
基于权重的流数据频繁项挖掘算法的应用
2011-05-11 11:58杨立
网络安全与数据管理 2011年2期
杨 立
(运城学院 公共计算机教学部,山西 运城044000)
基于计数的频繁项挖掘算法适用于每个数据元组所含知识相等或近似的情况,例如用户在网页上的点击流,搜索引擎的关键词流、路由器上的IP包流等情况。但在更多的情况下,每个事务代表的知识是不相等的。如电信系统中的通话记录,每个用户的电话用时是不相同的;在证券交易中心,每笔交易的金额也是不同的。许多小客户的事务数多,但每笔事务的权值很小;重要的大客户事务数虽少,但每笔事务的权值很大。如果此时用原有的频繁项挖掘算法,将不能很好地体现那些事务数少但重要性高的客户。而采用新的基于权重的算法,则可以很好地找出那些重要性高的元素。
本文提出的基于权重的新算法是对原有Lossy Counting[1]的扩展。不仅可以解决基于计数的频繁项挖掘问题,还能解决基于权重的频繁项挖掘问题。并且Lossy Counting算法本质上是新算法的一个特例(窗口定长,权值为1)。新算法在应用域上超出了原有算法,甚至可支持基于计数与权重的混合查询。
1 Lossy Counting算法
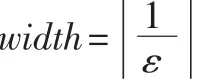
算法数据结构为三元组(e,f,Δ)的集合D。其中 e表示为流中的元素,f为估计的计数,Δ为f可能的最大误差。D初始为空,每当有一个新元素e到达时,首先在D中查找是否已存在包含e的元组。若存在则对应的该元组计数 f加 l;否则创建一个新的元组(e,1,bcurr-1)。当到达窗口边界时,对 D进行如下裁剪:若元组(e,f,Δ)满足f+Δ≤bcurr,则删除该元组。当查询到达时,返回所有 f≥(s-ε)N的元组。
2 Lossy Weight算法
本文提出的基于权重的频繁项挖掘算法(Lossy Weight Algorithm)与原有算法有着相同的定义:根据用户定义的门槛参数s∈(0,1),输出在整个流数据中所占权重比重大于s的所有元素。
新算法同样满足实时性的要求。在任意时间内,用户都可以提交查询,算法的结果满足以下的要求:(1)数据所有占权重比超过s的元素都被输出;(2)所有占权重比小于 s-ε都不会被输出;(3)权重频繁项的误差至多为ε。
新的算法保持了原有的Lossy Counting实现简单、处理速度快的特点。同样地,在误差的精确控制上有这样两 个 特 点[2]:(1)存 在 误 报 可 能(false positive);(2)误 报 的误差可控制。
2.1 Lossy Weight算法实现
新算法有如下的定义:用户必须明确地指定门槛参数s和误差参数ε,并且定义流数据当前大小为N。

初始,D=φ,Vb-1=0。
当一个新元素e到达时,将e的权值Wi加入计数器V,之后对D进行更新操作。首先查找D中是否存在e。如果存在,将e的权值加入W。否则新建成员(e,Wi,εVb-1)。
在窗口的边界,对D进行裁剪。裁剪的规则很简单,当 W+Δ≤εV时,即从 D中删除该元组。裁剪后,更新Vb-1的值为当前的V。当查询到达时,返回所有W≥(sε)N的元组。
2.2 新算法的优势

3 Lossy Weight算法的实验分析
3.1 Lossy Weight算法的特性实验
本文采用国泰君安CSMAR(China Stock Market Accounting Research)系列数据库中的中国股票交易高频数据库作为实验数据[3]。本实验采用了上海证券交易所2009年12月5日~12月7日三天的股票交易高频数据。日均20万条交易记录,总计为590 233条交易计录。在流数据频繁项挖掘实验中,将数据按时间排序,并模拟其实时到达的特性,对送达流数据处理引擎进行频繁项挖掘。
对整个交易日所有个股的交易信息采用LW算法进行数据处理,对交易量所占比重大于l%的个股进行频繁项挖掘,然后对内存使用情况进行分析。原有的LC算法不能处理带权重的挖掘任务。在实验中,定义了不同窗口大小,并对其进行了分析。
图1所示实验是在s=l%、ε=0.1%情况下,截取交易日前5 000个数据的内存使用情况进行对比。实验显示,LW算法的窗口尺寸越小,裁剪次数越频繁,则内存使用效果越好。但过多的裁剪无疑会加大系统的负荷。所以可以根据系统的负载大小来合理地确定窗口宽度。LW算法中窗口尺寸的可伸缩性使得算法适应能力更强。

LW算法的内存占用情况取决于窗口尺寸和错误容许度s的大小。容许的错误度越大,内存使用情况就越好。在窗口大小相等的情况下,对不同的错误容许度进行频繁项挖掘。
图2显示了在相同窗口大小(width=1 000)情况下,不同ε的内存占用情况。实验显示,LW算法对内存空间的需求与误差ε-1近似成正比。因此,在不影响最终决策的前提下,错误容许度ε越大越好。
3.2 LW算法对LC算法的对比实验
Lossy Weight算法是对Lossy Counting算法的改进。在应用上有更广的范围,在原有的问题领域,新算法同样占有优势。LC算法的窗口大小是固定的ε-1,LW算法的窗口是动态的,可以应对任意窗口大小。这就可以面对更复杂的应用情况。在数据流量大时,扩大窗口尺寸,能起到批处理的效能。当系统较空闲时,减少窗口尺寸,以得到更好的内存使用情形。
如图3所示,在实验中,截取交易日前5 000个数据的内存使用情况进行对比。实验设置LW窗口大小为LC大小的一半。在第一个窗口,可以看到LW算法与LC算法的内存占用是相同的。但到窗口边沿时,裁剪后的内存占用得到明显的下降。通过对整个流的处理对比,可以明显地看出LW算法具有更好的内存使用情况。

本文提出了一种新的基于权重的流数据频繁项挖掘算法。扩展了流数据频繁项的作用域。Lossy Weight算法不仅可用于传统的基于计数的频繁项挖掘,还可以挖掘出在整个流数据中所占权重比重大于门槛值的数据。

[1]MANKU Q S,MOTWANI R.Approximate frequency counts over data streams[C].Proc.of the 28th Intl.Conf.on VeD,Large Data Bases.Hongkong:MorganKaufmann,2002:346-357.
[2]潘云鹤,王金龙,徐从富.数据流频繁模式挖掘研究进展[J].自动化学报,2006,32(4):594-602.
[3]朱世武,严玉星.金融数据库[M].北京:清华大学出版社,2007:12-14.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
电脑报(2021年14期)2021-06-28
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
广西科学(2020年3期)2020-08-02
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
