
列式数据库Ver tica的特性分析
2011-02-27 05:42唐亚男
电脑与电信 2011年5期
唐亚男
(亚信联创科技(中国)有限公司,北京 100086)
1.前言
与以往常见的行式关系型数据库不同,Vertica是一种基于列存储(Column-Oriented)的数据库体系结构,这种存储机构更适合在数据仓库存储和商业智能方面发挥特长。
常见的RDBMS都是面向行(Row-Oriented Database)存储的,在对某一列汇总计算的时候几乎不可避免的要进行额外的I/O寻址扫描,而面向列存储的数据库能够连续进行I/O操作,减少了I/O开销,从而达到数量级上的性能提升。同时,Vertica支持海量并行存储(MPP)架构,实现了完全无共享,因此扩展容易,可以利用廉价的硬件来获取高的性能,具有很高的性价比。
2.Vertica数据库的体系结构
如图1,展示的是单节点上的Vertica的基本体系结构。
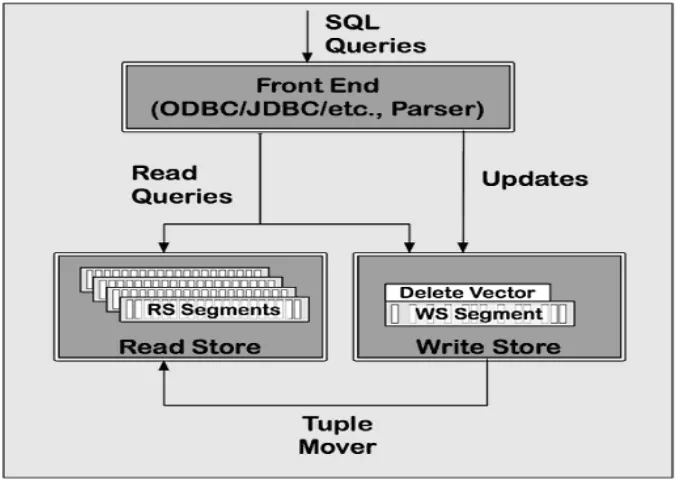
图1 体系结构
作为关系型数据库,Vertica的查询SQL也是在前端被解析和优化的。但与传统的关系型数据库有所不同,Vertica内部是混合存储的,包括两种不同的存储结构:写优化器(WOS)和读优化器(ROS)。
(1)写优化器WOS(W rite-Optim ized Store)
是位于主存储器上的一个数据结构,用于有效的支持数据插入和更新操作;数据的存放是无序的,非压缩的。
(2)读优化器ROS(Read-Optimized Store)
是磁盘物理存储,存放的是排序和压缩后的数据库大块数据,因此这里的查询相比于WOS性能更好。
(3)Tuple Mover进程
是Vertica内部的一个进程,定期的以大数据块的形式把数据从WOS移到ROS,由于是对整个WOS操作,Tuple Mover一次能非常有效的排序很多记录,最后批量把它们写入磁盘。
在Vertica内部,不论是WOS还是ROS都是按列存储的。
举个例子:
表Sales包含字段(order-id、product-id、sales-date、customerid、sales-price),Vertica会存储至少五个不同的列(逻辑上展示给用户的是一张表)。通过分开存储这些列,Vertica能够只返回用户特定查询的列。
在Vertica中,每一列可以存在于不同的Projections中,如可以给Sales表建立两个Projection:其中sales-prices包含order-id、product-id、sales-date、sale-price四 列 , 另 一 个salescustomers包含了order-id、product-id、customer-id三列。每个projection都可以指定单独的排序,例如:命名为salescustomers的projection可能会按custmoer_id排序存储,这对于“统计某个客户订购了哪些产品”这类查询就非常有效。借助于这种存储方式,对每个查询Sql,Vertica的Database Designer工具会自动使用最优的projections,从而能很快地响应用户的请求。
当然,这种多个projections冗余存储的方式会占用更多的磁盘空间,对此,Vertica也给出了很好的解决方案。高效的列压缩模式能够最多把数据压缩掉90%,不但大大减少了磁盘的使用,同时由于Vertica能够直接处理压缩数据,这样查询性能和查询时的CPU负载都大大降低了。
3.Vertica的关键特性分析
在数据仓库领域,人们会更多的关注数据库的查询性能。Vertica的查询响应受到多个因素的影响。
举个简单的例子,如上提到的Sales表,如果要计算出商品的平均销售价格,可以用:
SELECT date,AVG(sales-price)FROM sales GROUPBY sales-date这样的语句来实现。对于这样的典型查询语句,系统的主要开销在磁盘访问(disk I/O)和CPU处理两个方面(分布式的情况下还需考虑网络I/O),通常情况下disk I/O和CPU计算是同时进行的,这样我们不难得出结论:如果disk I/O用了D秒,CPU处理用了C秒,则整个查询的响应时间是D和C两者中的最大值。
理解了以上一般SQL语句的处理过程,我们就可以进一步的分析一下Vertica数据库在查询方面的优势在哪里。
3.1 列定向(Column-orientation)
由于大多数的查询都是要从磁盘读取数据,因此可以说disk I/O在很大程度上决定了一个查询的最终响应时间。从上面的示例可以看出,Vertica只需要读取sales-date,sales-price两列,而行式存储的数据库则要读取全部的5列,列式数据库的优势不言而喻。
3.2 压缩机制(Aggressive Compression)
在数据存储方面,Vertica利用内部的特定算法对数据进行压缩处理。这样的机制会大大减少disk I/O的时间(D),同时由于Vertica对扫描和聚合等操作也在内部进行了优化,可以直接处理压缩后的数据,这样CPU的工作负载(C)也减少了。如上例中的AVG聚合函数,Vertica是不需要将压缩数据先做类似解压这种处理的,因此查询性能得到优化。
3.3 读优化存储(Read-Optim ized Storage)
Vertica的数据库存储容器ROSContainer专门为读操作进行了优化设计,且其中的数据是经过了排序和压缩处理的,即每个磁盘页上不会有空白空间,而传统的数据库一般会在每页上预留空间以便日后的insert操作来使用。
3.4 多种排序方式的冗余存储
为了高可用性和备份恢复的需要,Vertica会按照不同的排序方式对数据做冗余存储,这不但避免了大量的日志操作,也为查询带来了便利。Vertica的查询优化器会自动选择最优的排序方式来完成特定的查询。
3.5 并行无共享设计
Vertica支持完全无共享海量并行存储(MPP)架构,随着硬件Server的增加,多个CPU并行处理,性能也可以得到线性的扩展,这样用户使用廉价的硬件就可以获得较高的性能改善。
3.6 其他管理特征
除了有优越的性能以外,Vertica在数据库管理方面也进行了非常人性化的设计。
Vertica Database Designer是一个界面化的日常管理工具,并且能为用户作出详尽的DB层物理设计方案,大大减少了日后的性能调优方面的开销。
Vertica通过K-Safety值的设置,完成了数据库的备份恢复机制,并保证了高可用性。
对于数据库中的每个表每个列,Vertica都会在至少K+1个节点上存储,如果有K个节点宕机,依然能够保证Vertica DB是完整可用的;当损坏的节点恢复时,Vertica自动完成节点间的热交换,把其他节点上的正确数据恢复过来。通过这种机制也保证了Vertcia库的节点数目可以自由伸缩而不会影响到数据库的操作。
Vertica通过两种技术来实现在线的持续数据装载而不会影响到数据库的访问。
首先,Vertica通常运行在快照隔离(Snapshot Isolation)模式下,该模式下查询读取的是最近的一致的数据库快照,这个快照是不能被并发的update或delete操作更改的,因此查询操作也不需要占用锁,这种方式保证了数据装载(insert)和其他查询能互不干扰。另外,Vertica可以把数据直接装载到WOS结构中,WOS中的数据是不排序或索引的,所以装载速度会很快,然后再由Tuple Mover进程在后台把数据移入ROS中,由于TupleMover的操作是大块读取(bulk-load)的,所以性能也很好。
4.结语
综上所述,Vertica在设计上充分考虑和利用了列式存储的优越性,使数据库的整体性能、易用性及可靠性方面都达到了较高的水平,同时Vertica提供了大量的管理监控工具及APIs接口等,给使用者带来了方便,因此这几年的发展速度也很快,值得我们关注。
[1]程莹.云计算时代的数据库研究[J],电信技术,2011,(01).
[2]尹东方.列式存储在知识发现系统中的应用与实现[D].中国优秀硕士学位论文全文数据库,2010,(07).
[3]石菲.列式数据库持续突破[J].中国计算机用户,2009,(09).
[4]Pedro Furtado.Model and procedure for performance and availability-w ise parallel warehouses,Distributed and Parallel Databases,2009,(02).
[5]Zack Jourdan;R.Kelly Rainer;Thomas E.Marshall.Business Intelligence:An Analysis of the Literature,Information Systems Management,2008,(03).
[6]Willian H.Inmon.Building the Data Warehouse,4 edition,Wiley Education,2005:327-389.
猜你喜欢
天津科技(2022年5期)2022-05-31
教师·下(2017年10期)2017-12-10
现代计算机(2017年7期)2017-04-22
网络安全和信息化(2017年3期)2017-03-10
读写算·小学低年级(2017年1期)2017-02-06
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
海军航空大学学报(2015年1期)2015-11-11
空间控制技术与应用(2015年4期)2015-06-05
网络安全和信息化(2015年11期)2015-03-17
