
基于H.264的视频编码技术研究
2011-01-24 13:59:46赵海国
湖南理工学院学报(自然科学版) 2011年2期
赵海国
(湖南理工学院 数学学院, 湖南 岳阳 414006)
视频信息因具有直观性、可信性等一系列优点而深受大众喜爱. 人类有 70%的信息是通过视觉获取的. 然而, 未经压缩的视频图像数据量非常大, 4:1:1格式分辨率为720×576的PAL视频每秒数据量可达124.4Mbit, 一张600MB的CD.ROM只能存储大约38秒的视频图像. 为了节约存储空间, 动态视频图像必须进行大幅度的压缩. 近年来, 新的视频图像压缩国际标准不断出现: 有用于电视会议的 ITU-T H.261标准, 用于可视电话的ITU-T H.263 标准, 用于动态视频图像的MPEG-1、MPEG-2 和MPEG-4 等视频标准, 目前最新的视频压缩标准为H.264标准.
H.264 作为新一代的视频压缩标准, 是由ITU 和ISO/IEC 两大国际标准组织共同制定的, 该标准最大的优势是具有很高的数据压缩比率, 且能够很好的适应当前复杂的网络环境, 但H.264编码复杂度也是最高的[1]. 所以, 掌握H.264视频压缩标准的编码原理及关键技术, 努力提高其编码质量和编码速度是值得研究的问题.
1 H.264视频压缩的编码原理
H.264是在MPEG-4技术的基础之上建立起来的[2], 其编解码流程主要包括5个部分: 帧间和帧内预测、变换和反变换、量化和反量化、环路滤波以及熵编码. H.264标准的具体编码框架如图1 所示.
与以往的视频标准类似, H.264的编码框架同样是基于混合编码的框架: 先将待编码宏块通过运动估计算法搜索帧内或帧间的相匹配宏块, 再将匹配宏块和待编码宏块的图像差值经过DCT 变换、量化等处理. H.264 标准通过改进技术方案大大提高了视频压缩效率, 并应用新的算法使视频编码性能在各个部分也得到了提升.
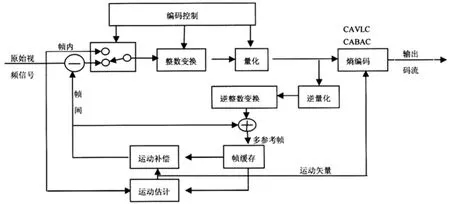
图1 H.264 视频编码基本框图
2 H.264视频压缩的关键技术
H.264视频压缩的关键技术[3]主要包括: 基于块的多种帧内预测, 树状结构的运动估计, 4×4 DCT整数变换, UVLC和CABAC熵编码模式.
H.264引入了多种帧内预测来提高压缩效率. 帧内预测编码就是使用周围邻近的像素值来预测当前的像素值, 然后对预测误差进行编码. H.264帧内预测是基于块的: 对于亮度分量, 块的大小可以在 16×16和 4×4 之间选择, 16 ×16 块有 4 种预测模式, 4×4 块有 9 种预测模式; 对于色度分量, 预测是对整个8×8 块进行的, 有 4 种预测模式. 在给定帧中充分利用相邻宏块的空间相关性. 在对一给定宏块编码时, 首先可以根据周围的宏块预测, 然后对预测值与实际值的差值进行编码, 相对于直接对该帧编码而言, 可以大大减小码率. H.264在帧内预测过程中, 只有预测块和实际块的残差才被编码传输,若对于变化平坦、存在大量空间冗余的视频对象, 利用帧内预测可以大大减少编码所需的比特数, 取得较高的编码效率. 可见, H.264使用帧内预测编码主要是缩减图像的空间冗余.
帧间预测编码是利用图像序列中相邻帧之间的相关性, 消除帧间的重复信息. H.264帧间预测涉及到的核心技术主要是运动估计与补偿[4]. H.264的运动估计采用树状结构运动估计, 在运动估计模块中采用16×16、8×16、16×8、8×8、4×8、8×4、4×4 七种块分割模式, 这种树状结构比以往的视频标准中的单一结构更科学, 对于小尺寸的宏块适合表现细节丰富的图像区域, 对于大尺寸的宏块适合表现图像内比较平坦的区域, 从而使得在同样码率的情况下, 视频图像质量得到提高. H.264的运动补偿相对于以往的视频编码添加了更多的功能, 除了支持 P帧、B帧外, 还支持一种新的流间传送帧——SP帧. 码流中包含SP帧后, 能在有类似内容但有不同码率的码流之间快速切换, 同时支持随机接入和快速回放模式. 可见,H.264帧间预测主要是应用树状结构运动估计和补偿缩减连续帧之间的时间冗余.
变换编码技术能够进一步提高视频压缩率. H.264 编码器对帧内预测所得到的残差结果, 使用4×4DCT整数变换. H.264 编码器使用的4×4DCT整数变换与其他编解码器采用的8×8 DCT 浮点数变换不同, 该变换方法不仅可在编码器和解码器中使用相同精度的变换和反变换, 而且有利于使用定点运算方式, 避免了浮点操作带来的四舍五入误差, 对信噪比的影响也小于 0.022dB. 另外, 该变换因为使用的4×4块比较小, 大大降低了图像的块效应, 还极大的减少了运算量.
H.264中采用了两种不同的熵编码方法: 通用可变长编码(UVLC)和基于文本的自适应二进制算术编码(CABAC). 在H.263等标准中, 根据要编码的数据类型如变换系数、运动矢量等, 采用不同的VLC码表.H.264中的UVLC码表提供了一个简单的方法, 不管符号表述什么类型的数据, 都使用统一变字长编码表.CABAC是一种效率很高的编码方法, 为了提高算术编码的效率, CABAC通过内容建模的过程, 使基本概率模型能适应随视频帧而改变的统计特性.
3 基于GPU的H.264并行编码器
H.264标准虽然压缩效率是最高的, 但其运算量也是所有压缩标准中最高的, 故其编码效率相对较低. 为了提高编码效率, 需要寻找一种有效的方法实现编码过程中耗时最长(占60%到80%)的模块——运动估计模块. GPU 就是一种很好的选择: GPU有着高度并行的计算特性、强大的浮点计算能力和很高的存储带宽[5,6], 将其应用到H.264的编解码中和CPU并行工作, 必将极大的提高视频编解码的效率, 于是便出现了基于GPU的H.264并行编码器. 基于GPU的并行解码器在充分利用GPU的并行特性的同时要处理好CPU和GPU这两个处理器的关系. 其解决方案为: I帧的编码完全由CPU负责, 而对于P帧,GPU负责每一个宏块的运动估计, 将求得的最佳运动向量值返回给CPU, CPU然后进行整数变换(ICD)、量化(Q)、反量化(IQ)、反整数变换(IICT)、运动补偿(MC)、重构和环路滤波. 这时CPU必须等待GPU处理完每一个宏块后才能进行后续的编码工作, 加速比取决于GPU的处理速度和回传数据时间与原先运动估计时间. 该方案中GPU的运动估计可将16×16的宏块分成16个4×4块, 然后计算出每个4×4块运动估计的代价并通过多次渲染将它们相加[7]; 进一步考虑到每个 4×4块先后存在着相关性, 可重新排列 4×4编码顺序实现4×4块的运动估计, 克服了相邻块之间的相关性问题; 还可将整个帧放入GPU中进行帧级别的运动估计, 引入更高效的搜索算法: 如适用于常见视频标准的16×16宏块单参考帧全搜索运动估计算法, 适合H.264标准的16×16宏块整像素和分像素多参考帧全搜索运动估计算法, 小钻石搜索模板的快速搜索算法[8]等等, 进一步减少了计算时间, 提高编码的效率.
基于GPU的并行解码器利用了GPU的并行特性, 但每次只对宏块进行并行处理, CPU和GPU必须实时交换小块的数据, 可能出现 CPU和 GPU相互等待的局面, 影响了编码的速度. 于是提出改进的CPU+GPU并行方案: 新的H.264编码器架构采用了两条并行流水线, 一条是CPU, 另一条是GPU. GPU上的流水线由于只负责运动估计(ME), 计算速度和I/O操作有关, 而不受CPU流水线影响. CPU之上的流水线不仅与I/O操作有关, 还需要使用GPU产生的7种可变尺寸块的最佳运动向量(MV)值. 为了减少CPU等待GPU产生MV值的时间, 同时也充分发挥GPU的并行计算能力, 开辟了一个共享缓冲区, 用来存放GPU求得的7种模式的最佳MV值. 这种CPU+GPU的H.264编码器并行架构, 使得CPU和GPU无须相互等待, 从而更高效的实现了CPU和GPU的并行工作.
4 结论
视频压缩技术不断在发展, H.264标准在数据压缩过程中采用一系列最新的压缩技术, 提高了压缩比率. 但同时也增加了算法的复杂度, 致使压缩效率大幅度降低. 论文引入了基于GPU的并行解码器, 充分利用 GPU的并行计算能力来实现编码过程中耗时最长的运动估计模块, 提高了编码效率. 为了减少并行过程中CPU和GPU相互等待的时间, 提出改进的CPU+GPU并行方案, 更高效地实现了CPU和GPU的并行工作, 有效地提高了视频编码的效率.
[1]刘 峰. 视频图像编码技术及国际标准[M].北京: 北京邮电大学出版社, 2005
[2]毕厚杰.新一代视频压缩编码标准[M].北京: 人民邮电出版社, 2005
[3]丁媛媛. H.264的视频编码关键技术研究[D]. 长春: 吉林大学通信工程学院博士学位论文, 2009, 6
[4]郑兆青. 基于H.264视频编码的运动估计VLSI结构研究[D]. 武汉: 华中科技大学图像识别与人工智能研究所博士学位论文, 2007, 2
[5]谭久宏, 周维超, 吴钦章.基于GPU的数字图像处理[J].科教文汇, 2006, 4: 178~179
[6]房 波.基于通用可编程GPU的视频编解码器架构、算法与实现[D].杭州: 浙江大学信息与电子工程学系硕士学位论文, 2005
[7]HO C W, AU 0 C,CHAN Get a1. Motion Estimation for H.264/AVC using Programmable Graphics Hardware[C].IEEE International Conference on Multimedia and Expo,2006
[8]LEE C Y,LIN Y C,WU C Let a1. Multi-Pass and Frame Parallel Algorithms of Motion Estimation in H.264/AVC for Generic GPU[C].IEEE International Conference on Multimedia and Expo, 2007: 1603~1606
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
电子设计工程(2015年24期)2015-08-26 06:39:42
电测与仪表(2014年13期)2014-04-04 12:04:18
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
