
云计算平台生存性研究
2011-06-27 02:30赵淦森王维栋季统凯
电信科学 2011年9期
赵淦森,王维栋,孙 伟,季统凯
(1.华南师范大学计算机学院 广州510631;2.中山大学软件学院 广州510275;3.广东电子工业研究院 东莞 523808)
1 引言
云计算(cloud computing)是一种计算模式,它实现了对共享可配置计算资源(网络、服务器、存储、应用和服务等)方便、按需的访问;这些资源可以通过较小的管理代价或服务提供者的交互被快速地准备和释放。云计算具有以下基本特性:按需索取、广泛的网络访问、资源池化管理和供应、快速弹性伸缩和服务度量[1]。
依据部署模型分类,云计算可以分为私有云、社区云、公共云和混合云。依据服务模式分类,云计算可以分为软件即服务 (software as a service,SaaS)、平台即服务(platform as a service,PaaS)和基础设施即服务(infrastructure as a service,IaaS)。SaaS通过浏览器把程序传给成千上万的用户。对用户来说,这个模式会省去在网络/系统软件授权和应用软件开发上的开支;从供应商角度来看,同一系统可供多次使用并多次收取使用费以实现效益最大化。Salesforce[2]即是典型的SaaS应用。PaaS可以认为是SaaS的延伸。这种形式的云计算把开发、部署环境作为服务来提供,可创建自己的应用软件并部署在供应商的基础架构上运行,然后通过网络从供应商的服务器传递给用户,例如Google App Engine[3]。IaaS提供给消费者的服务是对所有设施的利用,包括处理、存储、网络和其他基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。消费者不管理或控制任何云计算基础设施,但能控制操作系统的选择、储存空间以及应用的部署,也有可能获得有限制的网络组件 (如防火墙、负载均衡器等)的控制。典型的例子有EC2[4]、vSphere[5]等。本文的研究主要面向IaaS云。
自从Barnes等人于1993年首次提出信息系统的生存性概念开始,对于生存性的研究就开始逐渐引起人们的关注。生存性是指系统能够在遭受攻击、出现故障或意外事故后仍然能够及时完成其任务的能力[6,7]。这种能力意味着系统可以遭受入侵、部分受损,但能够保证所执行的关键任务按时完成。在这种情况下,虽然系统的安全策略失败了,但是其生存策略却是成功的。生存性是一个非常重要的系统性能参数,可以作为系统在遭受攻击、软硬件故障等意外事故后对其运行性能优劣进行评价和判定的指标。
目前国内外已有不少有关生存性的研究成果。例如Irving Vitra Paputungan等人进行的生存能力相关的恢复过程建模[8]、Andrew P.Moore等人进行的信息安全与生存性的攻击建模[9]、陈左宁进行的大规模计算机系统的可信性技术研究[10]等。云计算作为一种新兴并迅速发展的计算模式,在其先进、灵活、高效的服务理念备受赞誉的同时,云计算平台的稳定性和生存性也受到了广泛的关注。
2 生存性分析方法
目前已经存在许多进行生存性分析的方法,其中最为权威、应用最广泛的是CMU/SEI提出的SNA(survivable network analysis)[11]方法。SNA方法分为4个步骤,如图 1所示。
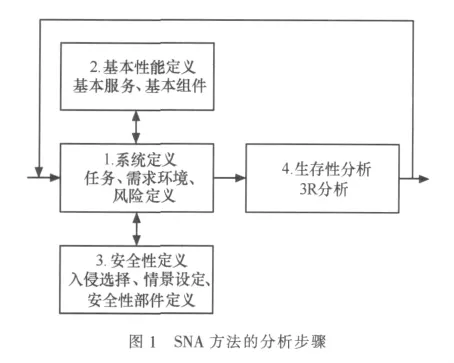
其中3R分析[12]是SNA方法最重要的部分。3R包括以下3种能力。
(1)攻击识别能力(recognition)
指系统识别攻击或者攻击扫描的能力。这种面临入侵的反应和适应的能力是系统应对攻击的核心能力。
(2)攻击抵抗能力(resistance)
指系统遭受攻击时的抵抗能力。抵抗在渗透和探测阶段比破坏发生的时候更重要。现在的抵抗策略包括防火墙、认证、加密等。
(3)系统恢复能力(recovery)
指系统在遭受攻击后恢复服务以及抵抗和识别未来潜在攻击的能力。
3 生存性机制
3.1 基础模型
云计算平台,尤其是IaaS云平台的用户所关心的,是自己所请求的云服务是否可用以及云平台发生异常后云服务能否在尽可能短的时间内恢复。对于服务提供商来说,要满足用户的需求,就必须对云平台的基础设施进行监控,避免可能发生的攻击或系统异常,并在尽可能短的时间内恢复已经停止的云服务。
依据以上分析,结合SNA方法,提出“监控—分析—决策—处理—反馈”模型,如图2所示。

监控—分析—处理—反馈模型的基本思路是:
·通过对云平台的物理设备以及必需服务进行监控,获取监控数据;
·分析监控数据,提取异常状况,分析异常状况原因和定位相关起因并生成警报;
·根据异常应对策略以及分析得到的异常原因,生成故障应对的方法,通知相关责任人;
·根据警报状况和处理方法进行自动或手动处理;
·对处理结果进行反馈,未能成功自动处理的警报将留待相关责任人手动处理。所有未能成功处理的警报都将重新提交至处理环节。
3.2 生存性机制
本文提出的生存型机制基于虚拟机的在线迁移,而虚拟机迁移的基础则是虚拟化技术。
虚拟化[13]是IaaS云平台的基础,通过在物理设备和应用服务之间加入虚拟化层,使得应用服务不再依赖于固定的物理设备。应用服务由此可以在不同物理设备间迁移。大部分IaaS云平台提供的计算资源粒度是虚拟机。
当某台物理设备遭遇外部攻击、系统异常或硬件异常时,系统在进行异常应对过程中,需要将运行于有风险或异常的物理设备上的虚拟机迁移[15]至其他状态正常的物理设备。迁移后的虚拟机的状态与迁移前保持一致,从而保证了云平台能够在不影响服务可用性的前提下把云服务从有风险或异常的物理设备转移到稳定的物理设备之上,避免了云服务因为系统异常或硬件异常而失效的风险。
虚拟机的迁移有离线迁移和在线迁移两种。离线迁移过程需要把虚拟机暂停,从而虚拟机承载的服务也将停止。系统通过把暂停后的虚拟机的状态和数据同步到目标的机器后,再把虚拟机重新运行。在线迁移在不需要暂停虚拟机的前提下,把在运行状态的虚拟机的状态和数据同步到目标机器,然后在关闭原来的虚拟机的同时启动目标机器上的虚拟机。
当某台物理设备因为系统异常而不可用,则它的物理资源对于云平台来说是失效的。本生存性机制通过向运行于该物理设备上的控制器发送命令,恢复该物理设备上异常的系统服务或重启设备,使物理设备恢复为可用状态,从而实现云平台自动恢复失效物理资源的能力。
当没有提供处理预案的异常发生,或者异常自动处理失败时,本生存性机制能够通过用户界面通知相关责任人,也可以调用第三方监控软件的相关功能,通过E-mail、短信等方式通知相关责任人手动处理异常。
3.3 物理设备运行状态建模
通过对物理设备运行状态进行建模,可以明确物理设备运行状态正常与否的标准,并为各种可以预期的外部攻击、系统异常或硬件异常提供有针对性的处理预案。当部分物理设备遭受攻击、发生或可能发生异常时,云平台可依据处理预案做出响应,并执行对应的指令,从而在无需人工干预的情况下,处理大部分可预期的攻击和系统异常,保证云服务的正常运行。
对物理设备运行状态进行建模,首先需要依据该物理设备的功能来制定监控计划,界定需要监控的硬件状况、必要服务和资源使用情况,生成监控项;然后对每个监控项制定判定异常发生的标准以及异常的级别;最后针对各个监控项的异常状态提出对应的处理预案。下面是一个简单的例子。
节点主机指运行节点控制器(node controller,NC)的物理主机,提供云平台实际物理资源并管理运行于其上的虚拟机。针对该类物理机进行运行状态建模见表1。

表1 节点主机运行状态建模
与上例类似,也可以用同样的方法对云平台内的其他物理设备进行运行状态建模。完成对所有类型的物理设备的运行状态建模工作并将这些模型整合后,就得到了云平台的运行状态模型。云平台内的任何一个物理设备都可以映射到云平台运行状态模型中对应的物理设备运行状态模型。所以,对云平台内物理设备的监控数据的分析就转化为对该物理设备的实时运行状态模型和正常运行状态模型的匹配,对云平台的监控数据的分析也就转化为对云平台实时运行状态模型和云平台正常运行状态模型的匹配。
3.4 异常应对
当云平台中某台物理设备的实时运行状态模型和云平台正常运行状态模型的匹配失败时,该物理设备将被判定为有风险的物理设备。本生存性机制将通过匹配过程得到匹配失败的具体监控项,并根据该监控项的实时监控数据得到发生的风险或异常的严重程度,严重程度较高的风险或异常将被优先处理。
在处理风险或异常时,本生存性机制从该物理设备的运行状态模型中获取与当前异常对应的处理预案。依据处理预案,本生存性机制对异常处理方法进行决策,具体可以分为以下两种情况。
第一种,应对必要服务状态异常、存储空间不足等问题,本生存性机制通过向该物理设备上的控制器发送相应的处理指令来解决异常。
第二种,当设备负荷过重、资源利用过高、硬件状况异常、遭受或可能遭受外部攻击时,本生存性机制将运行于该物理设备上的虚拟机迁出。对于设备负荷过重、资源利用过高、硬件状况异常等问题,将虚拟机迁出可以有效保证虚拟机内部署的应用不会因为这些问题而变得效率低下或中断。对于虚拟机遭受或可能遭受外部攻击的情况,将该虚拟机迁出并更新相应配置可使外部攻击失去目标,从而防止因为外部攻击导致的虚拟机内的应用中断或数据泄漏。
本生存性机制依据以下几个原则来进行虚拟机迁移目标的决策。
原则一:当用户无特殊要求时,将虚拟机迁移到哪个物理设备由云平台当前所应用的自动调度策略决定。这些自动调度策略可能包括节能策略、最小需求策略、高性能策略等。
原则二:当用户有安全性需求,或需要迁出的虚拟机对物理设备的架构有所要求时,本生存性机制将允许用户制定相应的迁移规则(例如某个部署敏感应用的虚拟机只能被迁移到指定网段的物理设备等),并在迁移规则允许范围内应用云平台现有的自动调度策略决定虚拟机迁移的目标。
原则三:用户手动指定迁移目标。完成对异常处理方法的决策后,本生存性机制原型向异常发生的物理设备上的控制器发送对应指令,并获取指令执行结果。参考§3.1中提出的“监控—分析—决策—处理—反馈”模型,当异常处理失败时,其警报将被重新提交到处理环节,留待用户手动处理。
4 原型架构设计
4.1 整体架构
依据上文提出的生存性机制,进行原型的整体架构设计。为了实现预想功能,整体架构设计需要包括监控、分析、处理、反馈4个方面,此外,监控项目和处理方法应该具有可定制性,以期适应不同的监控需求。本原型将分析、处理、反馈以及可定制性进行整合,得到云监控(cloud monitor)模块。监控功能通过使用第三方开源监控软件Nagios[14]实现,实现可定制性需要与用户界面交互,实现自动处理功能需要与其他云平台的其他控制器(controller)交互。综合考虑以上各个方面,得出生存性方案的整体架构如图3所示。
云监控模块与底层监控软件Nagios运行于云监控主机上,通过插件监控状态读取插件和配置器控制底层监控软件Nagios。Nagios则通过调用运行于远端受监控主机上的NRPE插件实现对远端主机的实时监控。云监控模块通过与用户界面交互来提供可定制性,通过与其他云平台控制器交互来实现警报自动处理功能。对该架构进行详细分析如下。
(1)部署情况
云监控模块和底层监控软件Nagios均部署在云监控主机上,Nagios的远程监控插件NRPE则部署在所有被监控主机上。
(2)云监控模块结构
为保证能够独立稳定地运行,且尽量少地受到操作系统的影响,云监控模块被设计成Daemon进程(即守护进程,是一种后台服务进程,通常生存期较长并独立于控制终端。常用于周期性地执行某项任务,等待处理某些可能发生的事件),在云监控主机启动时加载并开始监控服务。

(3)通信方式
云监控模块通过基类已实现的套接字(socket)接口与用户界面和云平台其他控制器进行通信。Nagios与其插件NRPE之间的通信则依靠SSL(secure sockets layer,安全套接字,是Netscape为保证网络通信安全及数据完整性提出的一种安全网络通信协议,SSL在传输层对网络连接进行加密以实现通信安全)协议实现。
(4)云监控模块与底层监控软件的关系
出于可扩展性考虑,云监控模块与底层监控软件没有包含或直接调用关系。二者的交互通过插件完成。如果需要用其他监控软件代替现有的Nagios,云监控模块将无需修改,仅针对新的监控软件开发相关插件即可实现兼容。
(5)云监控模块插件
云监控模块通过相关插件与底层监控软件交互。插件包括监控状态读取插件和配置器。监控状态读取插件用于读取并规格化底层监控软件监控数据。配置则用于配置底层监控软件参数并重启监控服务以应用改变。
4.2 云监控模块架构设计
根据本文提出的生存性机制和§4.1中的分析设计,设计云监控模块的基本运行流程,如图4所示。

云监控运行流程分为以下几个步骤。
(1)监控
通过控制第三方监控软件远程监控各个服务器,并生成状态记录。云监控模块读取监控状态记录。
(2)分析
分析监控数据,建模并匹配,对异常状态生成警报,并通知维护人员。
(3)处理
尝试依据警报自动处理预案处理警报。
(4)反馈
获取自动处理结果,处理失败的警报留待维护人员手动处理。维护人员手动处理后通过用户界面通知云监控模块。
警报处理预案一般分为以下几个类型。
·向发生警报的主机发送对应指令,解决系统相关服务异常等问题。
·应用自动迁移策略,将运行于异常节点主机的虚拟机动态迁移[15]到正常运行的节点主机上。

·延迟处理警报,留待维护人员手动处理。
依据以上分析,设计云监控模块架构如图5所示。
对云监控模块的各个子模块功能分析如下。
(1)状态分析器
监控循环中,从监控状态文件读取已规格化的监控数据,依据物理机类型生成运行状态模型,与对应的正常状态模型进行匹配,对匹配失败的监控项生成警报,依据警报优先级将警报插入警报队列。
(2)警报队列
存储现存的所有未处理警报,队内警报按优先级降序排列,需手动处理的警报将被视为最低优先级警报并置于队尾。
(3)用户界面控制器
管理与用户界面的交互,包括监控策略管理、警报管理和监控服务的启动与停止。
(4)策略控制器
云监控模块启动时,调用数据库接口读取监控策略,并对云平台不同类型的物理机分别建立正常状态模型,监控策略变更时,更新数据库和正常状态模型,调用配置器配置并重启底层监控软件。
(5)警报处理器
从警报队列依次取出警报,依据预置自动处理预案向其他云平台控制器发送命令并获取返回结果。分析返回结果,处理成功则从警报队列删除警报,处理失败则更改警报类型和优先级,然后再次插入警报队列,完成后调用数据库接口更新数据库。
(6)数据库接口
管理数据库操作。
(7)日志接口
对云监控模块的所有关键操作进行日志记录。
5 生存性机制原型的应用
本文提出的生存性机制的原型的具体应用和测试平台为Vebula私有云基础设施平台。Vebula云计算基础设施平台是一个提供系统虚拟化、资源整合、按需提供虚拟化资源、安全验证等服务的云计算解决方案。其核心架构如图6所示。
Vebula私有云基础设施平台的核心架构主要分为以下几个模块。
(1)云控制器(cloud controller,CLC)
通过与Vebula Web进行交互,来接受和反馈用户请求。负责云平台的最高层统一调度。
(2)集群控制器(cluster controller,CC)
转发CLC的事件请求,收集并上报集群信息,管理属于本集群的节点控制器。


表2 可用性机制原型应用前后对比
(3)节点控制器(node controller,NC)
相应上层发出的事件请求,管理节点主机上运行的虚拟机(VM)和其他虚拟化资源,收集并上报节点主机及节点主机上运行的虚拟机信息。
(4)DHCP 控制器(DHCP controller,DC)
提供DHCP服务,管理云平台的IP资源。
(5)存储设备(storage)
存储云平台的内部数据,包括数据库、虚拟机镜像、用户虚拟磁盘等。
下面,通过举例若干个Vebula私有云基础设施平台可能发生的异常来对比说明应用本文提出的可用性机制原型前后,云平台应对异常的情况。具体举例见表2。
6 结束语
本文通过分析IaaS云计算平台的生存性问题,确立了IaaS云计算平台的生存性需求,并提出了基于虚拟资源迁移的生存性机制。在设计并实现了该生存性机制的原型后,将其整合进已有的Vebula私有云基础设施平台并进行了测试。
测试证明,该生存性机制原型能较好地应对系统异常和硬件异常。在出现发生部分可预期的异常的趋势时,该原型能够将虚拟机由可能发生异常的物理设备迁移到正常运行的物理设备。当异常已经发生时,该原型能够在很短时间内监测到异常,并通过迁移、重启系统服务等方式自动解决异常。当出现无法自动解决的异常时,该原型也能够及时通过用户界面以及第三方监控软件提供的E-mail、短信等方式通知相关责任人手动解决异常,从而较好地保证了云服务的可用性,大大提升了云计算平台的生存性。
在目前工作的基础上,本文提出的生存性机制可以在攻击检测和攻击避免方面进行扩展,通过整合IDS等第三方入侵检测软件并在生存性机制中加入应对外部攻击的迁移策略,可以提升云计算平台抵御外部攻击的能力,进一步提升云计算平台的生存性。
1 Peter Mell,Tim Grance,The NIST definition ofcloud computing,national institute of standards and technology,http://csrc.nist.gov/groups/SNS/cloud-computing/,2010
2 Salesforce,http://www.salesforce.com/,2011
3 Google App Engine,http://en.wikipedia.org/wiki/Google_App_Engine,2011
4 EC2,http://aws.amazon.com/ec2/,2011
5 Vsphere,http://communities.vmware.com/community/vmtn/vsphere,2011
6 Hollway B A,Neumman P G.Survivable computer-communication systems:the problem and working group recommendations,Washington:US Army Research Laboratory,1993
7 Ellison R J,Fisher D A,Linger R C,et al.Survivable network system:an emerging discipline,Tech ReportCMU/SEI-97-TR-013,Pittsburgh,Software Eng Inst,Carnegie Mellon Univ,1997
8 Irving Vitra Paputungan, Azween Abdullah. Survivability assessment:modeling a recovery process,seminarnasional aplikasi teknologi informasi,2007
9 Moore A P,Ellison R J,Linger R C.Attack modeling for information security and survivability,technicalnote CMU/SEI-2001-TN-001,2001
10 陈左宁.大规模计算机系统可信性技术的研究.高性能计算技术,2004(6)
11 Mead N R,Ellison R J,Linger R C,et al.Survivable network analysis method.Carnegie Mellon University,2000
12 Lin Xuegang,Xu Rongsheng,Zhu Miaoliang.Survivability computation of networked information systems.Computer Science,2005(3802):407~414
13 Intel开源软件技术中心,复旦大学并行处理研究所.系统虚拟化—原理与实现.北京:清华大学出版社,2008
14 Nagios.http://www.nagios.org/,2011
15 Liu Pengcheng,Yang Ziye,Song Xiang,et al.Heterogeneous live migration ofvirtualmachines,internationalsymposium on computer architecture,2008
猜你喜欢
卫星应用(2022年3期)2022-05-23
电子制作(2019年22期)2020-01-14
科普童话·百科探秘(2019年8期)2019-09-18
信息记录材料(2018年11期)2018-02-21
少儿科学周刊·少年版(2018年12期)2018-01-26
电子科技大学学报(2017年5期)2017-11-21
Coco薇(2017年8期)2017-08-03
软件(2016年6期)2017-02-06
数码世界(2016年2期)2016-12-31
黑龙江工程学院学报(2015年5期)2015-12-04
