
基于描述能力的视频标题分类*
2011-03-21 08:06:28齐全董晶
华南理工大学学报(自然科学版) 2011年7期
齐全 董晶
(北京理工大学计算机学院,北京100081)
视频作为方便高效的记录信息的载体已广泛地应用于人们的日常生活中.手机、数码相机、数码摄录机等视频摄录设备的快速普及使人们倾向于使用视频来捕捉和记录信息,并通过互联网平台进行分享[1].目前,互联网平台中已出现大量的视频共享网站,有些大型网站的视频数量甚至超过千万级的规模,如优酷网和土豆网等.要想在海量的互联网视频中找到用户感兴趣的视频,就需要建立有效的视频索引和查询机制.因此,视频搜索引擎具有广阔的应用前景.目前,视频搜索技术已成为多媒体计算、自然语言处理和搜索引擎这几个研究领域的共同课题.视频检索技术包括基于内容的视频检索和基于文本的视频检索(TBVR).现阶段,由于基于内容的视频检索所需的运算量过高[2],因此基于文本的视频检索仍是最流行的视频检索技术.
基于文本的视频检索系统将视频信息转化成文本,通过对获得的文本建立索引来进行视频检索.现有的主流视频搜索引擎,如百度、谷歌等都使用基于文本的视频检索技术,并从视频所在网页上获取视频的文本信息.在基于文本的视频检索系统中,标题作为视频信息的重要组成部分对精确的视频检索具有举足轻重的作用.然而对于标题本身是否能够准确描述视频内容这一问题,目前尚缺乏较为深入的研究.通过对来自优酷网、土豆网等大型视频网站的视频及其标题的分析,发现许多视频的标题不能准确概括视频的内容.因此,对基于文本的视频检索系统而言,找出那些不能准确表达视频内容的标题并加以处理,以提高系统的检索精度是十分必要的.文献[3-5]中对文本标题的自动分类进行了研究,文本标题与视频标题的处理方法有类似之处.
通过分析大型视频网站中视频标题的特点,文中根据标题对视频内容的描述程度将标题的描述能力定义为可描述、可理解不可描述和不可理解3个等级;将视频标题描述能力的评估问题看成分类问题,并使用支持向量机(SVM)[6]来实现自动分类.支持向量机本质上是一个两类分类器,其目标是寻找一个最优超平面(或最优超曲面,OHP),使得两类样本之间的间距达到最大.它对于解决小样本、非线性和高维模式识别问题具有很多的优势,并且在文本分类、手写体识别、自然语言处理等方面得到了验证[7-8].
由于视频标题通常很短,如果单纯依赖标题本身的信息会产生数据稀疏问题,因此文中提出利用标题在互联网搜索引擎中的搜索结果作为标题信息的补充,使用从汽车领域随机选取的5000个视频标题作为数据集进行分类实验,并对实验结果进行了分析.
1 视频标题特点分析
笔者利用网络爬虫从优酷网、土豆网等大型视频网站上抓取了汽车领域的62305个视频(包括标题等相关信息),并从中随机选取5000个作为分析样本及实验数据.所抽取的视频相关信息包括视频的标题、标签、简介、评论和类别.通过分析发现,在这些文字信息中,标签、简介、评论等所包含的视频信息十分有限.视频上传者通常只提供标题而不愿意提供视频简介和标签,且大量视频的评论内容为空,这就使得标题成为最重要的信息来源.同时,视频标题还具有以下几个特点.
1)视频标题含有大量领域词汇.在随机选取的5000个视频中,含有领域词的标题有3661个.领域词主要有两个来源:汽车品牌型号等领域词汇(如“宝马X5”、“法拉利”等)和汽车部件、汽车维修及汽车运动等汽车子领域词汇(如“漂移”、“烧胎”等).另外,普通人很难理解其确切含义的很多名词术语,如“移库”、“倒桩”等,通常也很难被完全收录到领域词库中.
2)视频标题普遍不长.视频标题通常很短,且包含大量领域词汇等未登录词,因此标题分词结果的准确率通常不高.但分词结果作为评估标题长度的数据仍然具有一定的参考价值.文中采用中国科学院计算机研究所开发的分词和词性标注工具ICTCLAS对标题进行词切分,使用分词结果包含的词语数作为标题的长度.5000个标题的平均长度为5.5,最长标题的长度为40,最短的为1.
3)很多视频标题不具有描述视频内容的能力.视频标题一般是视频内容最简单明了的概括,如“上海通用雪佛兰乐风宣传片”.因此标题被作为视频检索最重要的信息来源.5000个视频标题中大部分标题具有描述视频内容的能力,但有相当多的视频标题并不具备这个能力.其原因如下:
(1)由于视频上传者的疏忽,标题只能表现视频的一部分信息,如“宝马”作为标题只能说明视频和宝马车有关,但不能传达视频的具体内容.有的标题完全不能传达视频内容的任何信息,如标题“团结一心”.
(2)视频上传者为了吸引点播者的注意而故意使用不透露视频内容的标题,如“史上最强”、“全定制赛道怪物”等标题.
找到并处理描述能力不足的标题对提高目前视频搜索引擎和视频推荐系统的性能至关重要.
2 标题描述能力的分级及分类
2.1 标题描述能力的分级
不管是用于视频检索还是视频推荐,视频最终是要提供给使用者,并由使用者判断根据标题信息提供的视频是否和标题相符.事实上,标题与视频相符需要满足两个要求:一是标题包含足够的信息,使用户可以猜出视频的内容;二是标题与视频内容一致.文中只针对标题是否满足第一个要求进行研究,对于标题是否满足第二个要求则需要对视频内容进行分析,因此不在文中讨论的范围内.文中以模拟用户的判断行为作为出发点,根据视频标题对视频内容的描述程度将标题描述能力分为可描述、可理解不可描述和不可理解3个等级:
1)如果用户看过标题后可以猜出视频内容,那么该标题的描述能力为可描述(D),如标题“2010北京车展”.
2)如果用户看过标题后不能猜出任何有关视频内容的信息,那么该标题的描述能力为不可理解(I),如标题“史上最牛交警”.
3)如果用户看过标题后能猜出视频的一部分信息,但不能确定视频的具体内容,那么该标题的描述能力为可理解不可描述(IC),如标题“丰田凯美瑞”.
2.2 视频标题类型
按照标题描述能力的不同,将视频标题分为3类:如果标题的描述能力为可描述,那么该标题属于可描述类(D类);如果标题的描述能力为不可理解,那么该标题属于不可理解类(I类);如果标题的描述能力为可理解不可描述,那么该标题属于可理解不可描述类(IC类).
按照上述分类,采用人工方式对汽车领域的5000个视频进行分类:指定3名标注人员分别标注5000个视频标题.标注人员首先需要了解汽车领域的一些基础知识,避免出现由于领域知识不足造成错误的分类结果.对于3人的标注结果采用以下的方式处理:(1)如果3人对同一标题标注的类别相同,则该标题属于该类别;(2)如果3人对同一标题标注的类别不同,则由3人商议后决定该标题所属类别.
5000个视频标题的人工分类结果如下:550个无效视频标题因标题重复以及含有乱码等原因而无法用于评价;2455个视频标题具有描述视频内容的能力,这也体现了视频上传者的视频命名习惯,同时说明了搜索引擎利用视频标题检索视频的合理性;1478个视频标题不能描述视频内容;517个视频标题的描述能力不足,如果把这些视频标题直接用于检索,视频搜索和视频推荐的准确度和用户满意度会受到极大的影响.
3 SVM分类器的构造
SVM的基本思想是通过事先选择的非线性映射(核函数)将输入向量x映射到一个高维特征空间,在这个空间中构造最优分类超平面,以期将两类样本无错误地分开(训练错误率为0),而且要使两类(标记为y,y∈{-1,1})的分类空隙最大,前者保证经验风险最小,后者使推广性的界中的置信范围最小(即分类器的结构风险最小),这样可使在原始空间非线性可分的问题变为高维空间中线性可分的问题[7].
SVM的目标是寻找特征空间划分的最优超平面及其支持向量(SV),首先需求出SV,然后求OHP.由于SV是到OHP:w·x+b=0的距离最近的样本点,并且同一类的SV到OHP的距离完全相等,不同类的SV到OHP的距离不一定相等.因此,给定m个训练样本(x1,y1),(x2,y2),…,(x m,ym),要求一个分类超平面,关键在于求出分割超平面的法向量w和参数b.由于支持向量机理论要求分类超平面具有分类误差小、推广能力强的特点,这样分类超平面必须满足最优分类超平面的以下两个条件:
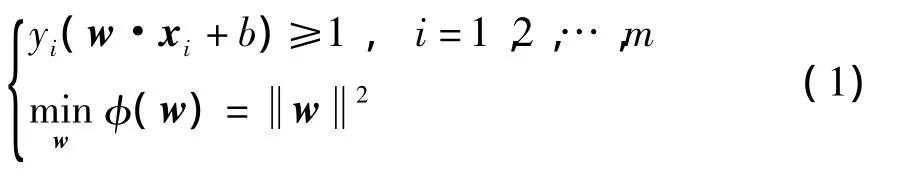
其中非线性函数φ(w)用于将数据从输入空间映射到高维空间.为了找到最优的分类超平面,可根据最优化理论,借助Lagrange函数将原问题转化为求解标准二次规划问题:
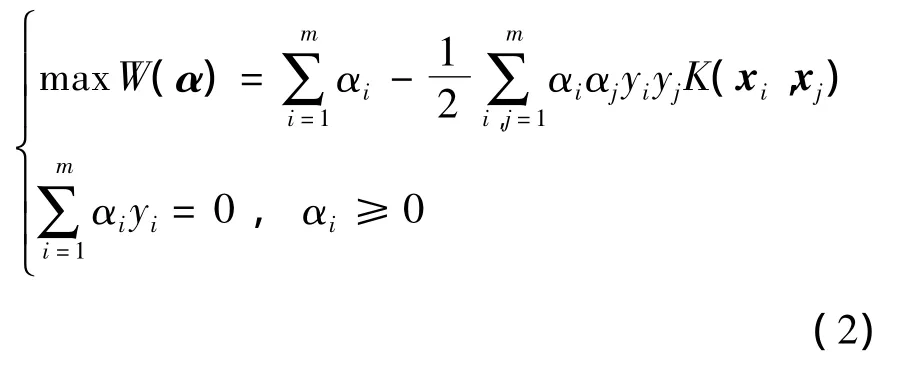
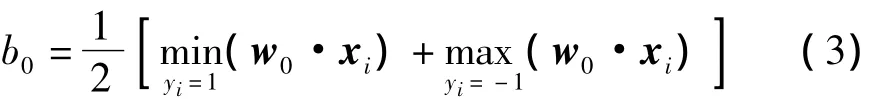
多数样本对应的αi为0,少数不为0的αi(αi>0)对应的样本即为支持向量,而相应的最优分类超平面(即分类决策函数)为

式中:α=(α1,α2,…,αm),每个αi为Lagrange乘数;K(x i,x j)为核函数,用于计算一对输入向量在高维空间中的内积.求最优平面的关键在于求出可以满足αi>0的αi以及
标题分类是一个多值分类问题,多值分类问题通常使用多个二值支持向量机的组合来解决,主要有一对多组合模式和一对一组合模式,其中一对一组合模式已经被证明其性能优于一对多组合模式[9],因此文中选用一对一组合模式,采用LIBSVM[10]软件包实现标题分类器的构建.
4 标题分类中的特征选取
特征选取就是针对特定的目标或任务为模型选择恰当的特征集.在人工标注的过程中,标注人员发现上传者通常更愿意在标题中使用熟悉的词汇描述视频内容,例如“测评”、“发布会”等.因此,视频主题相近的标题所使用的词语也十分相近.文中只使用词作为SVM的特征.词根据来源分为两类:第一类是标题的分词结果及分词个数;第二类是标题的搜索结果中所包含的领域词.
4.1 分词结果特征
分词结果是将标题用分词工具进行分词后得到的分词集合.文中使用中国科学院计算机研究所开发的ICTCLAS作为分词工具,并在分词词库中导入了汽车领域的词汇,如汽车商标、型号、配件等.分词结果中的停用词是不作为特征使用的.
一般来讲,越长的标题所含的关于视频的信息量越多,标注人员越容易将它标成可描述类,因此文中将标题长度作为特征之一.如前所述,虽然分词准确度不高,但作为度量标题长度的手段,分词结果包含的词语数仍具有参考价值.因此文中将标题通过分词工具得到的分词个数(不包含停用词)作为标题的长度.
4.2 标题搜索结果特征
由于标题本身的特点和视频上传者在命名标题时常常使用简写和新词,因此分词结果的准确率不是很高.在随机抽取的200个标题的分词结果中,只有113个结果完全正确.其中,大部分错误是由于汽车领域词没有被正确切分识别引起的,比较典型的错误是词语被错误地切开,如将“测评”分为“测”和“评”.为弥补分词的不足,文中利用视频标题在搜索引擎中的搜索结果来发现标题中未被正确切分的领域词.
互联网存放着大量有价值的信息,是一个重要的动态的信息来源.而搜索引擎作为搜索互联网信息的重要工具也常常被用来作为抽取信息的工具[11-12].
首先,将视频标题作为查询条件送到互联网搜索引擎中,搜索结果作为和标题最相关的文本保存下来.为保证返回文档和查询的相关性,只有排名靠前的文档被保存下来.如图1所示,文中使用百度搜索引擎作为查询工具,只保留返回文档的标题.

图1 视频标题的搜索结果示例Fig.1 Examples of searching results of video title
标题的分词结果中领域词被分错的主要原因是领域词被错误地切开,因此识别领域词的任务变为找到被误切开的领域词并将其重新合并起来.文中利用分词结果中的相邻词在搜索结果中共现的次数来计算相邻词的相关度,相关度高的词序列对视为候选领域词.随后,计算候选词在汽车领域视频标题中出现的次数,出现次数多的被认为是领域词.这些领域词将作为视频标题的特征用于标题分类.
同时,为了避免特征向量过于稀疏,并利用返回结果的相关性,文中将返回文档的标题中出现的汽车领域的词语作为标题的补充信息,并作为SVM的特征向量.
4.3 特征值的提取过程
由于SVM分类器所使用的特征都是数字型,为此需要将特征编码为数字,并提取相应特征项的特征值.
文中将词语的词频作为词语的特征.对于分词结果特征,词语的词频是该词出现在所在标题中的次数.对于标题搜索结果特征,词语分为两种:(1)存在于标题中但没有被分词工具识别出的词语,对于这种词语,文中将词语在视频标题中出现的次数作为特征;(2)返回的搜索结果中标题包含的领域词,对于这种词语,文中使用词语在同一视频标题的搜索结果中出现的次数作为特征.为了降低模型的训练时间,文中对特征向量进行了降维:如果一个分量在所有特征向量中非0的次数小于C,则在所有特征向量中删除该分量.实验中取C=2.
经过过滤,分词结果特征数为3976,其中包含标题长度特征;标题搜索结果特征数为2017.全部特征数为5993.
5 实验及结果分析
使用2.2节中人工标注的5000个视频标题作为实验数据集,其中可描述类(D类)标题有2 455个,不可理解类(I类)标题有1478个,可理解不可描述类(IC类)标题有517个,无效标题有550个.对于有效的4 450个视频标题,将每个视频标题送到百度搜索引擎中进行查询,将前30个返回结果的标题保存下来作为视频标题的补充信息.4450个视频标题随机分成数目相等的5组,其中4组作为训练集,1组作为测试集.测试集中,D类标题有537个,I类标题有290个,IC类标题有63个.
为了测试使用不同的特征集对分类效果的影响,文中采用了两组特征集:特征集1只包含分词结果特征;特征集2包含分词结果特征和标题搜索结果特征.
为了评价不同分类器的标题分类效果,分别使用学习记忆模型(MBL)、朴素贝叶斯(NB)、SVM 3种分类方法进行实验.其中,SVM核函数选取RBF函数.
对分类性能进行评估时,采用常用的3个评测指标:准确率(P)、召回率(R)、综合指标F值(F):

其中F值是综合评价P和R的指标,β是用来表明实验侧重于P还是R,本实验中β设定为1.
文中分别在两种特征集上测试了不同分类方法的分类效果,结果如表1-3所示.
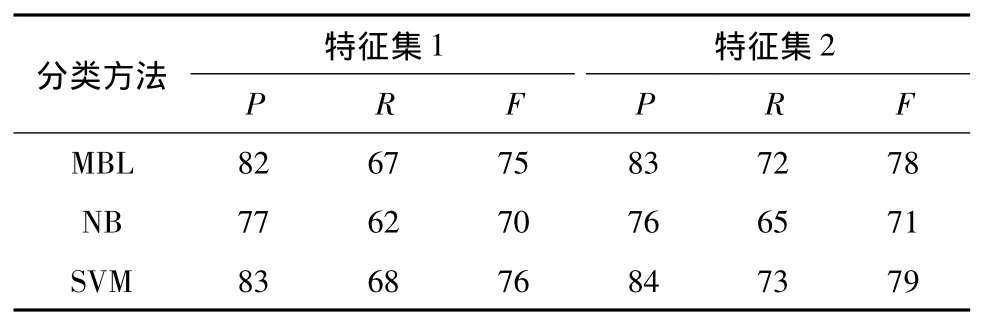
表1 D类标题的分类结果对比Table 1 Comparison of classification results for D titles%

表2 IC类标题的分类结果对比Table 2 Comparison of classification results for IC titles%
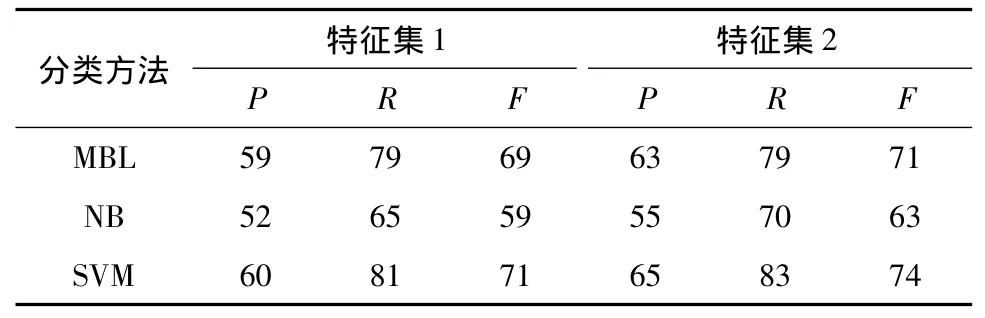
表3 I类标题的分类结果对比Table 3 Comparison of classification results for I titles%
从表1-3中可以看到,对于IC类标题,3种分类方法的P、R和F很低;对于D类标题,SVM在特征集2上的P、R、F值分别达到了84%、73%和79%,较高的准确率确保了通过文中方法获得的可描述标题的可靠性.通过分析IC类标题,发现该类标题中的词语也常在可描述类标题中出现,例如“宝马X5”属于可理解不可描述类,但“宝马X5试驾”及“宝马X5测评”等属于可描述类的标题.表4为使用SVM和特征集2得到的混淆矩阵.在计算相似度时,IC类标题更倾向于被标成D类.而IC类的标题数量较少也影响了该类标题的分类效果.因此,文中只关注D类和I类的实验结果.
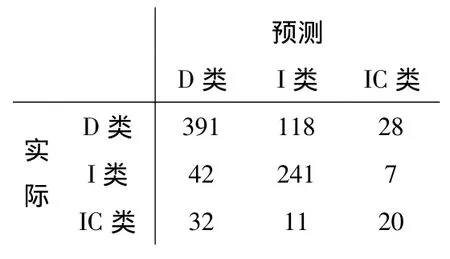
表4使用特征集2和SVM得到的混淆矩阵Table 4 Confusion matrix based on feature set2 and SVM
通过比较特征集1和2的分类效果,发现在使用标题搜索结果特征后,3种分类方法对D类和I类识别的P、R和F值都有所提升,其中SVM对D类和I类识别的F值都提高了3%.由此可以认为,标题搜索结果特征可以提升分类的效果.
两个特征集上的实验结果(表1-3)都表明:3种分类方法中,SVM对于D类和I类的分类效果均优于MBL、NB.因此,可以认为SVM对视频标题的分类效果优于MBL、NB.
6 结语
文中根据视频标题对视频内容的刻画程度将标题的描述能力分为可描述、可理解不可描述和不可理解3个等级.通过自动分类的方法实现对标题描述能力的评估.为丰富视频标题的信息,文中引入了标题在搜索引擎中的搜索结果作为标题信息的补充.由于SVM对小样本分类问题有很好的识别效果,因此文中将SVM作为分类模型.实验结果表明,SVM的分类性能优于NB和MBL;搜索结果作为标题补充可以提升分类的效果.进一步的研究将在以下两个方面进行:(1)分析视频标题的语义信息并将其应用于分类技术中;(2)标题在搜索引擎中的返回结果与标题本身的相关性.
[1]张鹿.基于内容的视频搜索结果优化[D].合肥:中国科技大学计算机学院,2010:1.
[2]Mu Xiang-ming.Content-based video retrieval:does video's semantic visual featurematter?[C]∥Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Washington:ACM,2006:679.
[3]战学钢,姚天顺.基于语义分析的标题分类方法[C]∥中文信息处理国际会议论文集.北京:清华大学出版社,1998:321-324.
[4]陈磊.基于HNC语义分析的中文标题分类方法[C]∥全国第五届计算机语言联合学术会议论文集.北京:清华大学出版社,1999:371-375.
[5]Song D,Lau R Y K,Bruza PD,et al.An intelligent information agent for document title classification and filtering in document-intensive domains[J].Decision Support Systems,2007,44(1):251-265.
[6]Kotsiantis S B.Supervised machine learning:a review of classification techniques[J].Informatica,2007,31(3):249-268.
[7]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.Zhang Xue-gong.Introduction statistical learing theory and support vectormachine[J].Acta Automatica Sinica,2000,26(1):32-42.
[8]Li Lishuang,Mao Tingting,Huang Degen,et al.Hybrid models for Chinese named entity recognition[C]∥Proceedings of the Fifth SIGHANWorkshop on Chinese Language Processing.Sydney:Association for Computational Linguistics,2006:72-78.
[9]Hsu CW,Lin C J.A comparison of methods for multiclass support vectormachines[J].IEEE Transactions on Neutral networks,2002,13(23):415-425.
[10]Chang C,Lin C.LIBSVM:a library for support vector machines[EB/OL].(2001-05-15)[2011-04-01].http:∥www.csie.ntu.edu.tw/~cjlin/libsvm.
[11]Bollegala D,Matsuo Y,Ishizuk M.Measuring semantic similarity between words usingWeb search engines[C]∥Proceedings of the 16th International Conference on World Wide Web.New York:ACM,2007:757-766.
[12]Sahami M,Heilman T.AWeb based kernel function for measuring the similarity of short text snippets[C]∥Proceedings of the 15th International World Wide Web Conference.Scotland:ACM,2006:377-386.
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00
数学年刊A辑(中文版)(2021年3期)2021-11-05 08:36:32
数学年刊A辑(中文版)(2021年2期)2021-07-17 08:37:58
小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32
智富时代(2019年6期)2019-07-24 10:33:16
数学物理学报(2019年1期)2019-03-21 05:26:12
作文评点报·低幼版(2016年42期)2017-01-23 11:45:27
高中生·天天向上(2016年9期)2016-11-22 09:10:34
数学年刊A辑(中文版)(2015年1期)2015-10-30 01:55:44
传奇故事(破茧成蝶)(2015年7期)2015-02-28 09:29:18
