码百事通搜索的具体需求而设计开发的。欧式语义距离计算公式如下:

其中A,B为被比较的两向量,即查询向量和查询结果向量:A=(a1,a2,…,an)和B=(b1,b2,…,bn)。相似度由计算结果倒排序,由式(3)可见,与一个向量最相似的向量为其自身,相似度的计算结果为0。
4.2 计算实例说明
应用本搜索算法,可以根据座席的输入,综合考虑历史服务经验积累、被服务信息资源特征、系统语义理解能力及后台各类相关业务的特征,计算出最符合用户信息需求的目标信息集合,以下是算例说明。
假设关键词W,经过搜索引擎扩展后形成一组查询关键词,表示为W=(W1,W2,W3,W4),经过后台算法处理后,查询目标可表示为向量X,应用搜索引擎技术在数据库中搜索,一条查询到的信息可以表示为向量Y,应用欧式语义公式,计算两个向量的相似度,相似程度的计算结果用来给查询结果进行排序。
首先,说明如何获得量化的查询向量和被查询向量。
用户查询:请给我找一家广东口味的菜馆,有包房、停车位,可以用信用卡付款。
基本查询关键词的形成:座席人员可以根据用户要求,提炼出查询关键词:广东菜、停车位、信用卡,作为输入关键词进行查询。
经过系统处理,查询关键词向量为如下:广东菜、粤菜(粤菜为广东菜同义词,系统可自动生成)、广州菜(近义词)、停车位、车位(同义词)、免费泊车(同义词)、泊车(同义词)、信用卡。
这样系统就可以表示查询向量W,查询向量再经数值化就可以形成计算向量X,数值化的过程系统根据一定的规则自动完成。W={(广东菜),(粤菜),(广州菜),(包房),(停车位),(车位),(免费泊车),(泊车),(信用卡)},X′={1.0,1.0,0.8,1.0,1.0,1.0,1.0,1.0,1.0}。
同时,存在企业A,简要介绍如下:可容纳300人同时就餐,高级包房,免费停车,可用信用卡消费。推荐菜谱:板栗煲老鸡、百合鲫鱼汤、里水金丝虾、鱼饺、炒糕。企业A的用户信息经过处理可以形成一列被比较的关键词信息,即为被查询信息,W′={(粤菜),(高级),(包房),…,(鱼饺)}。
将被查询信息与查询向量进行比较,取被查询信息中与查询向量相对应的单元形成查询结果向量。同时,根据签约情况和其他情况,为客户的被查询信息加权、数值化(系统可以根据设定自动完成)。本算例中W′与查询向量W进行比较,取{(粤菜),(包房),(停车位),(信用卡)}4 个单元进行信息比对,再进行数值化,形成被查询向量的数学表达。
在实际的系统运行中,首先是形成被查询信息的索引信息,并且形成了相应的权重系数,完成整个搜索空间的构建,然后查询向量映射到这个搜索空间,进行向量之间的比对计算。
最后,基于式(3)进行被查询信息与查询向量之间的相似度计算。例如,省略其他计算步骤,经过搜索引擎处理后一个查询向量为X=(0.7,0.8,0.2,0.9),被查询的数据库记录为两条,处理后的被查询向量为Y1=(0.6,0,0,0.5),Y2=(0.2,0.3,0.1,0.3),则应用欧式语义距离公式计算的过程如下:

由计算结果可知,Y2与X相关程度要优于Y1与X的相关程度。
系统将Y2首先返回给电信业务排序模块以便根据电信相关的业务需求以灵活排序方式对查询结果进行排序,并根据排序后的结果将其提供给用户。当然,也可以直接将Y2返回关键词查询界面以便座席人员根据搜索结果与用户进行交流,使用户获得满意的信息,之后进行自动话音报号。
4.3 结构化小文本搜索引擎结构、功能设计
结构化小文本搜索引擎的核心是应用历史服务知识及搜索引擎面向服务对象的分析,进行搜索知识的积累及应用,包括搜索请求分析、搜索扩展、相关度计算模块等,如图1所示,主要介绍如下。
结构化小文本搜索引擎系统包括:
·业务层,负责对外与业务系统的接口定义,业务逻辑所需的关键参数的输出;
·业务生成层,负责对搜索请求进行分析,调用下层搜索引擎进行搜索及实现相应的搜索逻辑;
·基础能力层,本层打包系统所需的各种基础能力,如内外部不同基础搜索引擎或先进系统的能力调用,并且可以提供搜索算法定制所需的各种基础搜索元数据的存储及调用;
·搜索服务数据及日志模块,存储搜索所需的各类数据,根据搜索请求对外提供服务,同时记录服务过程中的各类日志;
·数据挖掘及分析模块,主要提供各类对外服务报表,同时需要对服务日志进行挖掘,挖掘结果反馈给搜索引擎优化调整模块进行搜索引擎的优化调整,如自动扩展模块所需的同义词等;
·支撑层,主要定义了搜索引擎业务逻辑的应用开发接口,方便根据业务系统要求进行搜索引擎的二次开发及算法的调整定制,此外还有标准数据接口及专用数据接口供搜索引擎服务引入外部数据进行搜索服务。
对比传统搜索引擎,本系统更加强调在服务数据的搜集、整理、提炼过程中的结构化处理,以对搜索引擎进行相应的优化。其中结构化小文本的计算方法,即对文本类信息描述的实际应用,使用结构化方法确定一条信息的不同部分的小文本的描述集合对于这条信息表达和理解的作用的强弱关系。在信息搜索过程中,转化关键词查询为一组关键词或是搜索特征组成的查询向量。同时,数据库中被搜索信息根据数据模型的定义,也被表示成一组关键词或信息特征组成的向量。这样传统数据库关键词的全文检索,被转化成两组特征向量的相关度计算。根据结构化小文本的计算,可以综合算出许多数据库全文检索无法分辨的信息的排序关系,此方法有效地解决了话音服务平台对于信息的排序问题,使拨打“114”的用户信息需求和后台信息收集的方法有效地对应起来,方便信息的组织整理和应用。应用特征向量或其变体进行信息查询,还可以把服务信息的特征叠加到搜索引擎的设计及搜索服务过程中,方便地根据服务信息的种类和特性开发精准的搜索服务。

5 结束语
传统的结构化数据库检索,没有把信息的结构化定义的因素应用到信息搜索服务中,本文在搜索算法及模型的构建过程中考虑了服务信息的定义因素,在分析以“114”(号码百事通)呼叫中心为代表的话音信息服务平台服务、平台信息组织、原有基于数据库查询系统特点的基础上,结合语义搜索的最新进展,提出基于可设定信息模型条件下的结构化小文本搜索算法,在话音信息服务平台上引入了搜索引擎的设计开发思想。
在此基础上设计了以话音信息服务平台为应用领域的基于结构化小文本搜索引擎的信息搜索系统,为广大电话用户提供便捷的生活信息服务。更重要的是这种方式将搜索引擎的技术引入海量数据库检索中,可以积累搜索引擎应用过程中产生的各种知识,并应用这些知识在未来的搜索过程中,提升了搜索能力和搜索效率。未来,结构化小文本搜索引擎还需进一步根据话音信息服务平台资源类型及服务业务种类的特点,细化结构化数据的定义,构建更加精确的算法模型,完善计算调用的逻辑及相关计算权值的动态维护标准等。
1 杨震,夏艳等.基于结构化小文本的号码百事通搜索系统和方法.中华人民共和国国家知识产权局授权专利,ZL200710084911.7
2 吴立德.大规模中文文本处理.上海:复旦大学出版社,1997
3 Gudivada V N,Raghavan V V,et al.Information retrieval on the world wide Web.IEEE Internet Computing,1997,1(5):58~68
4 Salton G.A vector space model for automatic indexing.CACM,1975,18(11):613~620
5 黄萱菁,夏迎炬,吴立德.基于向量空间模型的文本过滤系统.软件学报,2003,14(3):435~442
6 Wenlei Mao,Wesley W Chu.The phrase-based vector space model for automatic retrieval of free-text medical documents.Data&Knowledge Engineering,2007,61(1):76~92
7 庞剑锋,卜东波,白硕.基于向量空间模型的文本自动分类系统的研究与实现.计算机应用研究,2001,18(9):23~26
8 唐明伟,卞艺杰,陶飞飞.基于语义向量空间模型的文档检索系统研究.情报杂志,2010,29(5):167~170,177
9 邢军,韩敏.基于两层向量空间模型和模糊FCA本体学习方法.计算机研究与发展,2009,46(3):443~451
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
物联网技术(2018年6期)2018-06-29 06:00:32
中国卫生(2015年12期)2015-11-10 05:13:38
计算机工程(2015年8期)2015-07-03 12:20:35
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
无线电工程(2014年1期)2014-06-14 01:37:28
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
