
基于视频分析的虚拟翻书系统的设计与实现
2011-02-20 00:47孙连山王今雨
陕西科技大学学报 2011年4期
孙连山, 王今雨
(陕西科技大学电气与信息工程学院, 陕西 西安 710021)
0 引 言
虚拟翻书系统是虚拟现实技术(Virtual Reality,VR)[1]及基于计算机视觉的手势识别技术[2]的一种具体应用.虚拟翻书系统采用基于Flash的电子书封装丰富的文字、视频和音频素材,配合基于视频分析或红外遮挡检测的智能手势运动识别引擎,响应用户手势翻动电子书,为用户带来与翻阅实体书相类似的体验,被广泛地应用于各种现代展馆当中[3].但现有相关研究侧重于实现复杂的手势识别算法[4],而没有从软件工程的角度系统地研究虚拟翻书系统的构造问题.本文从软件工程的视角考察基于视频分析的虚拟翻书系统的构造问题,在分析虚拟翻书系统的功能需求和质量属性需求的基础上,设计了一种开放的参考软件体系结构,允许用户定制简单、高效的动作识别算法、灵活地设置观测区域、调整手势动作和翻书行为语义之间的映射并且区分不同的动作监测状态,在保证实时性的前提下避免了读者偶然动作造成的误翻.
1 需求分析
分析现有的虚拟翻书系统,不难发现,其初衷是为用户提供通过手势动作操纵电子书的能力,模仿用户阅读实体书的过程,提升用户的沉浸感和交互感.
首先,现有的虚拟翻书系统大都实现了3个基本功能:(1)向读者展示电子书的当前页面,供读者阅读;(2)侦测读者挥手动作,将电子书翻到下一页;(3)侦测读者挥手动作,将电子书翻到前一页.
其次,虚拟翻书系统毕竟是一种信息技术的应用,它模拟真实场景,但又具有高于真实场景的一些灵活性.如虚拟翻书无需模拟真实翻书的全过程,只要用户做出翻书的有效指令,系统就会帮助用户自动完成翻书动作,降低用户的操纵负担.虚拟翻书系统中具有信息技术特色的功能有:(1)管理员可选择在展台中展示的电子书;(2)系统捕获读者翻书意图,自动补完翻书动作,实现各种翻书效果;(3)自动循环播放电子书内容;(4)定位读者手指点,模拟鼠标点击,实现类似通用计算机软件应用的复杂和多样的人机交互.事实上,功能(4)对读者的操作提出了附加的要求,降低了阅读的沉浸感.在实现功能(4)的系统中,为激活鼠标点击操作,读者必须在特定区域停留一段时间.
第三,虚拟翻书系统必须实现如下几个质量属性需求[5]:(1)实时性,即必须实时识别并响应读者的动作,完成翻书操作,提升阅读的沉浸感和交互感;(2)准确性,必须准确地判定读者手势的语义,防止无响应或过度响应造成的抖动等现象;(3)拟真性,尽可能只要求读者遵守真实的翻书习惯,不设置额外的限制和要求;(4)可定制性,虚拟翻书系统可能需要适应不同的展台设备以及视频捕捉设备,由各种不同类型的读者使用,如儿童、残疾人等.
2 体系结构设计
软件体系结构是软件系统的高层蓝图,是凝结软件开发早期关键决策的制品.软件体系结构往往用于在软件开发早期分析和评价系统的质量属性,如性能、安全、可靠性等[6].本节首先给出虚拟翻书系统的总体架构,然后重点探讨其中的行为识别子系统的体系结构.
2.1 总体架构

图1 虚拟翻书系统高层软件体系结构图
人的运动可分为3个层次[8]:动作、行为和行动.动作是运动的基元,是最基本的运动,是形成其他复杂、 高级运动的基础,如读者的手或身体的移动.而行为则是一系列动作的集合,能够清晰地表示人的主观性和目的性,如读者的手在某个方向上持续移动,形成挥手的行为.我们将虚拟翻书系统划分为如图1所示的6个子系统.图1采用UML2.0[7]的符号体系建模.
电子书展示子系统负责为读者展现丰富的视音频及文字材料,需要能够屏蔽不同类型展示设备的异构性以及不同电子书操纵模式的差异,为行为实施子系统根据读者的行为操纵电子书提供规范的编程接口,如向前后翻页等.
视频捕获子系统负责管理视频监控设备,接收、整理、存储来自指定监控通道的视频数据.特别地,在通用的虚拟翻书系统中,视频捕获子系统需要能够屏蔽不同类型视频监控设备的异构性.
动作识别子系统负责分析捕获的视频帧序列,分析读者的动作轨迹,为根据读者动作所在区域、持续时间、运动方向和规律分析读者的行为语义奠定基础.动作识别子系统需要为视频捕获系统提供统一的编程接口,响应视频帧捕获事件.由于视频帧往往以固定的时间间隔到达,因此动作识别子系统必须满足一定的实时性需要,在下一个视频帧到达之前完成对当前视频帧的分析和处理.事实上,基于计算机视觉的人体运动识别问题是计算机视觉领域中的一个热点领域,且已经得到了广泛的关注,并产生了大量的成果[2].在虚拟翻书系统中,识别读者的挥手动作,甚至确定读者的指尖位置、手势等问题均存在较为成熟的算法[4].本文的目标不是研究更复杂的动作识别算法,而是对现有算法进行集成和应用,提升虚拟翻书的效果.在实现中,我们根据视频监控区域背景的性质,采用两种类型的算法捕获运动目标.在静态背景条件下,采用背景差分方法得到运动目标的位置和轮廓[9,10].在动态背景条件下,采用帧间差分方法得到运动目标的位置和轮廓.
行为识别子系统也是虚拟翻书系统的核心模块之一,它接收来自动作识别子系统的一系列动作数据,对其进行整合、分析,抽取出能够表达读者意图的行为,作为行为实施子系统执行各种翻书动作的依据.行为识别子系统须根据既定的行为语义规约,分析读者动作所在区域、持续时间、运动方向和规律,确定读者的意图.
行为实施子系统根据抽取出来的行为语义执行具体的翻书动作,如前翻一页、后翻一页、前翻多页、后翻多页等.行为实施引擎需要将行为语义转化为具体的电子书翻阅指令,如将前翻一页的语义转化为一系列的鼠标消息,模拟读者拖动鼠标翻阅电子书的过程.行为实施子系统是实现各种虚拟翻书系统中各种特定于信息技术功能的模块,如为了增强神奇感,还可以定义翻书时拖动鼠标的路径,实现不同的翻书效果,如水平方向拖动、抛物线方向拖动等等.
类似于动作识别子系统必须满足实时性需求,行为识别子系统和行为实施子系统也必须满足实时性需求,及时响应读者的行为启动相应的翻书动作.
翻书配置管理子系统允许管理员监控翻书系统的运行状态、调整虚拟翻书系统的各种配置选项,如调整所展示的电子书的内容、调整观测的视频通道、调整动作识别引擎所使用的算法以及算法的参数、定义行为模式、调整翻书动作的鼠标拖动路径、设置视频监控的范围以及灵敏度等等.其他5个子系统间接依赖于翻书配置子系统.
2.2 行为识别子系统
动作识别子系统负责捕获读者的动作,而行为识别子系统则负责接收来自动作识别子系统的一系列动作数据,对其进行整合、分析,抽取出能够表达读者意图的行为.已有的行为识别算法也有很多[2],本文结合观测区域、读者手运动趋势以及间隔时间等因素区分读者的行为语义.
2.2.1 翻书状态机
首先,我们给出如图2所示的虚拟翻书系统的状态机模型,作为定义不同翻书行为语义的基础.
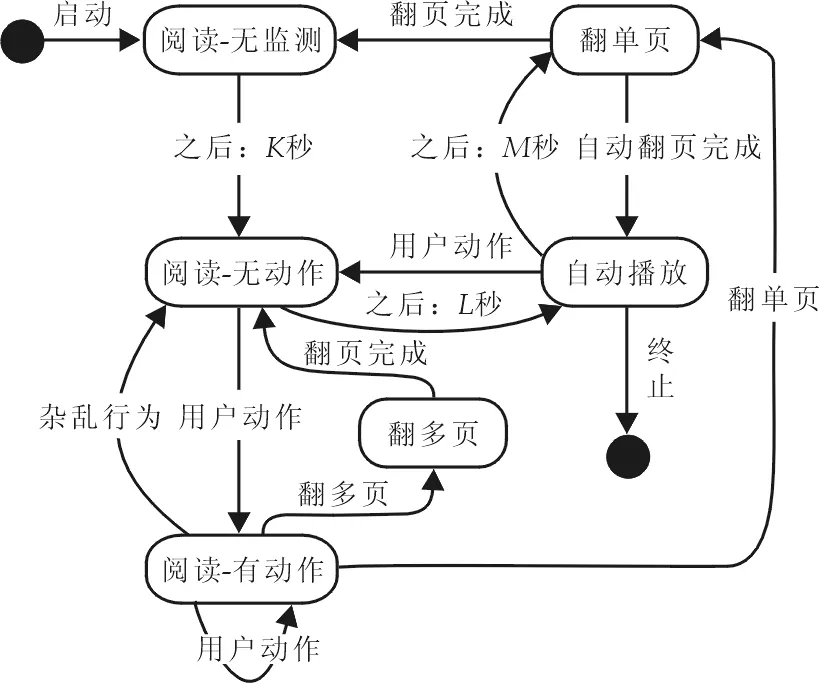
图2 虚拟翻书系统状态图
除去起始态和终止态之外,虚拟翻书系统具有 6个状态,分别是“阅读-无监测”状态、“阅读-无动作”状态、“阅读-有动作”状态、“自动播放”状态、“翻多页”状态以及“翻单页”等.
虚拟翻书系统启动后自动进入“阅读-无监测”状态.“阅读-无监测”状态中,读者可阅读电子书中当前页面内容,且为保证读者阅读免于偶然动作的干扰,规定此状态必须持续一定的时间(K秒),如K=60 s,在此期间的任何用户运动都不会引起电子书的误翻,从而保证了读者阅读过程的相对平稳.
当“阅读-无监测”状态持续K秒之后虚拟翻书系统进入“阅读-无动作”状态,虚拟翻书系统开始监控视频流中的用户动作.若监测到用户动作,则将用户动作存入一个动作队列,虚拟翻书系统进入“阅读-有动作”状态;若超过L秒仍未监测到动作,则虚拟翻书系统进入“自动播放”状态,开始循环播放电子书的内容.
在“阅读-无动作”状态中,虚拟翻书系统持续监测用户动作,并将其存入一个动作队列,同时对动作队列进行分析和整理,若发现匹配的翻书行为模式则清空动作队列并发出相应的信号,进入“翻单页”或“翻多页”状态.若动作队列与任何给定的行为模式都不匹配则定义为杂乱的行为,这时须清空动作队列并返回“阅读-无动作”状态.
在 “翻单页”状态,虚拟翻书系统模拟用户拖动鼠标的动作,完成电子书的单页前翻或后翻动作.“翻单页”包含翻页方向信息,如包括向前翻一页和向后翻一页等两种不同的翻页动作.在“翻单页”状态中,虚拟翻书系统停止监测用户动作.翻页完成后进入“阅读-无监测”状态,允许读者平稳地阅读电子书当前页面的内容.
在“翻多页“状态中,虚拟翻书系统允许读者向前或向后翻动多页电子书,快速浏览电子书,定位感兴趣的内容.“翻多页”号包含一些参数,如翻书的方向和翻动的页数等等.连续翻页过程中虚拟翻书系统不监测用户动作,但连续翻页完成之后,虚拟翻书系统返回到“阅读-无动作”状态,立即开始监测下一次连续翻页动作,而不同于从“翻单页”状态转移到“阅读-无监测”状态时必须停留K秒的时间窗不监测用户动作,为用户提供稳定的阅读时间.
若在“阅读-无动作”状态中停留L秒之后,虚拟翻书系统仍未监测到任何用户动作,则进入“自动播放”状态,虚拟翻书系统自动播放电子书内容供读者浏览.这时,虚拟翻书系统不监测用户动作,而是在停留M秒之后进入“翻单页”状态,执行翻单页的操作,翻页完成后返回“自动播放”状态,准备开始下一次翻页.
从图2可以看出,只有处在“自动播放”状态、“阅读-无动作”状态以及“阅读-有动作”状态时虚拟翻书系统才通过视频监测用户动作,施加这种限制能够极大地降低用户随机动作造成的误翻,而区分3类阅读状态则为读者阅读电子书内容提供了足够的稳定时间窗口.
2.2.2 翻书行为模式
用户的一系列动作构成了表达用户意图的行为模式.为提高拟真性、实时性和准确性,本系统不要求用户做出定点悬停以及其他更复杂的手势,用户只需通过简单的挥手动作来操作电子书,完成阅读所需的各种操作.例如,在面向书模的情况下,用户向左挥手则表示电子书后翻一页,向右挥手则表示电子书后翻一页.
为了模拟逐页阅读、快速浏览等实际阅读的需要,本系统采用观测区域与用户行为相结合的方式来表达4种翻书行为,即前翻一页,向后翻一页,前翻多页以及后翻多页.具体来讲,本系统将视频监测区域划分为上下(左右)两个区域,分别标示为A区和B区,并作如下约定:若在A区监测到用户左右挥手行为则将之翻译为“翻单页”信号,指示虚拟翻书系统前翻一页或后翻一页;若在B区监测到用户左右挥手行为则将之翻译为“翻多页”信号,指示虚拟翻书系统前翻多页或后翻多页.这样,就能较好地区分读者的4种翻书意图了.
为防止用户的偶然动作所造成的误翻现象,须对构成用户故意行为的动作序列做出一定的约束.我们对读者的行为进行如下形式的定义,并说明构成合法行为必须满足的约束.
定义1a= {mi|i= 1,…,N}分别表示用户向前翻书或向后翻书的行为,其中mi表示构成行为的用户动作,N是行为中动作元素的个数,每个动作是由水平方向r和水平d构成的一个二维向量,即mi=(ri,di),则称用户的行为a是合法的当且仅同时满足下面3个条件:
(1)N>M,其中M为给定的正整数,规定了构成行为的最少动作元素个数.适当的M取值能够防止用户偶然动作造成的抖动.
(2)mi,i= 1,…,N的方向ri均相同,意味着读者沿同一方向挥手翻书.
(3)di>D,i= 1,…,N,即每个动作的水平位移必须超过给定的阀值D,意味着读者翻书动作足够清晰、完整,能够充分表达读者的主观意图.
3 系统实现
图3是前台电子书展示系统的快照.图3(a)是向后翻一页,图3(b)是向前翻一页的情况.图4是后台翻书配置系统的快照.图4(a)是运行监控场景下的快照,图4(b)是配置参数时的快照,其中的红色网格表示执行翻书动作起始区域.

图3 虚拟翻书系统前台展示快照
当前虚拟翻书系统实现仅分析单个摄像头采集的连续视频帧序列,识别最基本、最常用的4种翻书行为,着重于保证系统的实时性、拟真性和准确性,这些功能和质量特征构成了系统的第一个发布版本.后续版本将来陆续实现更丰富的行为语义,为读者提供智能的、个性化的服务.例如,可采用2个摄像头配合工作的方式,从多个角度捕捉读者的手势动作,实现丰富的翻书行为语义,如回目录、定义书签等等;可采用摄像头和红外线感应器相互配合的手段,在不增加图像处理算法复杂度的情况下,尽可能地丰富翻书行为语义.

图4 虚拟翻书系统后台配置快照
4 结束语
本文总结了虚拟翻书系统的功能需求和质量属性需求,并给出虚拟翻书系统的一种参考软件体系结构,指出了系统实现必须注意的一些关键问题,证明了采用通用、简单、高效的动作识别和行为识别算法,配合适当的行为语义规约实现满足实时性 、拟真性以及准确性等质量属性需求的虚拟翻书系统的可行性,给出了建设通用的基于视频的虚拟翻书系统的参考方案.
参考文献
[1] 汪成为,高 文,王行仁. 灵境(虚拟现实)技术的理论、实现及应用[M].北京:清华大学出版社,1997:1-50.
[2] 杜友田,陈 峰,徐文立,等. 基于视觉的人的运动识别综述[J].电子学报,2007,35(1):84-90.
[3] 飞苹果,杨青青.电子互动虚拟翻书系统、电子互动虚拟控制系统[P].中国专利:200920213707,2010-8-18.
[4] 郭成玉,袁政鹏,吴家麒.基于手指点定位算法的新型虚拟电子书[J].计算机应用,2010,30(5):1 402 -1 405.
[5] 周 航. 基于计算机视觉的手势识别系统研究[D].北京:北京交通大学博士学位论文,2007.
[6] 梅 宏,申峻嵘. 软件体系结构研究进展[J].软件学报,2006,17(6):1 257-1 275.
[7] Bjerkander, M.,Kobryn, C. Architecting systems with UML 2.0[J].IEEE Software,2003,20(4):57-61.
[8] Bobick, A.F. Movement, activity and action: the role of knowledge in the perception of motion[J]. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, 1997,352(1 358):1 257-1 275.
[9] Yilmaz, A. and Javed, O. and Shah, M. Object tracking: a survey[J]. Acm Computing Surveys (CSUR),2006,38(4):1-45.
[10] 朱明旱, 罗大庸, 曹倩霞.帧间差分与背景差分相融合的运动目标检测算法[J].计算机测量与控制,2005,13(3):215-217.
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
铁道通信信号(2020年3期)2020-09-21
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2018年8期)2018-11-10
学与玩(2017年5期)2017-02-16
现代语文(2016年21期)2016-05-25
中国教育信息化(2015年10期)2015-08-23
儿童故事画报·发现号趣味百科(2015年5期)2015-07-22
大连民族大学学报(2015年2期)2015-02-27
出版与印刷(2015年4期)2015-01-03
