
基于决策树技术的预离网客户识别模型
2011-01-10 03:37李智勇
成都大学学报(自然科学版) 2011年4期
李智勇,冷 夔
(中国移动通信集团四川有限公司,四川成都 610072)
0 引 言
随着电信企业重组,市场竞争进一步加剧,客户流失已经成为各运营商关注的重点.据2011年数据,某通信运营商4月离网率高达5%,预测全年离网率达40%,此对其市场竞争力和盈利能力产生了较大的负面影响.因此,利用系统中的客户数据,采用数据挖掘工具对客户离网行为进行挖掘分析,力争以高效率、低成本进行存量客户的保有,已成为通信运营商亟待解决的问题.本文以CRISP-DM(跨行业数据挖掘过程标准)以及决策树分析方法为工具,从商业理解、数据理解、数据准备、建立模型、模型评估和结果部署6个阶段,构建起预离网客户识别模型.该模型经系统固化,定期识别出目标客户明细,通过有针对性进行保有工作,取得了良好的成效.
1 预离网客户识别商业理解
预离网客户识别商业理解,是指从商业角度理解项目的目标和要求,然后把理解转化为数据挖掘问题的定义和一个旨在实现目标的初步计划[1].
1.1 确定商业目标
通常,客户在从正常到离网的整个过程中,其状态一般会依次经历正常、沉默、预拆、离网等状态.处于各状态的客户,其接触的难度也依次加大,由易于接触、可接触、难以接触到不可接触.经过数据探索发现,95%的正常客户在离网前会沉默,90%的沉默客户会离网.为确保预离网客户的可接触性,保证客户保有的实际效果,需将预离网客户的目标状态适当前移,即以沉默客户为主进行实际保有工作.
1.2 形势评估
客户离网原因包括:因所在地点变动而产生的自然流失,因选择了不合适的资费或者不满通信运营商的服务而产生的主动离网,因竞争对手采取了营销手段而产生的策反流失等,具体分析如表1所示.

表1 客户离网原因
1.3 数据挖掘目标
数据挖掘目标为:预离网客户查准率≥85%;查全率≥80%.
2 数据理解与准备
数据理解与准备包括:原始数据的收集,熟悉数据,标明数据质量问题,探索对数据的初步理解,发觉有趣的子集以形成对隐藏信息的假设[1].
2.1 数据准备
数据准备包括:提取客户自然属性、身份属性、品牌属性、资费属性、消费属性、行为属性、业务属性和其他属性8大类140余个字段,作为数据建模的基础数据.
2.2 数据清洗与变量选取
选取11万已离网的客户,以及110万在网客户,对其历史自然属性、身份属性、品牌属性、资费属性、消费属性、行为属性、业务属性和其他属性进行比对,利用SPSS的Clementine软件对建模字段进行数据审核和探索,清洗掉对客户离网影响概率很小的字段,留下66个影响字段.
3 模型建立
3.1 建模技术
本文采用决策树算法[2]建立预离网客户识别模型,具体步骤为:首先,选择预离网客户最有代表性的变量——话费余额作为决策树的根节点,对引起话费余额变动的各项因素进行判断;其次,根据离网客户的特征并和在网客户特征进行对比,判断出各项因素所反应出的客户离网的概率;最后,建立起预离网客户识别模型决策树.图1为预离网客户识别模型决策树,由于变量众多,适用于预离网客户的规则就达658个,图1仅展示前4层节点.
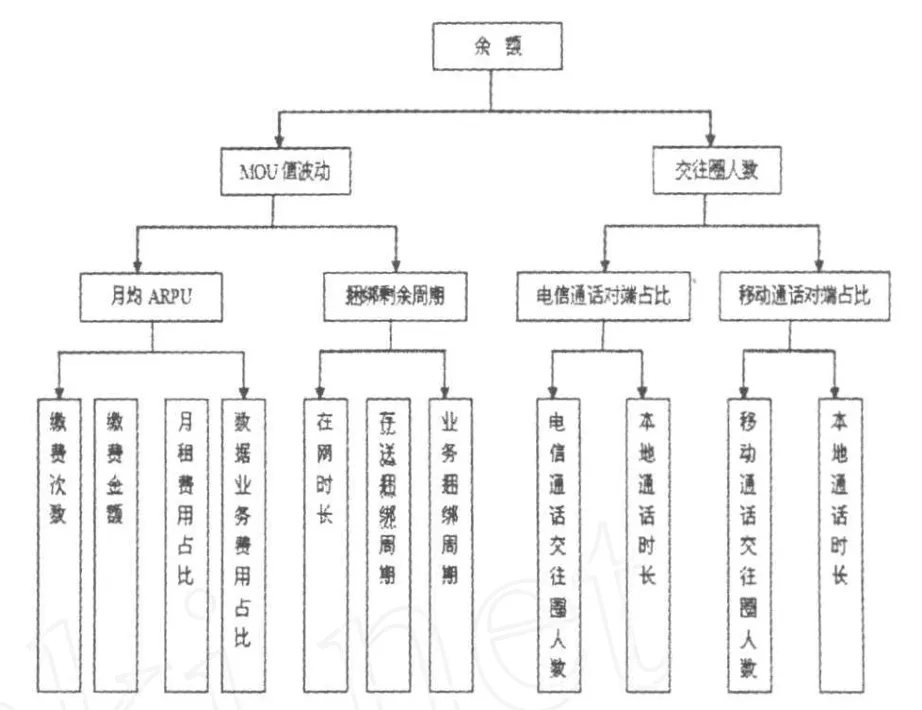
图1 预离网客户识别模型决策树模型
3.2 模型建立
模型建立的具体步骤如下:
(1)数据平衡.为了对比离网客户的特征,提炼客户离网前的行为特征、消费特征、业务特征等信息,将提取的11万离网客户和110万在网客户近3个月的属性数据,经过清洗和平衡,使离网客户与在网客户在数量上达到1∶4的比例.
(2)数据分区.将经过平衡以后的数据,经过随即抽取,其中,80%的数据作为模型训练区,20%的数据作为验证测试区.
(3)决策树模型构建.将模型训练区的数据通过SPSS的二元分类器对客户属性数据进行评估,利用Logistic回归模型得出客户离网在每个属性字段上的概率.图2展示了前4层结果,其中:0为离网客户,1为在网客户.
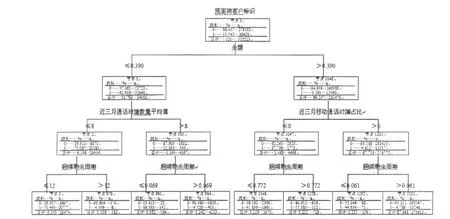
图2 预离网客户识别模型
(4)修剪分支.在决策树中,我们发现主资费、入网渠道、投诉次数、农村客户属性、家庭客户属性和集团客户属性6个要素对于客户离网影响概率极低,可将其作为无关分支进行修剪.
(5)建立预离网客户模型.经过修剪分支后,根据决策树节点模型所计算出的单个字段概率,对单字段进行组合计算,构建预离网客户识别模型规则,其结果如表2所示.
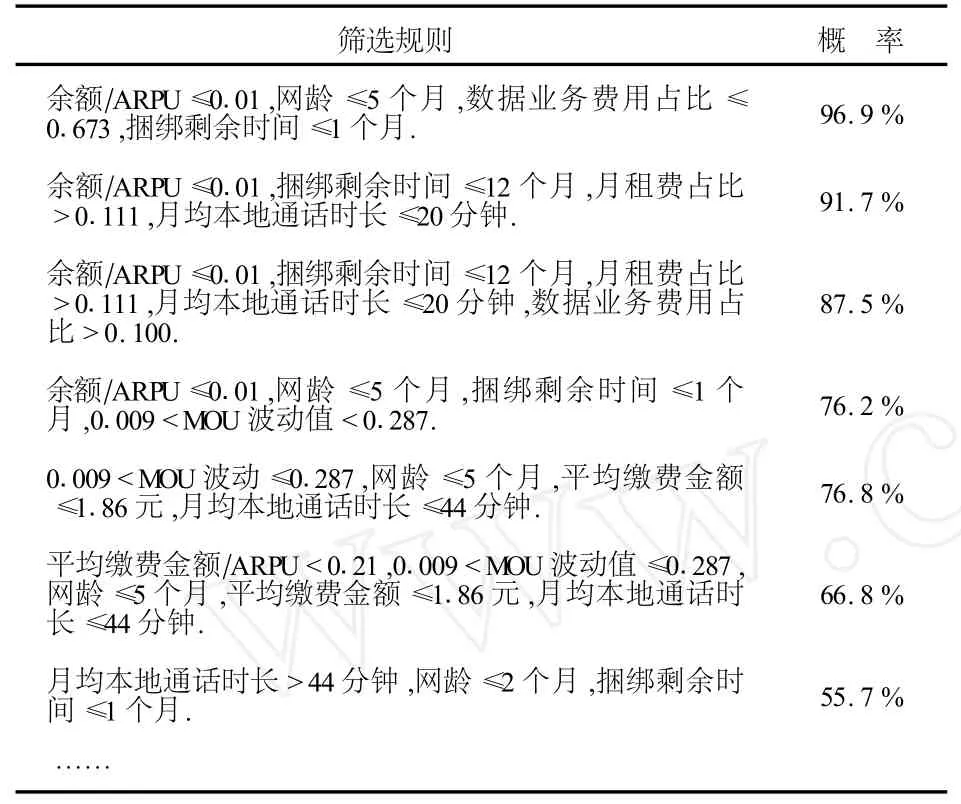
表2 预离网客户识别模型及筛选规则
(6)模型输出.沉默客户模型主要输出3个字段:沉默标识、沉默概率、沉默原因.
沉默标识可以用来识别客户是否疑似沉默客户(0为否,1为是);沉默概率可以用来作为客户是否疑似沉默客户的概率(介于0到1之间),如一个客户的目标标识为1,目标可能性为0.9的要比0.7的更可能成为沉默客户.部分结果如表3所示.
4 模型评估
模型评估的关键目的是,决定是否存在一些重要的商业问题仍未得到充分地考虑.关于数据挖掘结果的使用决定应该在此阶段结束时确定下来.通常,通信运营商利用模型增益和测试集查全及查准率进行模型评估工作[1].
4.1 增益评估
增益图是不同阀值下命中率(PV+,正确预测到的正例数占预测正例总数的比例)与预测成正例的比例(Depth)的轨迹.随着阈值的减小,更多的客户就会被归为正例,也就是Depth变大,这样PV+就相应减小.一个好的模型,在阈值变大时,相应的PV+就要变大,曲线足够陡峭.
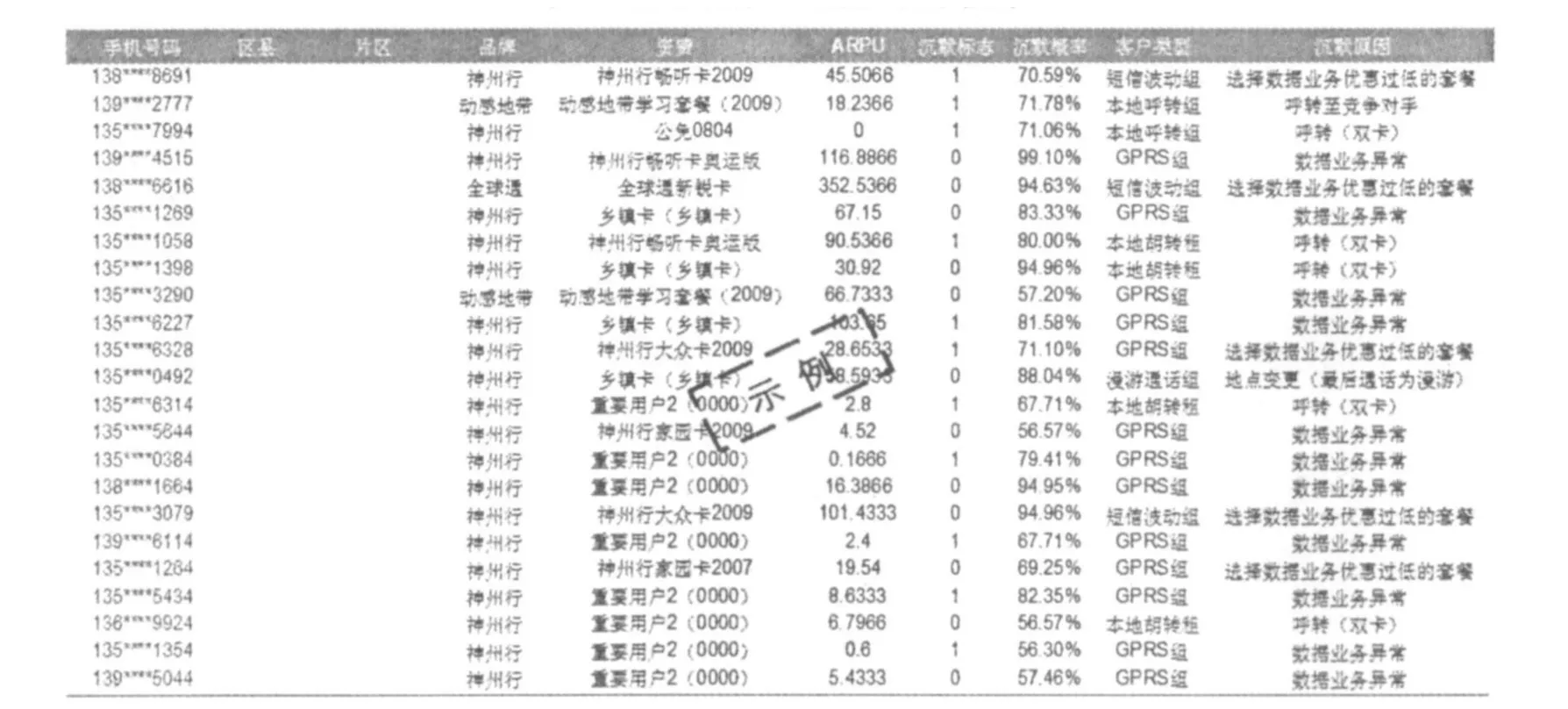
表3 预离网客户识别模型结果输出
如图3所示,在阀值设定为20%的时候,曲线足够陡峭,表明本模型效果较好,通过实际的使用,我们发现使用模型之后效果提升了约4.2倍.
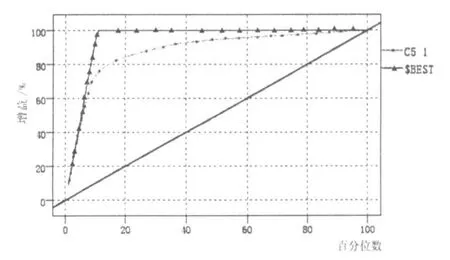
图3 增益评估图
4.2 查全查准评估
查全查准评估通常采用查全率与查准率来评价.

在模型建立初期,由历史上已离网客户与在网客户数据按1∶4比例进行了数据平衡,并且从中随机抽取了80%的数据作为模型训练区,20%的数据作为验证测试区.经过模型对训练区数据进行识别,并与验证测试区数据进行对比,得出预离网客户识别模型的查全率和查准率为,
查全率=70987/(70987+17013)=80.67%,
查准率=70987/(70987+12081)=85.46%.
5 模型识别效果与结论
5.1 模型识别效果
根据2011年4月某通信运营商数据,本预离网客户识别模型识别出106 012户具有离网倾向的客户,参与营销活动的客户有16 432户,营销效率为15.5%.通过跟踪分析发现参与活动的客户,5月份状态正常的客户超过90%,而未参加活动的客户状态正常的仅达40%左右;参加活动的客户人均MOU值提升了29.41%,人均ARPU值提升了23.67%.仅计算成功挽留的客户就为公司节约新客户拓展费用约500万元.
5.2 结 论
根据CRISP-DM(跨行业数据挖掘过程标准)方法所建立的预离网客户识别模型经市场实践,证明其是准确而有效的.但是该模型仍然存在以下两个方面的问题需要完善:一是季节性缺陷.根据市场规律,每年3~4月是市场淡季,客户离网率急剧上升,而模型根据前3个月离网客户的数据进行分析,在市场淡季时,参数可能会出现偏差,影响模型的准确性.二是时效性缺陷.由于计费系统设计,客户消费的出账时间间隔为一个月,因此对于预离网识别模型中相当重要的指标如ARPU值、MOU值等每个月才能获取一次数据,造成预离网客户识别每个月才能提取一次客户数据.而在实际市场环境下,客户离网是随时发生的,因此预离网客户识别模型难以在第一时间就识别出预离网客户,影响了营销效率的提高.
[1]CRISP-DM协会.CRISP-DM 1.0数据挖掘方法论指南[EB/ OL].[2002-04-15].http://2011down.com/detail/gFiuTih.
[2]王桂芹,黄道.决策树算法研究及应用[J].电脑应用技术,2008,20(1):1-5.
[3]张献华,田亮,叶幸春.基于决策树的数据挖掘技术在电信用户流失预测的应用与研究[J].中国新通信,2007,9 (14):79-82.
[4]管东升.移动通信客户流失行为预测技术的研究[J].电脑开发与应用,2005,21(10):57-59.
[5]王姝华,钟云飞.数据挖掘在移动通信业大客户离网预测中的应用[J].江苏通信技术,2004,20(3):1-4.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
现代电子技术(2018年16期)2018-08-21
现代电子技术(2017年23期)2017-12-20
电力与能源(2017年6期)2017-05-14
计算机应用(2016年10期)2017-05-12
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
