
基于谱聚类和多示例学习的图像检索方法*
2011-03-21 08:06:30李展彭进业2温超
华南理工大学学报(自然科学版) 2011年7期
李展彭进业,2温超
(1.西北大学信息科学与技术学院,陕西西安710069;2.西北工业大学电子信息学院,陕西西安710072)
传统的基于内容的图像检索(CBIR)通过图像特征度量整体相似性来实现[1];而基于对象的图像检索(OBIR)只关心那些包含特定对象的图像.由于OBIR更适应用户检索需求,因此已成为CBIR新的研究热点[2].
针对OBIR,一种方法是以“视觉词袋”(BoW)模型为基础,获取图像感兴趣区域的尺度不变特征变换(SIFT)特征[3],利用BoW模型进行图像检索.Zheng等[4]从文本检索中得到启示,提出基于视觉词组的检索方法.Philbin等[5]通过获取局部几何空间特征提高检索性能.Wu等[6]利用多样本多树方法解决了特征检测、提取和量化步骤中的信息损失问题.另一种方法基于多示例学习(MIL)框架,利用MIL实现图像检索.Dietterich等[7]在药物活性预测的研究工作中,于1997年首次提出MIL的概念.传统机器学习框架中训练样本与标记是一一对应的,而MIL问题中,训练样本包有多个示例,只有包具有标记.若包中有正示例,则标记为正,反之标记为负.如对图像进行分割,将图像与分割区域分别看作包和示例,包含有检索对象的图像标为正包,否则标为负包.利用已标记正负图像学习分类器并进行检索,则基于对象的图像检索就变成了多示例学习问题.Zhang和Rouhollah等[8-9]结合多样性密度(DD)函数和期望最大值算法(EM),利用EM-DD算法对图像检索进行研究.Chen等[10-11]提出了DD-SVM与MILES两个经典MIL算法,通过构造空间,将多示例包非线性投影并嵌入到构造空间中,利用支持向量机(SVM)求解MIL问题.Wang等[12]受基于图的半监督学习算法的启发,提出了GMIL算法,该算法定义包含标记数据、半标记数据和未标记数据的代价函数,并对该代价函数进行迭代优化.Fu等[13]则利用交替迭代方法选择示例,完成图像检索.
要实现高效的对象图像检索任务,需解决如下3个主要问题.(1)适合图像检索的特征和图像检索模型选择问题;(2)图像标注复杂度和检测对象区域问题:要获得带有明确标记的训练样本和指定检测对象区域,均依赖人工指定,效率不高;(3)检索效率问题:检索系统需实时反应用户,并返回满足查询要求的图像.基于BoW模型的方法中,SIFT特征获取和匹配的时间复杂度都非常高,而且需要预先指定检索对象区域,因此并不是最好的解决方法.本研究以多示例学习模型为基础,设计了一种新的对象图像检索算法SCPMK-MIL(Spectral Clustering and Pyramid Matching Kernel for Muti-Instance Learning).该算法首先在正包示例集合内进行谱聚类(SC),基于聚类中心点数最大原则选择潜在正示例代表,将包内其它示例相似性视为多部分相似问题,分别使用径向基函数(RBF)和金字塔核(PMK)度量相似性,然后利用SVM学习分类器模型并实现图像检索;相关反馈技术可以大大提高检索性能[14],因此最后进行相关反馈.
1 SCPMK-MIL算法
1.1 潜在正示例代表的选择
假设要训练一个针对对象z的MIL分类器,标注图像集为L={(B1,y1),(B2,y2),…,(Bs,ys)},其中,yi∈{-1,+1},i=1,2,…,s,这里+1表示图像中包含对象z,而-1表示不包含对象z.在集合L中,前m个包为正包,标记为yi=+1,后l个包为负包,标记为yi=-1,满足s=m+l.未标注图像集为U={Bs+1,Bs+2,…,Bs+p},其中p为图像集U中包的个数.设图像Bi被分割成ni个区域,每个区域对应的视觉特征向量记作x ij∈Rd,d表示视觉特征向量的维数,则称为MIL训练包,x ij为包中示例.将yi=+1的包内示例排在一起,称为正包示例集合,记作
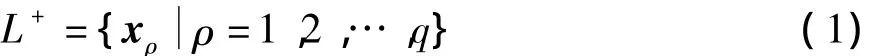
式中,q表示正包中示例的总数
传统的聚类算法,如k-means算法和EM算法,都是建立在凸球形的样本空间上.当样本空间不为凸时,算法会陷入局部最优.而谱聚类能在任意形状的样本空间上聚类,且收敛于全局最优解,因此本研究选择谱聚类NJW算法[15]进行聚类,以获取潜在正示例代表.
谱聚类算法的思想来源于谱图划分理论,假定将L+中每个示例看作图中的顶点V,根据示例间的相似度将顶点间的边A赋权重值w,这样就得到一个基于示例相似度的无向加权图G=(V,A).那么在图G中,就可将聚类问题转化为图G的划分问题.为了求解该划分问题,可将问题转化为Laplacian矩阵的谱分解,从而实现对图划分准则的逼近[16].
谱聚类算法步骤为:首先根据给定的样本数据集定义一个描述成对数据点相似度的亲合矩阵,并计算拉普拉斯矩阵的特征值和特征向量,然后选择合适的特征向量进行聚类.
定义1(亲合矩阵W)给定集合L+中的任意两个示例x i、x j,其权重定义为
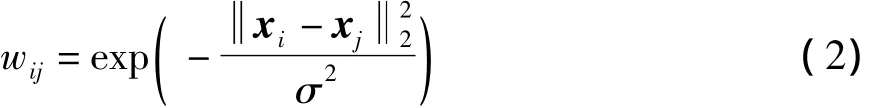
式中,σ为事先指定参数.
定义2(度矩阵D)度矩阵D为对角阵,其对角元素值为亲合矩阵W的行元素之和,其余元素为0.

定义3(规范Laplacian矩阵L)规范Laplacian矩阵定义为

式中I为单位矩阵.
文中采用聚类中心点数最大原则,即对正示例集合L+进行k聚类,计算聚类样本的中心{o1,o2,…,ok}.统计每个聚类所包含的正示例点数{c1,c2,…,ck},认为包含点数最多的聚类中心点为潜在正示例中心.选择包Bi中和该聚类中心距离最近的示例作为包Bi的潜在正示例代表.
定义4(聚类中心O)对正包示例集合L+进行k聚类,获得k个不相交的子图Gj,j=1,2,…,k.示范函数I(·)判断x i是否属于子图Gj,定义为
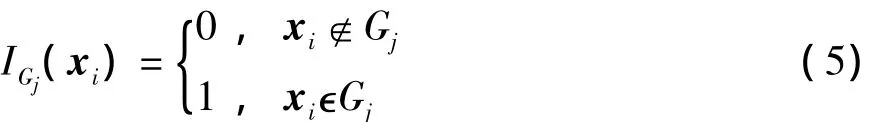
则聚类中心向量O中分量O j可由下式计算:
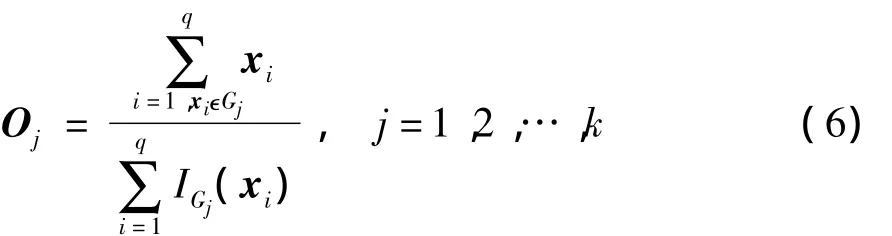
定义5(潜在正示例中心)统计子图Gj的正示例点个数,假定点个数最大的子图为Gh,则O h为潜在正示例中心.定义N(j)为统计子图Gj的正示例个数函数,C为子图Gj中所含示例点个数向量.C的分量Cj的计算公式为
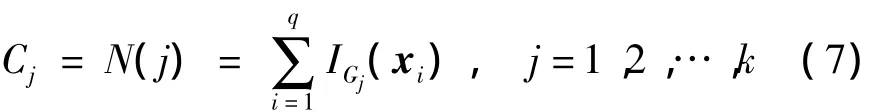
若
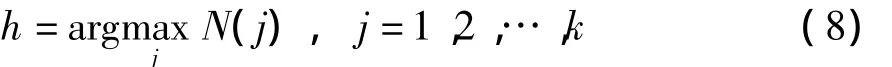
则O h为潜在正示例中心.
定义6(潜在正示例代表)通过式(7)得到潜在正示例中心O h后,包Bi和O h距离最近的示例x ir称为潜在正示例代表.其中,
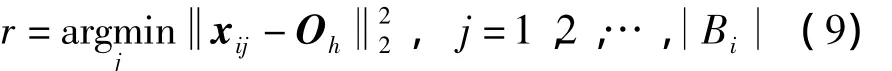
基于以上定义与聚类中心点数最大原则,构造潜在正示例代表集合的算法1的步骤描述如下.
输出:潜在正示例代表集合γ.
1)以L+为集合,用式(2)计算亲合矩阵W.
2)利用公式(3)和(4)分别计算度矩阵D和规范Laplacian矩阵L.
3)计算矩阵L前k个最大特征值所对应的特征向量x1,x2,…,x k,构造矩阵X=[x1x2…x k].
4)将矩阵X的行向量归一化,转变为单位向量,得到矩阵Y,其元素
5)将矩阵Y的每一行看作Rk空间中的一个点,使用k-means算法进行聚类,得到k个不相交的子图Gj,j=1,2,…,k.
6)利用式(6)和(8)计算聚类中心和潜在正示例中心.
7)对∀Bi∈B,利用式(9)计算潜在正示例代表x ir,进行如下操作:
(1)将x ir加入集合γ;
(2)从集合B中删除Bi.
8)如果B非空,则跳转本算法步骤7);否则,输出γ,算法结束.
1.2 SCPMK-MIL核函数的计算
SIFT匹配问题是标准的多部分相似问题.针对SIFT相似问题,相应的核方法得到了广泛的研究和应用.其中Kristen等[17]提出的金字塔核最为有效;其构造多解析直方图,在直方图金字塔基础上,通过权重组合直方图重叠值构造核函数.
文献[17]定义核函数
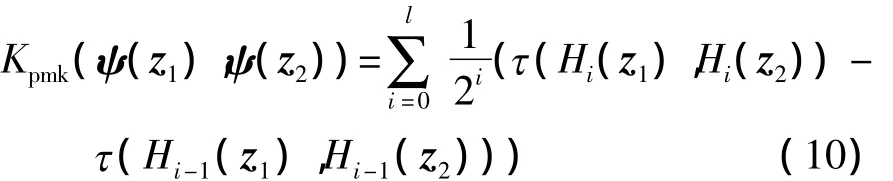
式中,z1、z2为两个SIFT特征,Hi(x)为投影的第i级直方图,ψ(x)=[H0(x),H1(x),…,Hl-1(x)],τ(·,·)为直方图的重叠值.
由算法1得到正示例代表集合γ={γ1,γ2,…,γs+p}.SCPMK-MIL核函数定义为
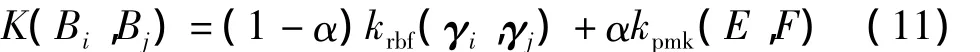
式中:krbf为RBF核函数;kpmk为金字塔核函数;α为krbf对核函数K的影响因子,满足1>α>0;集合E和F分别满足E∪γi=Bi和F∪γj=Bj.
SCPMK-MIL核矩阵K元素Kij的计算方法为:利用算法1,获取包集合B=L∪U的潜在正示例集合γ,对MIL中的包Bi和Bj分别去掉潜在正示例代表γi和γj,生成新集合E和F.利用公式(11)计算核矩阵K.构造核矩阵K和其元素Kij的算法2的具体步骤如下.
输入:潜在正示例代表集合γ,集合B=L∪U,正比例系数α.
输出:核矩阵K.
1)任取B中的两个包Bi和Bj,令E=Bi-{γi},F=Bj-{γj};
2)利用式(11)计算K(Bi,Bj),并赋值给Kij;
3)如果未遍历完B中所有包,则跳转本算法步骤2);否则输出K,算法结束.
1.3 SVM分类及相关反馈
SVM利用最大化margin思想,寻找保证正确分类情况下的最大间隔.其优化目标为
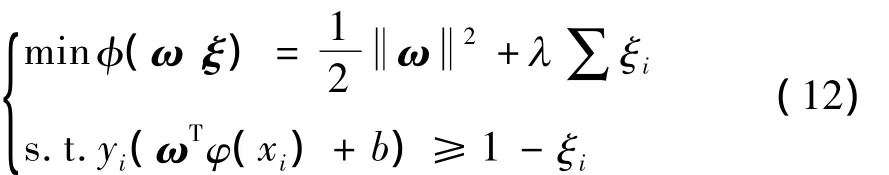
式中:{xi,yi}为训练样本(i=1,2,…,t),t为训练样本总数;ω为分类面法向量;ξi为松弛变量;φ(·)为由低维到高维的映射函数;b为偏移量,b∈R;λ为惩罚因子,如λ=∞则为线性可分情况,否则为线性不可分情况.
利用拉格朗日和Wolfe对偶理论,优化问题变形为
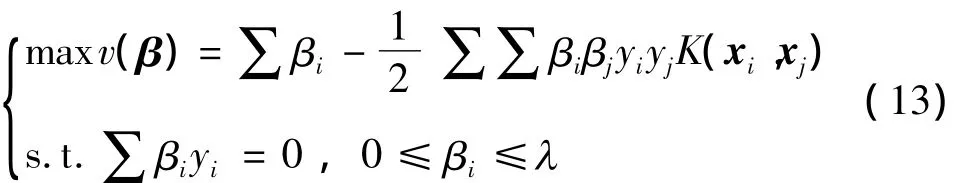
式中,βi为拉格朗日乘子,此处核函数K用算法2计算.
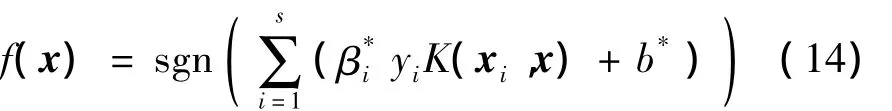
式中:{x i,yi}∈L,x∈U.
基于SVM的相关反馈方法是一个交互式检索过程.本研究在反馈时,用户每次从检索结果中标记正例和反例,以增加训练图像数,从而不断调整在希尔伯特空间中的SVM超平面,直至达到反馈次数要求.
最后将本研究提出的SCPMK-MIL对象图像检索(算法3)步骤总结如下.
输入:已标注图像集L、测试图像集U(即未标注图像集)、k和α,反馈次数n,用户反馈正负图像个数h+和h-.
输出:测试图像集U的标记
1)构造MIL训练包:对∀Bi∈B,B=L∪U进行图像分割,若分割为ni个区域,则相应的MIL训练包记为,其中x ij∈Rd,表示相应的图像特征(即包中示例).
6)用户从集合R中选择h+个图像作为正例集合Z+,从集合S=U-R中选择h-个图像作为负例集合Z-,从而生成反馈训练集Z=Z++Z-.
7)将反馈所得正负集合加入已标注图像集L,令L=L∪Z,测试图像集U=U-Z.若反馈次数未达到n次,则转本算法步骤2);否则算法结束.
2 实验结果与分析
2.1 图像库及实验方法
选用SIVAL图像集进行对比实验(http:∥www.cs.wustl.edu/accio/),该图像集由1 500幅图像组成,包含25类不同物体,每类60幅图像.实验中每幅图像被预先分割成约30个不同区域,在每个区域提取其30维的颜色、纹理和近邻的底层视觉特征,细节请参阅文献[9].实验平台为:AMD4200+处理器,1GDDR800内存,Windows XP操作系统,以及Matlab7.01仿真环境.
SVM的代码来自LibSVM软件包(http:∥www.csie.ntu.edu.tw/~cjlin/libsvm/),采用“one-vsrest”处理多类问题,具体方法是:在每次实验中,从每类图像中随机选取20幅作为潜在训练集正例,其余1000幅作为待检索图像;每次实验时,将某一类作为检索目标,从该类的潜在训练集正例中随机选择6幅生成正训练包,再从其它类中随机选择6类,每类随机选择1幅不感兴趣的图像,生成负包,组成包含6个正包和6个负包的训练集.金字塔核的代码来自Grauman的主页(http:∥www.cs.utexas.edu/~grauman/).算法2中RBF和PMK参数采用“2-fold交叉检验”的方法获取.因为AUC值(即ROC曲线下的面积)能够刻画检索结果排序的优劣,本研究采用它来评估算法的性能.
2.2 参数k和α对算法性能的影响
SCPMK-MIL算法中,谱聚类的聚类数k及核函数中的正比例系数α必须预先设置.为了验证k和α对检索精度的影响,设置k从1变化到9,步长为1;α从0.1变化到0.9,步长为0.1.基于GreenTeaBox类图像,按照1.3节所述算法3进行实验.图1(a)为α=0.2时k对平均AUC值的影响.图1(b)为k=5时,α对平均AUC值的影响.
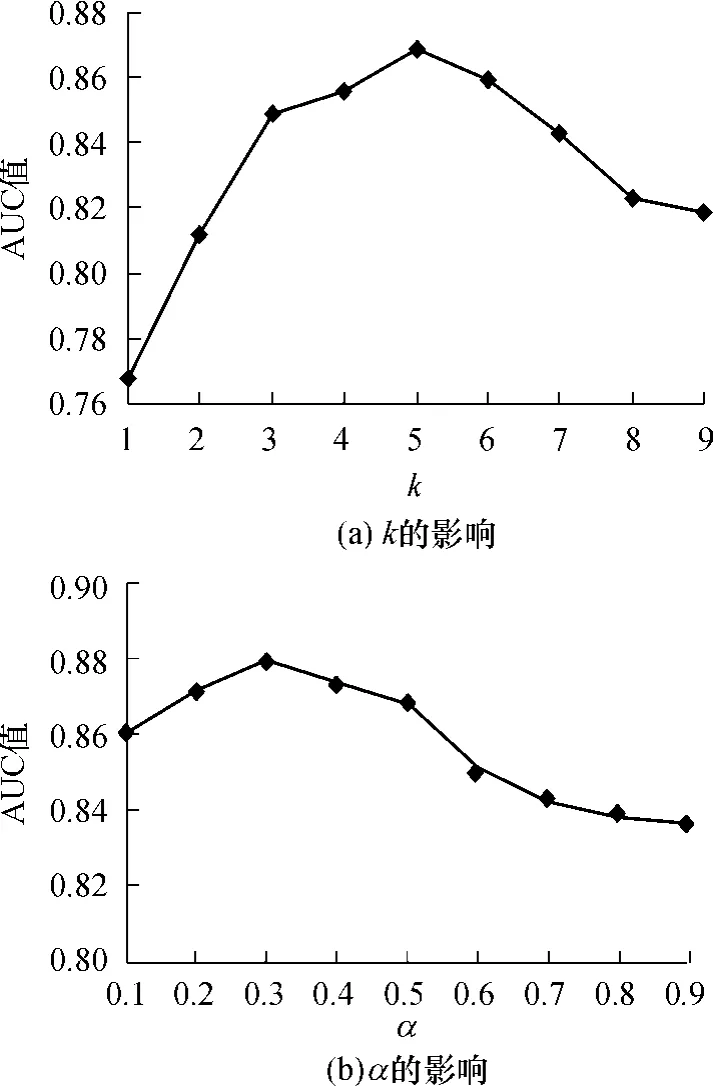
图1 在图像GreenTeaBox上k和α对SCPMK-MIL算法性能的影响Fig.1 Effects of k andαon the performance of SCPMK-MIL algothrim for GreenTeaBox
如图1(a)所示,当k从1增至9时,AUC值介于0.768到0.869之间,k=5时AUC值达到最大值0.869.由此可见,SCPMK-MIL算法的性能受k的影响较大.其主要原因是:在对象图像检索中,对象经常和几个特定的其它物体具有特定的共生关系.图2为GreenTeaBox的部分图像,由图可见GreenTea-Box通常和板凳、报纸、桌子、地面出现在同一幅图像中.那么,在进行k=5聚类时,潜在正示例中心必然是GreenTeaBox对象特征的中心,因此利用k=5聚类获取的潜在正示例代表进行检索是可行的.如图1(b)所示,当α从0.1增至0.9时,AUC值介于0.839到0.880之间,α=0.3时,达到最大值0.880,其波动在4.1%以内.可见在选择合适的参数情况下,SCPMK-MIL算法具有很强的鲁棒性.在α<0.4的情况下,α值对SCPMK-MIL分类精度的影响较小,AUC值的变化在2.2%以内,这和笔者对MIL问题的理解是吻合的.MIL的核心问题在于正示例的不确定性,如果包内潜在正示例代表得到确认,则包正负性主要由正示例是否出现决定,其它的包内数据应只起辅助作用.也就是说在潜在正示例和其它示例信息可同时获取的情况下,潜在正示例对包标记的影响大于包内其它示例的影响.在下面的实验中,固定k=5,α=0.3.

图2 部分GreenTeaBox图像Fig.2 Some images of GreenTeaBox
2.3 对比实验及分析
为了表示方便,下面的实验结果中标号1到25分别代表SIVAL图像集中的“FabricSoftenerBox”、“CheckeredScarf”、“FeltFlowerRug”、“CokeCan”、“WD40Can”、“AjaxOrange”、“DirtyRunningShoe”、“CandleWithHolder”、“GoldMedal”、“GreenTeaBox”、“CardboardBox”、“SpriteCan”、“SmileyFaceDoll”、“DirtyWorkGloves”、“StripedNoteBook”、“DataMiningBook”、“BlueScrunge”、“TranslucentBowl”、“RapBook”、“Apple”、“GlazedWoodPot”、“WoodRollingPin”、“JuliesPot”、“Banana”、“LargeSpoon”.首先比较相关反馈对搜索性能的影响,实验使用6幅感兴趣和6幅不感兴趣的图像进行初始检索;为了保持正负类的均衡,在检索结果中增加6幅感兴趣和6幅不感兴趣的图像,进行一次相关反馈的检索.比较结果如图3所示.从图3可以看出,使用相关反馈可以大大提高检索的性能,24幅(12个正包和12个负包)的相关反馈方法获取的AUC值比12幅(6个正包和6个负包)的AUC值提高了8%左右.其主要原因在于:在检索完成后,通过相关反馈增大有效训练集,提高了SVM分类器的精度和图像检索性能.
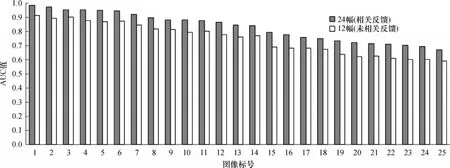
图3 相关反馈对图像检索性能的影响Fig.3 Effect of relevant feedback on image retrieval
为了进一步验证SCPMK-MIL算法的性能(设置k=5和α=0.3),按照2.1节所述的实验方法,将SCPMK-MIL和MILES[11],ACCIO![9]算法进行对比实验,每个试验重复30次,平均AUC值见表1,试验采用一次相关反馈算法(增加12个正包和12个负包,形成24幅训练包).为了验证SCPMK-MIL算法的有效性,将其与半监督GMIL算法[12]进行了对比实验,这里选择的相关反馈图像数等于已标注图像数,随着已标注的图像数量的增加,30次随机重复实验的平均AUC值变化曲线如图4所示(已标注图像确保一半为正一半为负).
从表1可以看出,SCPMK-MIL算法总体上来说优于MILES和ACCIO!算法,主要原因是:(1)文中设计的谱聚类方法可以很好地获取潜在正示例中心,辨别包内潜在正示例代表和其它示例;(2)融合RBF和PMK进行相似性计算可以平衡包内各示例对核相似性的影响,具有很强的可靠性与鲁棒性;(3)利用相关反馈技术,通过用户主动参与检索评价,可以获得较好的检索性能.而MILES算法则是将每个包投影到示例构成的空间,利用新生成投影向量比较相似性,其性能很大程度上受包中示例空间分布的影响,因此在示例空间分布不理想的情况下,其性能表现不佳.ACCIO!算法是一种基于DD的算法,存在优化解陷入局部极值问题,因此最终分类结果也不精确.

表1 图像集SIVAL上置信度为0.95的30次重复实验平均AUC值Table 1 Average AUC values with the 95%-confidence intervals over 30 independent runs on SIVAL dataset
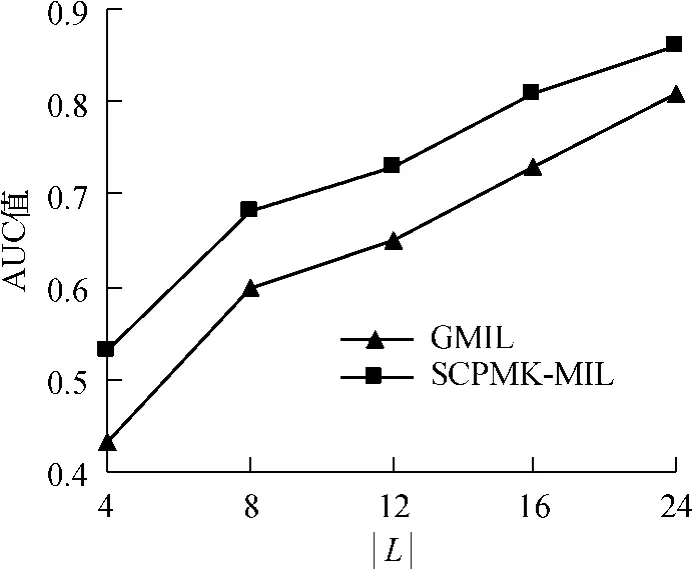
图4 图像集SIVAL上GMIL和SCPMK-MIL算法的性能对比Fig.4 Performance comparison between GMIL and SCPMKMIL algorithms for SIVAL dataset
3 结语
文中基于谱聚类和金字塔核,提出了一种新的MIL算法,称为SCPMK-MIL算法,在MIL框架下实现对象图像检索.其优势在于:(1)利用谱聚类方法在正示例空间聚类,获取潜在正示例代表,从而可定位图像中的潜在对象位置;(2)利用RBF和PMK度量潜在正示例代表和其它示例相似性,通过正比例系数平衡两者相似性的影响,从而提高MIL算法的准确度;(3)利用相关反馈方法提高图像检索的性能,从而提高检索用户满意度;(4)利用MIL训练包的性质,用户只需要对整个图像给定标记,而不必对具体区域进行标注,简化了训练样本的手工标注.基于SIVAL图像库的对比实验结果表明,文中提出的方法是有效的.
[1]陈星星,张荣.基于多尺度相位特征的图像检索方法[J].电子与信息学报,2009,31(5):1193-1196.Chen Xing-xing,Zhang Rong.A multi-scale phase feature based method for image retrieval[J].Journal of Electronics&Information Technology,2009,31(5):1193-1196.
[2]Datta R,Joshi D,Li J,et al.Image retrieval:ideas,influences,and trends of the new age[J].ACM Computing Surveys,2008,40(2):1-65.
[3]Lowe D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[4]Zheng Qing-fang,WangWei-qiang,GaoWen.Effective and efficient object-based image retrieval using visual phrases[C]∥Proceedings of the 14th ACM International Conference on Multimedia.Santa Barbara:ACM,2006:77-80.
[5]Philbin James,Chum Ondrej.Object retrieval with large vocabularies and fast spatialmatching[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Minnesota:IEEE,2007:1-8.
[6]Wu Zhong,Ke Qi-fa.A multi-sample,multi-tree approach to bag-of-words image representation for image retrieval[C]∥Proceedings of 12th International Conference on Computer Vision.Kyoto:IEEE,2009:1992-1999.
[7]Dietterich TG,Lathrop R H,Lozano-Pérez T.Solving the multiple instance problem with axis-parallel rectangles[J].Artificial Intelligence,1997,89(12):31-71.
[8]Zhang Qi,Sally A Goldman.Content-based image retrieval usingmultiple-instance learning[C]∥Proceedings of the 19th International Conference on Machine Learning.Sydney:IMLS,2002:682-689.
[9]Rouhollah Rahmani,Sally A Goldman.Localized contentbased image retrieval[C]∥Proceedings of the 7th ACM SIGMM International Workshop on Multimedia Information Retrieval.Singapore:ACM,2005:227-236.
[10]Chen Yi-xin,James Z Wang.Image categorization by learning and reasoning with regions[J].Journal of Machine Learning Research,2004,5(8):913-939.
[11]Chen Yi-xin,Bi Jin-bo,JamesWang Z.MILES:multipleinstance learning via embedded instance selection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(12):1931-1947.
[12]Wang Chang-hu,Zhang Lei,Zhang Hong-jiang.Graph based multiple-instance learning for object-based image retrieval[C]∥Proceeding of the 1st ACM International Conference on Multimedia Information Retrieval.Vancouver:ACM,2008:156-163.
[13]Fu Zhou-yu,Antonio Robles-Kelly.An instance selection approach to multiple instance learning[C]∥Proceedings of the IEEEComputer Society Conference on Computer Vision and Pattern Recognition.Miami:IEEE,2009:911-918.
[14]罗斌,郑爱华,汤进.基于模糊多类SVM的图像检索相关反馈[J].华南理工大学学报:自然科学版,2008,36(9):107-112.Luo Bin,Zheng Ai-hua,Tang Jin.Relevance feedback of image retrieval based on multicalss fuzzy support vector machines[J].Journal of South China University of Technology:Natural Science Edition,2008,36(9):107-112.
[15]Ng A Y,Jordan M I,Weiss Y.On spectral clustering:analysis and an algorithm[C]∥Proceedings in 14th Advances in Neural Information Processing Systems.Vancouver:NIPS,2001:849-856.
[16]Zhou D,BousquetO.Learning with local and global consistency[C]∥Proceedings in 16th Advances in Neural Information Processing Systems.Vancouver:NIPS,2004:321-328.
[17]Kristen Grauman,Trevor Darrell.The pyramid match kernel:efficient learning with sets of features[J].Journal of Machine Learning Research,2007,8(5):725-760.
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
山东冶金(2019年5期)2019-11-16 09:09:22
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
电子测试(2017年15期)2017-12-18 07:19:27
专利代理(2016年1期)2016-05-17 06:14:36
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
