
基于Fast ICA的多说话人识别系统
2011-01-11 02:03周燕
苏州市职业大学学报 2011年2期
周 燕
(苏州市职业大学 电子信息工程系,江苏 苏州 215104)
说话人识别是根据语音波形中反映说话人生理和行为特征的语音参数,自动识别说话人身份的技术.说话人识别系统[1-2]可以分为单人和多人两种情况,多说话人识别系统是指能够自动地从混有多个说话人的语音中找到所需特定说话人的技术.其结构框图如图1所示.多说话人识别任务可以看成是一种盲源分离(blind source separation, BSS)[3]问题.独立分量分析(independent component analysis,ICA)[4]是近年来提出的非常有效的数据分析工具,主要用来从混合数据中提取出原始的独立信号.该技术在语音识别、通信、图像处理、医学信号处理等领域尤其受到关注.
独立分量分析目标函数的确定方法主要包括最大熵算法、最小互信息量算法和最大似然估计算法等,在独立分量分析的实现过程中,大部分的优化方法采用梯度算法.这些算法都是根据分离后信号的各分量之间的最大独立性来建立对比函数,从而寻找一种迭代算法来完成信号的分离.文献[5]中表明这些算法收敛速度慢、算法计算量高,而且经分离后的结果排序不定.针对上述问题,本文将快速独立分量分析(fast independent component analysis,Fast ICA)方法[6-7]应用于多说话人识别系统中,该方法基于固定点迭代理论寻找非高斯性最大值,每次只从观测信号中分离一个独立分量,是ICA的一种快速稳健算法,快速独立分量分析算法是并行分布式的,计算量小且要求的内存空间较少,能有效地从多人混合语音段中提取出单人纯净语音.
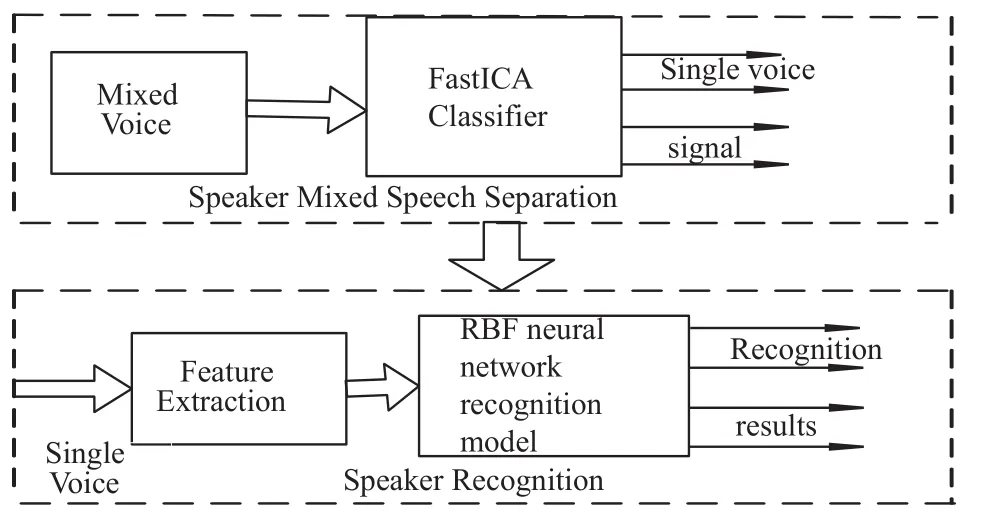
图1 多说话人识别系统框图
本文提出的多说话人识别系统由两个阶段组成,第一阶段采用快速独立分量分析方法来分离多个说话人的混合语音,第二阶段对分离出的单人语音分别提取MFCC特征参数,并作为RBF神经网络的输入样本集进行分析、学习、训练,求出输出层的权值并进行合并,进而实现多说话人身份的识别.
1 独立分量分析算法
ICA是对由独立语音源产生且经过未知线性混合的观测信号进行盲源分离,从而重现原独立语音源的技术.在分析过程中各个源信号之间是统计独立的且具有非高斯分布,假设n个观测数据x1,x2,…,xn由n个独立分量线性组合而成,观测变量和独立分量均为随机变量,则对于t时刻的n个观察值,有

令x=[x1,x2,…,xn]T,s=[s1,s2,…,sn]T,A=(aij),将上式写成矩阵形式x=As,其中A是未知的混合矩阵.独立分量分析就是计算分离矩阵W,从而使得u=Wx,ICA的线性模型如图2所示.
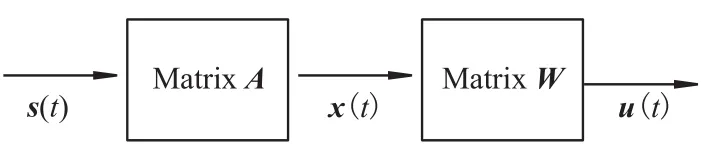
图2 ICA的线性模型
2 多说话人识别模型的建立
2.1 基于Fast ICA算法的混合语音分离
混合语音信号的分离就是要寻找合适的分离矩阵W,使得语音随机向量u=Wx的各分量间尽可能地独立.由于Fast ICA所具有的快速计算特性及处理海量数据的能力,所以选用该算法对混合语音数据进行分析处理.在Fast ICA中,各分量间的独立性是用负熵J(s)=H(sgauss)-H(s)来衡量的.并通过一个合适的非线性函数使其达到最优.计算步骤如下:
Step1,对观测语音数据x进行中心化,使它的均值为0.
Step2,对语音数据进行白噪声化,通过线性改变观测信号x,得到一个新的白噪声化变量x',使x'新的混合矩阵A'正交化,其关系为

Step3,选择需要估计的分量的个数m,用Fast ICA算法分离出s的各个分量.采用牛顿迭代算法,设迭代次数为p,选择一个随机的初始权矢量W(0),令其模等于1.
Step4,由x的采样点计算期望值,计算公式为
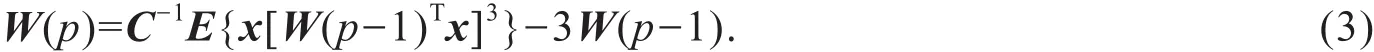
Step6,假如W(p)不收敛的话,返回Step5.
Step7,令p=p+1,如果p≤m,返回Step4.
Fast ICA能去除数据间的线性相关性.通过引入非正交基,Fast ICA考虑了数据之间的高阶相关性,而Fast ICA在分离变量的幅值和顺序上存在一定的不确定性,为消除幅度不确定性,通常假定分离变量的方差为1.
2.2 特征参数提取
对经过Fast ICA算法分离出的各路语音信号分别进行前端处理,主要针对测试语音中混有的干扰噪音,对输入语音依次进行端点检测、预加重、分帧、加汉明窗等以得到较为纯净的语音用于说话人识别.取语音数据帧长为n=256点,帧移128点,说话人特征提取,就是从这256个语音样本点上提取能反映说话人个性特征的参数.采用MFCC特征,每帧取16个MFCC系数,则获得了一个16维的向量.因此经过特征提取,语音帧序列{xi(n)│n=1,2,…,T}就变成了特征向量序列,其中xi(n)为16维向量,形成语音特征矢量序列.
2.3 RBF神经网络识别模型
说话人身份确认问题实质是一个二元取值问题,即要么接受,要么拒绝.据此,本文采用的RBF网络结构如图3所示,由于MFCC特征向量为16维,因此输入层节点 j=16,则网络模型为16-16-1结构.
模型中采用高斯函数Radbas作为径向基神经元的传递函数,采用3层结构即可实现输入、输出间的任意非线性映射,这使得该网络在模式识别与分类等领域有着非常广泛的应用.训练 (学习 )算法是指以满足网络所需性能为目标,决定各联接神经元的初始权值以及在训练过程中调整权值的方法.本文采用的学习算法是正交最小二乘法(OLS),该算法首先选择输入向量的子集作为RBF传递函数的初始权值向量,然后从一个神经元开始每迭代一步增加一个RBF神经元,采用OLS算法找出最合适的输入向量来增加RBF的权值向量.每一步计算出目标向量与RBF网络学习输出向量间的误差平方和,当达到设置的误差指标或达到最多神经元个数时,训练结束.

图3 RBF神经网络结构模型
3 仿真实验
实验选择10组混合语音,每组混合语音是由随机的2名试验者的混叠语音信号组成.实验要求识别出20名试验者的身份.在安静环境下,用麦克风分别录下试验者的语音信号,分别生成波形文件Signal. wav;实验者以平稳语速从1数到10,该文件采样频率为16 kHz、双声道,以保持语音或噪声信号不失真.程序中将采集的语音样本中的波形文件随机两两混合,形成10个混合语音样本,则混合矩阵随机产生.
实验过程中先对混合语音进行去均值和白噪声化处理,再用Fast ICA算法进行分离信号,图4给出了其中一组混合语音的处理结果.由图4可见,经Fast ICA算法分离出的语音信号从波形上很好地保持了原始信号的波形,几乎没有失真,但用独立分量分析中的等变量自适应分离算法(EASI)分离出的波形效果就有所失真了.

图4 混叠语音分离过程
将分离出的语音信号提取16维的MFCC特征,并由RBF神经网络对特征向量进行训练、识别.由图5可以看出采用RBF神经网络、Hopfiled神经网络及BP神经网络所取得的误识率,显然,采用RBF神经网络能得到较好的识别效果.
4 结 论
本文采用基于Fast ICA算法的RBF神经网络实现多说话人识别.Fast ICA算法计算量小,算法效率高,能有效地将混合语音实现分离.RBF神经网络结构简单,具有优异的函数逼近能力,收敛速度快.对分离后的信号进行特征提取后,采用RBF神经网络作为分类器能有效地实现多说话人识别系统,实验结果表明,该系统具有较高的识别率.
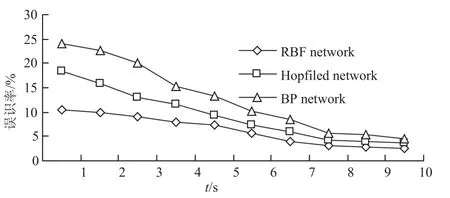
图5 误识率比较
[1] BENZEGHIB M, MORI R D. Automatic speech recognition and speech variability: A review[J]. Speech Communication, 2007,49(10/11):763-786.
[2] 王书诏,邱天爽. 说话人识别研究综述[J]. 语音技术,2007,31(1):51-55.
[3] SMITH D, LUKASIAK J, BURNETT I S. An analysis of the limitations of blind signal separation application with speech[J]. Signal Processing, 2006,86:353-359.
[4] PLUMBLEY M D. Conditions for nonnegative independent component analysis[J]. IEEE Signal Processing Letters, 2002,9(6): 177-180.
[5] 余淑萍,杨铁军. 独立分量分析及其应用[J]. 计算机系统应用,2009(9):156-158.
[6] HYVARINEN A. Fast and robust fixed-point algorithm for in-dependent component analysis[J]. IEEE Transactions on Neural Networks, 1999,10(3):626-634.
[7] 钟静,傅彦. 基于快速ICA的混合语音信号分离[J]. 计算机应用,2006,26(5):1120-1124.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
基层中医药(2021年12期)2021-06-05
中国特种设备安全(2021年9期)2021-03-02
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
智族GQ(2019年9期)2019-10-28
测控技术(2018年2期)2018-12-09
英美文学研究论丛(2018年1期)2018-08-16
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
通信电源技术(2016年3期)2016-03-26
