
图像数据挖掘技术研究及应用
2011-01-29 06:25王文渊
制造业自动化 2011年13期
王文渊
WANG Wen-yuan
(楚雄师范学院,楚雄 675000)
1 图像数据模型
图像数据挖掘模型主要有功能驱动模型和信息驱动模型。
1.1 功能驱动模型
功能驱动的图像数据挖掘是针对具体应用的特定要求来设计挖掘系统的驱动框架。MultiMediaMiner是以DBMiner系统和C-BIRD(content-based image retrieval from digital libraries)系统为基础发展起来的图像数据挖掘系统,它是典型的功能驱动模型[2],如图1所示。它由4个功能模块组成。图像采集器(excavator):从多媒体数据库中抽取图像数据。预处理器(preprocessor):提取图像特征,并把所计算的特征存放在特征数据库中。检索引擎(search engine):利用图像特征进行匹配查询。知识发现模块(discovery modules):对图像集进行特征描述、分类、关联规则挖掘、聚类等挖掘。
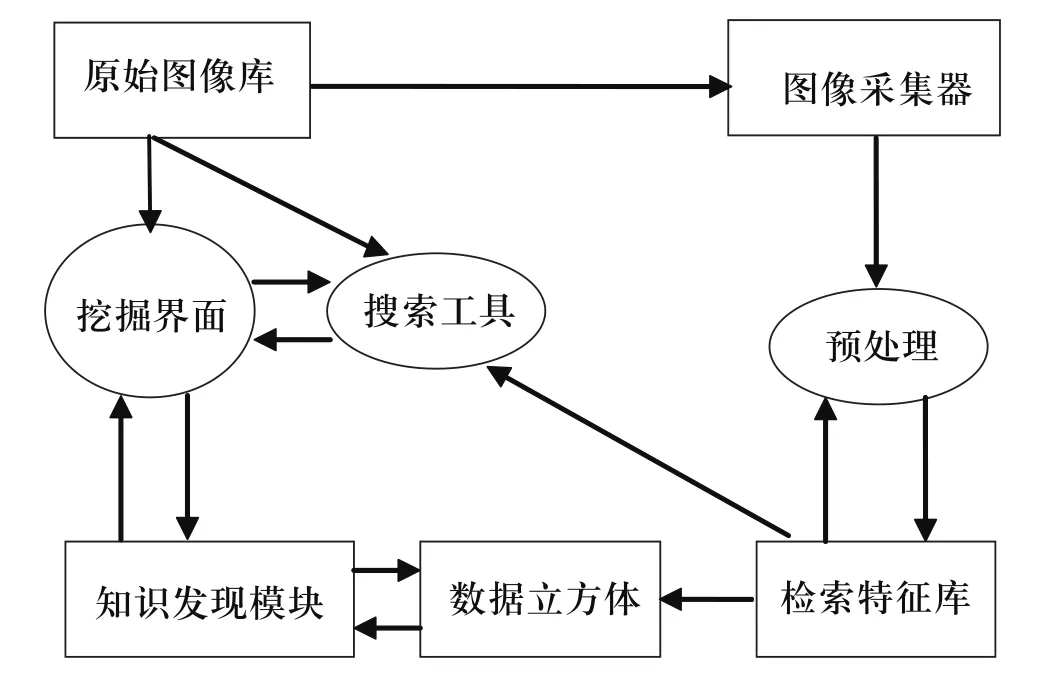
图1 数据挖掘功能驱动模型
1.2 信息驱动模型
Zhang[3]提出信息驱动模型是针对图像的原始信息,以基于内容的图像处理技术为基础的图像数据挖掘框架,主要强调不同的图像信息层次起到的作用不同。该模型首先根据图像的原始信息,以及基于原始特征的对象或区域信息,利用聚类算法和领域知识将图像分割成有意义的区域或对象,然后进行高层次的推理和挖掘,从而产生高层次的语义概念和有用的、易于理解的模式。该模型中图像信息分为4个层次[3]:象素层:由原始图像信息和原始图像特征组成,如象素点、纹理、形状和色彩等。对象层:处理基于象素层原始特征的对象和区域信息。语义概念层:结合领域知识从识别出的对象和区域中生成高层次的语义概念。模式知识层:可结合与某一领域相关的文字和数字信息发现潜在的领域知识和模式。在信息驱动模型中,象素层和对象层主要进行图像处理、对象识别和特征提取,而语义概念层和模式知识层主要进行图像数据挖掘和知识集成。该模型不仅只在图像的高层次进行挖掘,而且还可以扩展此模型以使挖掘能够在每个层次以及不同层次间进行。
2 图像数据挖掘技术
2.1 图像预处理
在大型图像数据库中存在许多脏数据和已破坏了的数据,这些数据能使挖掘过程陷入混乱导致不可靠的输出,有必要对数据进行清洗,以提高数据的质量。图像数据不仅数据量大,信息丰富,而且原始图像无法直接应用于数据挖掘,在使用挖掘工具之前,除了必要的数据清洗外,还要根据挖掘工具的特点和挖掘目的对图像数据进行必要的预处理。预处理主要包括可视特征提取、对象识别、数据规约、遥感数据离散化、图像融合等。
1)可视特征采用图像处理技术通过计算获得,主要包括颜色、纹理、形状等。颜色是应用最广泛的可视特征。颜色直方图用于存放图像对象中每种颜色的像素的比例,具有平移和旋转不变性,是最常用的颜色描述。纹理刻画了颜色和密度分布的均匀性,包含了表面结构和其与周围环境关系的重要信息,表示方法主要有:共现矩阵法,小波变换法等。形状表示法主要有基于边界表示的傅立叶描述法、基于区域表示的不变矩方法。
2)对象识别即在图像中识别出对象及其空间关系,涉及到的技术有图像分割、对象模型的表示及对象识别。
3)数据规约主要包括维规约和数据压缩,是为了提高挖掘质量和效率而进行的数据处理。
4)为了更好地提取图像特征,有必要进行图像融合,获取一种新型图像,其形态结构显示得更直观,可获取更详细、准确的特征。
2.2 图像数据的相似性搜索
对于图像数据的相似性检索,主要考虑了两种图像标引和检索系统:1)基于描述的检索系统,主要是在图像描述之上建立标引和执行对象检索;2)基于内容的检索系统,它支持基于图像内容的检索,如颜色构成、纹理、形状、对象和小波变换等.基于描述的检索若用手工完成是很费力的;若自动完成,检索的结果质量通常又较差。基于内容的检索使用视觉的特征标引图像并基于特征相似检索对象。
2.3 目标识别
目标识别一直是图像处理领域中活跃的研究焦点。这是图像挖掘领域中的一个主要任务。自动的机器学习和有意义的信息抽取能被实现仅仅在某些目标已经被机器识别的情况下。已知目标的模型通常由人工输入作为先验知识。
2.4 图像关联规则挖掘
关联规则挖掘主要根据图像中象素的光谱特征,构成纹理图像的各个象素、各个纹理基元之间都具有关联关系,这是关联规则挖掘能够用于图像的前提。要挖掘纹理图像的关联规则,我们可以把每一个图像看作一个事务,从中找出不同图像问出现频率高的模式。如果图像数据挖掘深入到象素级,则需要将一个象素及其邻域看作一个事务,从中找出在图像中重复出现的模式。在纹理图像中,这种模式实际上就是纹理基元。纹理基元有大小之分,这就要求在多个层次上多分辨率情况下进行挖掘。根据图像数据的矩阵表达方法,借助图像矩阵的事务数据模式化的方法,我们界定一系列图像事务定义。根象素:一个nⅹn邻域的根象素是这个邻域的中心象素,一个ⅹn的图像包含(N-n+1)2个根象素。项:所给定的根象素所在的邻域中每一个象素映射为一个项。通过一个元组(X,Y,I)来定义,其中X和Y分别是邻域中相对于根象素的偏移量,I是象素的灰度值。这样,一个具有G种灰度值的n Xn邻域中,可能产生n2G个不同的项。项集:一系列项的集合构成项集,实际上映射为图像中一系列相关象素集合。事务:同某一根象素相关的一系列项组成一个事务。确切地说,每一个根象素对应一条事务,邻域中每个项都可能进人事务。针对每个根象素,如果有K种偏移量情况,加之每个象素可以有G种可能的灰度值,因此,统计相同的偏移量所构成的事务,会产生Gk条事务。关联规则:一条关联规则表达了图像的局部结构,形式为(X1,Y1,I)∧…∧(Xm,Ym,Im)→(Xm+1,ym+1,I m+1)∧…∧(Xm+n,Ym+Im+n)(s%,c%)。例如,下面这条关联规则表示了在二值图像中,一个象素宽的垂直条带的右边通常为一个象素宽的白色条带。(0,1,l)∧(0,0,l)∧(0,-1,l)→(1,0,0)∧(1,1,0)∧(1,-1,0)(s%,c%支持度和置信度表明了这种情况出现的可能性。
2.5 图像分类和聚类
基于内容的智能图像分类可通过将图像与不同的信息类别相关联实现。图像分类是一种有监督学习方法,过程分3步:1)建立图像表示模型,对已进行类别标注的样本图像进行特征提取,建立每一图像属性描述;2)对每一类别的样本集进行学习,建立规则或公式;3)使用模型对未标注图像进行分类判决和标注。常用的分类方法有:判定树Bayes方法、神经网络方法,其它方法包括:K一最近邻分类、粗糙集分类等。图像聚类是依据没有先验知识图像的内容本身将给定的无标签图像集合分为有含义的簇,常用于挖掘过程的早期阶段,其特征属性是颜色,纹理和形状。
3 结束语
图像数据挖掘是目前国际上数据库、图形图像技术和信息决策领域最前沿的研究方向之一,是数据挖掘的一个新兴的富有挑战性的领域,具有较高的学术价值和广泛的应用前景。现阶段图像挖掘的理论与技术有待继续研究和完善,所以专门研究图像数据挖掘技术具有重要的意义。
[1]Burl M C,et al.Mining for image content[C]∥Systemics,Cy-bernetics and Informatics/Information System:Analysis and Synthesis.Orlando,FL,1999.
[2]Zaiane OR,Han JW.Mining Multimedia Data,Proceedings of CASCON98,Meeting of Minds,Toronto,Canada,1998:83-96.
[3]Zhang J.An Information–Driven Framework for Image Mining,Proceedings of 12th International Conference on Database and Expert Systems Applications(DEXA),Germa ny,2001-09.
[4]方玲玲,王相海.图像挖掘研究[J].计算机科学2009,8.
[5]薛丽霞,冀志敏,王佐成.图像纹理特征挖掘[D].计算机应用研究,2010.
猜你喜欢
农业工程学报(2022年7期)2022-07-09
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
吉林大学学报(理学版)(2020年3期)2020-05-29
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
自动化学报(2018年7期)2018-08-20
Coco薇(2017年8期)2017-08-03
自动化学报(2017年4期)2017-06-15
Coco薇(2015年5期)2016-03-29
