
一种新的语音端点检测方法及在智能轮椅人机交互中的应用
2011-02-23 07:05:22胡章芳
重庆邮电大学学报(自然科学版) 2011年4期
罗 元,黄 璜,张 毅,胡章芳
(重庆邮电大学智能系统及机器人研究所,重庆 400065)
0 引言
随着世界人口老龄化越来越严重和各种灾难、疾病等原因造成的残障人士的增加,他们存在不同程度的能力丧失,如行走、视力、动手及语言等,这一些特殊群体的医疗和护理,将成为经济和社会发展的巨大压力。为了给残障人士和老人的平常生活带来方便,世界各国都广泛开展了智能轮椅方面的研究。
语音作为一种自然的交流方式,更具人性化和亲合力,更加方便,成为智能轮椅人机交互的重要方式之一。语音识别系统中,有效准确地确定语音段端点不仅能使处理时间减到最小,而且能排除无声段的噪声干扰,从而使识别系统具有良好的性能。目前的端点检测方法主要有基于谱熵的端点检测改进方法[1-2]、基于神经网络的端点检测方法[3]、基于倒谱特征的算法[4]、普通话孤立词语音端点检测的分形维方法[5]、基于短时能量的语音端点检测算法[6]、基于小波分析的语音端点检测算法研究与仿真[7]、基于子带幅度差异的方法[8]等,而这一些方法主要是在低噪声的环境下进行研究,当应用在一般噪声环境下时,语音端点检测会出现问题,语音识别率也会受到影响。
本文提出了短时能量与倒谱距离相结合的端点检测方法,在一般噪声环境下(40 dB <SNR <50 dB)[9-10]具有良好的鲁棒性。实验结果表明,此方法能准确检测到语音端点,通过设置5个基本语音命令(前进、后退、左转、右转、停止)实现了智能轮椅语音控制。
1 语音识别系统
语音识别过程本质上是一个模式识别的过程,其基本结构原理如图1所示,主要包括语音信号预处理、特征提取、特征建模、相似性度量和后处理等几个功能部分,其中后处理部分为可选部分。
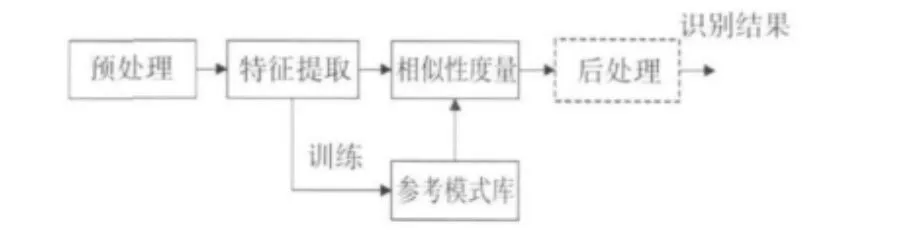
图1 语音识别基本原理图Fig.1 Basic schematic diagram of speech recognition
语音识别的过程分为训练阶段和识别阶段。无论是训练还是识别,都需要首先对输入的原始语音进行预处理,并进行特征提取。预处理主要包括端点检测、预加重、分帧、加窗等。端点检测是指运用数字信号处理技术找出语音信号中的各种段落(如音速、音节、词等)的起点和终点的位置。在孤立词识别中,主要目的是找出词的起止点。在背景噪声干扰下,对语音的起止点作出准确的判别是十分重要的,错误地判别起止点会导致起始子音的消失,以致造成误判或将背景噪声判断为语音信号。
显然可以看出,端点检测是语音识别系统的核心部分,因为只有准确地找出语音段的起始点和终止点,才有可能使采集到的数据是真正要分析的语音信号,这样不但减少了数据量、运算量和处理时间,同时也有利于系统识别率的改善。
2 短时能量与倒谱距离结合的端点检测
2.1 基于倒谱距离的端点检测
设信号s(n),其倒谱变换为c(n)。信号倒谱的一种定义是信号的能量谱密度函数S(ϖ)的对数傅里叶反变换,或者可以将信号 s(n)的倒谱c(n)看成是log S(ϖ)的傅里叶级数展开,即


信号与其倒谱是一一对应的变换,因此,倒谱的均方距离可以反映2个信号(语音与背景噪声)谱的区别,倒谱距离可以作为端点检测的判决参数,属于相似距离范畴。
2.2 短时能量与倒谱距离相结合的端点检测方法
语音信号序列先经过一系列预处理。首先将语音序列去直流(即减去平均值),再作归一化处理将幅值限制在1 Hz之内,然后,通过一个预加重滤波器,滤去50 Hz的电源干扰和超出一半采样率的频率分量。经过预处理后的语音序列可进行倒谱距离和短时能量计算。

因为倒谱距离能反映语音与背景噪声谱的区别,而且能量本身也是语音的一个重要特性,所以首先为倒谱距离和短时能量分别确定2个门限。2个倒谱距离的门限(1个高门限dst1和1个低门限dst2)和2个短时能量的门限(1个高门限Eamp1和1个低门限Eamp2)。dst2,Eamp2比较低的门限,其数值比较小,对信号变化比较敏感,很容易就会被超过。dst1,Eamp1是比较高的门限,数值比较大,信号必须达到一定的强度,该门限才可能被超过。低门限被超过未必就是语音的开始,有可能是时间很短的噪音引起的。高门限被超过则可以基本确信是由于语音信号引起的。
整个检测阶段:在静音段,如果倒谱距离或能量超过了低门限(dst>dst2或Eamp>Eamp2),就应该开始标记起始点,进入过渡段。在过渡段中,由于参数的数值比较小,不能确信是否处于真正的语音段,因此,只要2个参数的数值都回落到低门限以下(dst<dst2且Eamp<Eamp2),就将当前状态回复到静音状态。而如果在过渡段中2个参数中的任一个超过了高门限(dst>dst1或Eamp>Eamp1),就可以确信进入语音段了。
短时能量与倒谱距离结合的端点检测算法过程如图2所示。
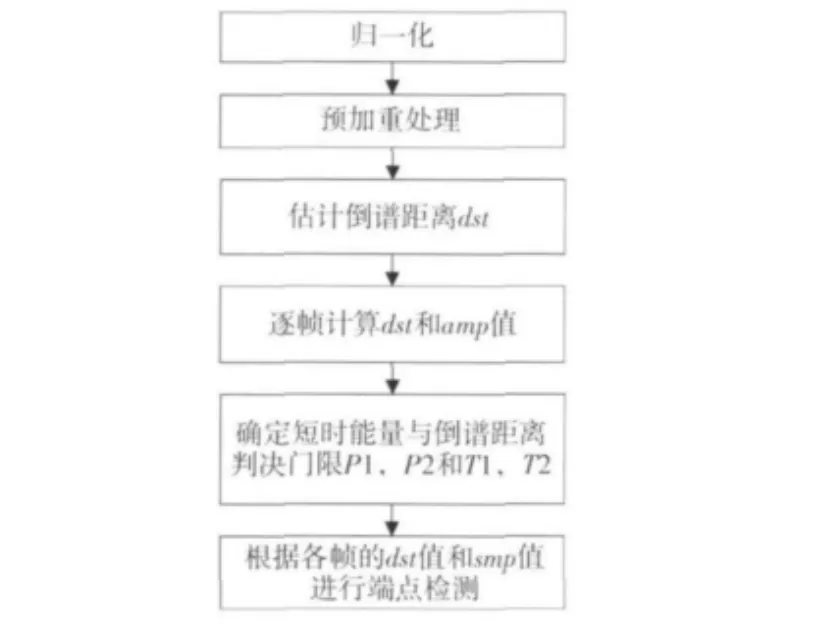
图2 算法流程图Fig.2 Algorithm flow chart
3 实验及分析
结果;表2为男声的端点检测结果。
3.1 端点检测实验
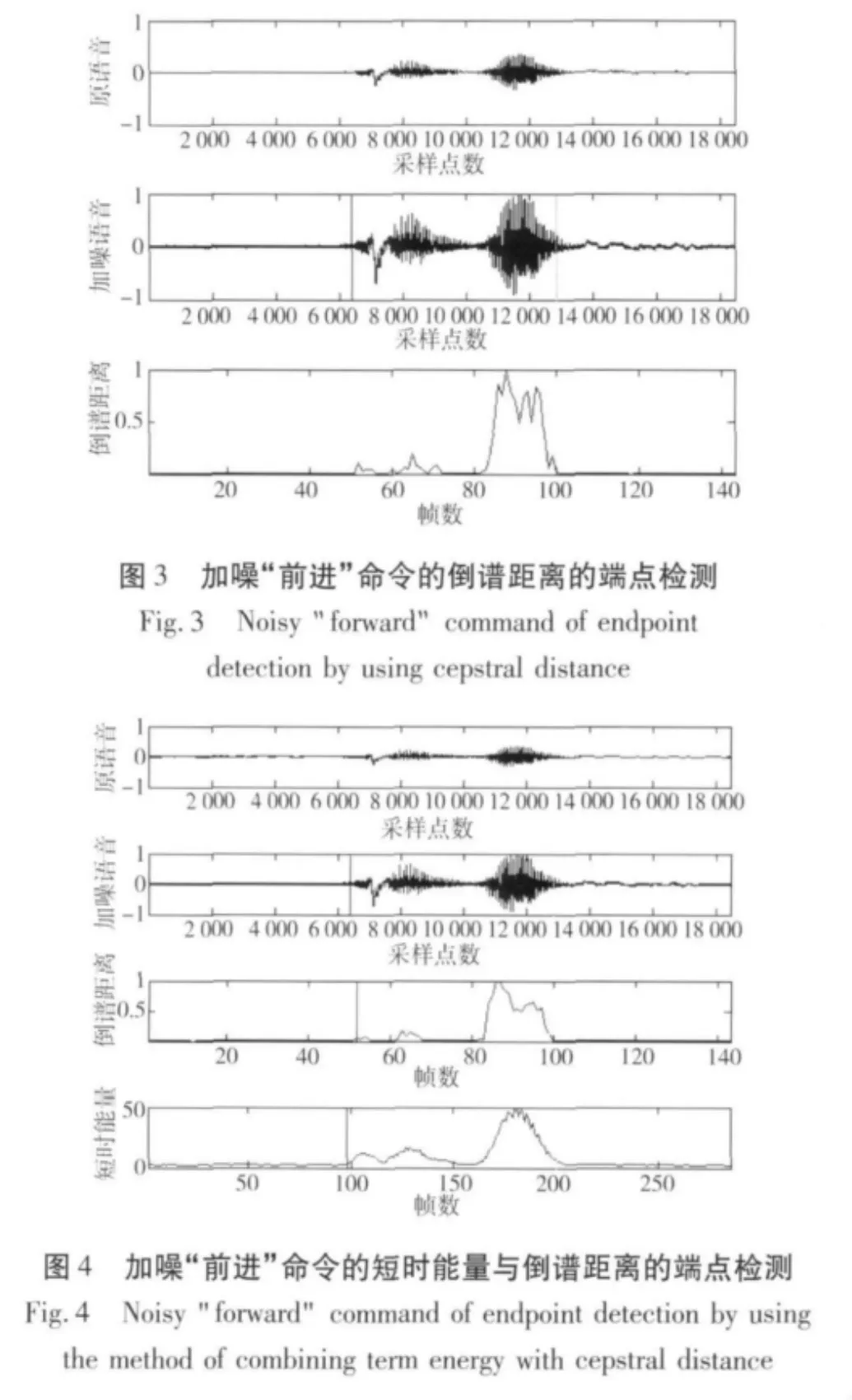
当SNR=10 dB时语音信号与噪音信号几乎无法辨别;当SNR为10~30 dB时,噪声为强噪声环境;当SNR为40~50 dB时,噪声为通常实际中一般噪声环境;当SNR为50~60 dB时,噪声为低噪环境[6]。故在通常情况下,在该实验中我们取高斯白噪声的能量以SNR=45 dB大小来表示一般环境下噪声,利用短时能量与倒谱距离相结合的方法研究和比较。
本仿真实验所取的语音样本为我们录好的200条相对纯净的语音,男女各100条,2男2女所录的语音中都包括前进、后退、左转、右转、停止等5个命令,每个命令各10条。采样频率为16 kHz,16 bit量化,单声道,然后对各个语音样本进行45 dB混噪,最后进行实验。图3为在一般噪声环境下,利用倒谱距离的“前进”语音命令端点检测图;图4为在一般噪声环境下,短时能量与倒谱距离结合的“前进”语音命令端点检测图;表1为女声的端点检测

表1 女声的端点检测结果Tab.1 Endpoint detection results of female

表2 男声的端点检测结果Tab.2 Endpoint detection results ofmale
从实验结果可以看出,在一般噪声环境下,倒谱距离用于端点检测明显失去了作用,并不能检测到语音的端点,所以短时能量与倒谱距离相结合比倒谱距离的端点检测方法,更能很好地检测到语音的起始点。
3.2 在智能轮椅交互中的应用
智能轮椅由轮椅体、面板、控制箱、电机驱动板、轮椅控制器、电源模块和电池组成。控制箱中包括3块电路板,分别为ARM板、电机控制电路板和传感器信息处理板。特别是ARM板,它是智能轮椅中最重要的一部分,智能轮椅主要由ARM板的Linux操作系统控制。总之,ARM是一个服务器端,客服端就是笔记本电脑,也是语音识别系统操作平台,最后通过无线局域网将2个连接起来。智能轮椅人机交互系统如图5所示。
图5 智能轮椅人机交互系统Fig.5 Human-computer interaction system of the intelligentwheelchair
电脑的声卡和麦克风用于语音识别和信号传输。当我们的声音进入麦克风从模拟信号转变为数字信号,录音程序将数字化的语音信号以规定的采样频率、采样精度和声道保存到计算机;然后由端点检测程序标出语音信号的端点;接着将做了端点标记的语音信号进行 MFCC(mel-frequency cepstru coefficient)特征提取,声音就被加工成一系列的特征序列,将这些特征序列分析建立语音语据库。在识别过程中,将再次提取的特征序列分析并与数据库数据进行匹配比较。ARM是用来控制轮椅采取适当的行动。这个过程如图6所示。
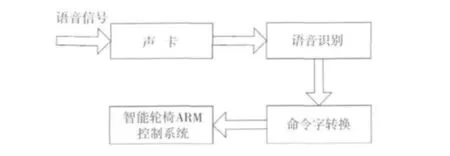
图6 智能轮椅人机交互系统的详细流程图Fig.6 Detailed flow chart of human-computer interaction system
我们知道,取样频率越高,提取的信号将越接近原来的信号,不过,高采样频率需要较大的音频文件。在语音识别中,16 kHz的采样频率已被证明非常有效。因此,在VC程序中我们把采样频率设置为16 kHz。在实验室的环境下,我们向麦克风讲5个命令,智能轮椅在各个命令下都成功执行了相应的行动,基于语音控制的智能轮椅人机交互系统如图7所示。
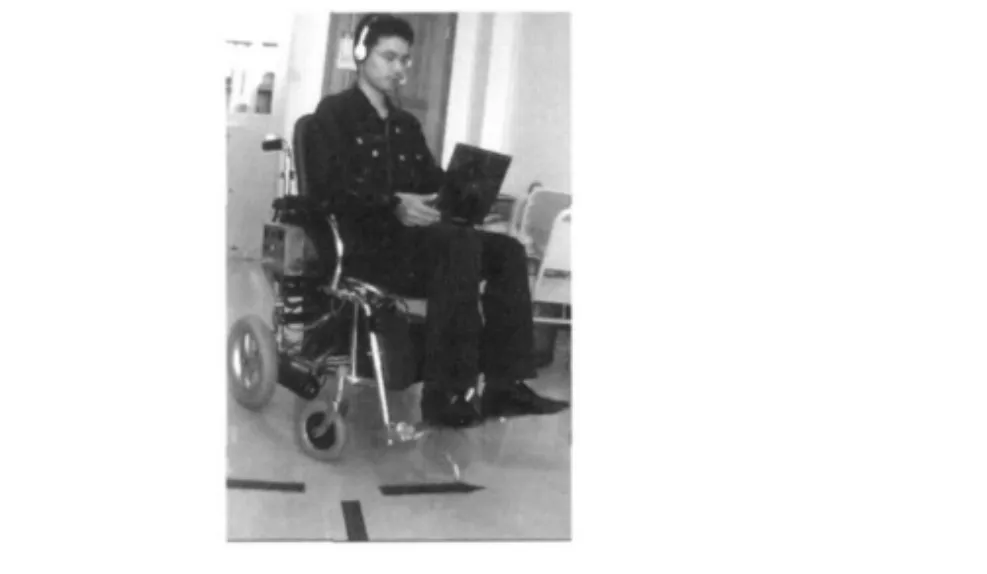
图7 基于语音控制的智能轮椅人机交互系统Fig.7 HMIsystem of intelligentwheelchair based voice-controlled
4 结束
本文提出的短时能量与倒谱距离相结合的端点检测方法,实验证明,在一般噪声环境下,该方法能很好地检测到语音的起止点,具有良好的鲁棒性,进而对整个智能轮椅的语音识别系统起到了关键作用,实现了人与智能轮椅的交互。
[1]王让定,柴佩琪.一个基于谱熵的语音端点检测改进方法[J].信息与控制,2004,33(1):77-81.
WANG Rang-ding,CHAI Pei-qi.A novel endpoint detectionmethod based on spectral entropy speech[J].Information and control,2004,33(1):77-81.
[2]WU B F,WANG K C.Robust Endpoint Detection algorithm based on the adaptive band-partitioning spectral entropy in adverse Environments[J].IEEE Transactions On Speech and Audio Processing,2005,13(5):762-775.
[3]HUSSAIN A,SAMAD SA,LIEW B F.Endpoint detection of speech signal using neural network[J].IEEE Trans on ASSP,2000,(1):271-274.
[4]王博,郭英,段艳丽,等.基于倒谱特征的语音端点检测算法研究 [J].信号处理,2005,21(4A):212-215.
WANG Bo,GUO Ying,DUAN Yan-li,et al.A study of speech endpoint detection algorithms Based on the spectrum characteristics[J].Signal Processing,2005,21(4A):212-215.
[5]张岳,韩子丹,戴志强.普通话孤立词语音端点检测的分形维方法研究[J].中国传媒大学学报自然科学版,2006,13(1):75-80.
ZHANG Yue,HAN Zi-dan,DAI Zhi-jiang.A study of fractal dimension based on speech endpoint detection method ofmandarin isolated words[J].Journal of Communication University of China Science and Technology,2006,13(1):75-80.
[6]张仁智,崔慧娟.基于短时能量的语音端点检测算法研究[J].语音技术,2005,(7),52-59.
ZHANG Ren-zhi,CUIHui-juan.A study of speech endpoint detection algorithm Based on short-time energy[J].Speech Technology,2005,(7):52-59.
[7]陈保远,梁伟明.基于小波分析的语音端点检测算法研究与仿真 [J].哈尔滨理工大学学报,2009,14,(1):51-59.
CHEN Bao-yuan,LIANGWei-ming.A study simulation of speech endpoint detection algorithms based on wavelet analysis[J].Journal of Harbin University of Technology,2009,14(1):51-59.
[8]ZHANG Xue-ying,ZHAO Zhe-feng,ZHAO Gao-feng,A speech endpointdetectionmethod based on wavelet coefficient variance and sub-band amplitude variance[C]//ICICIC'06 Proceedings of the First International Conference on Innovative Computing,Information and Control,Washington,DC,USA:IEEE Computer Society,2006(3):83-86.
[9]宋喆,张德民,张天骐.一种改进的基于子带谱熵的语音激活检测方法[J].重庆邮电大学学报:自然科学版,2009,21(6):725-730.
SONG Zhe,ZHANG De-ming,ZHANG Tian-qi.An improved detection method of voice sub-activity based spectral entropy[J].Chongqing University of Posts and Tele Communications:Natural Science Edition,2009,21(6):725-730.
[10]张跃进,刘邦桂,谢昕.噪声背景下语音识别中的端点检测[J].华东交通大学学报,2007,24(5):135-138.
ZHANG Yue-jin,LIU Bang-gui,XIE Xin.End-point detection of speech recognition under noise background[J].Journal of East China Jiao-Tong University,2007,24(5):135-138.
(编辑:刘 勇)
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:34
汽车实用技术(2022年4期)2022-03-07 06:02:26
中国西部(2021年4期)2021-11-04 08:57:32
数学小灵通·3-4年级(2020年3期)2020-06-24 05:50:52
华东师范大学学报(自然科学版)(2020年1期)2020-03-16 03:14:55
新世纪智能(高一语文)(2019年10期)2020-01-13 05:13:44
中学生数理化·教与学(2019年8期)2019-09-18 15:08:40
天津诗人(2017年2期)2017-11-29 01:24:24
数学物理学报(2017年1期)2017-06-05 09:12:28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:52
