
一种基于本体相似度的Web服务匹配算法
2011-01-09 05:49殷华英刘训沛耿硕阳
承德石油高等专科学校学报 2011年3期
殷华英,刘训沛,耿硕阳
(1.承德石油高等专科学校计算机与信息工程系,河北承德 067000;2.辽宁大学 信息学院 ,辽宁 沈阳 110036)
一种基于本体相似度的Web服务匹配算法
殷华英1,2,刘训沛2,耿硕阳2
(1.承德石油高等专科学校计算机与信息工程系,河北承德 067000;2.辽宁大学 信息学院 ,辽宁 沈阳 110036)
服务匹配也被认为是基于本体概念的相似度计算。针对本体结构中概念之间的IS-A关系,通过对语义相似度相关算法的研究,提出了一种结合信息论模型和语义距离模型的相似度算法,并在此基础上上构建了二层服务匹配模型,从而实现了对服务的有效区分和匹配。
本体;概念;相似度;语义距离;服务匹配
Web服务是架构在XML和Internet技术之上的分布式计算技术,作为一种基于网络环境的自适应、自描述、模块化的应用程序,因其具有良好的互操作性和可重用性,在电子商务、应用集成、流程管理等领域中得到了越来越广泛的应用[1]。随着互联网应用技术的发展和应用需求的需要,互联网上出现了越来越多的Web服务,这样如何从这些服务当中快速有效的发现自己需要的服务就成为一个急需解决的问题。
作为一个提供发布和查找的基础架构规范,UDDI提供了对服务注册信息进行关键字精确匹配的服务查询,但因为缺乏服务的语义信息,在服务的查准率和查全率上都不是很令人满意。目前,基于语义的Web服务匹配己经引起了国内外学者越来越多的重视,成为Web服务研究的热点之一。这类方法也被认为是应用前景最广阔的服务匹配方法。在这类方法中,通过语义Web技术,将基于本体的知识标注为Web服务增加语义信息,从而增强了Web服务的语义描述能力,为Web服务的匹配提供了语义层上的支持。目前,服务匹配过程大多是以Web服务模型OWL-S为基础,根据本体中概念之间的关系,结合语义逻辑推理、语义相似度计算等方法实现的。和传统的基于关键字的服务匹配方法相比,在服务的查全率和查准率上,效果会有显著改善。
1 本体相似度的混合算法
1.1 算法思想
[2]中给出的方法,本文在此基础上提出了一种本体语义相似度的混合计算方法。针对本体中概念之间只存在IS-A类型的关系,对关系权值的计算进行了简化。通过对基于网络距离模型和基于信息论模型的两种方法进行综合,提出了一种简单高效的计算相似度的方法。先利用信息论模型计算概念出现的概率和包含的信息量,再根据概念的信息量计算连接边的权值,最后利用网络距离的方法求出概念间的最短语义距离,由此求出概念之间的相似性。
1.2 相关公式
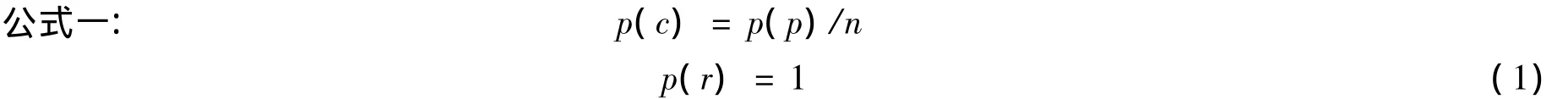
该公式用来计算概念层次结构树中概念c出现的概率。其中r为根概念,p为概念c的父概念,n为概念p的直接子概念个数,p(c)为概念c的出现概率。
对于概念出现概率的计算,本文未采用文本集统计的方法,而是将整个本体看成是一个大样本空间。在只存在IS-A关系的本体中,在计算概念出现的次数时,如果某个概念出现一次,则认为它的所有父概念都出现一次,反过来,也即计算某概念的出现次数时应将其所有后代概念的出现次数累加起来。对于根概念,它包含其它所有概念,认为它的出现概率为1,其它的节点出现概率可按照此公式递归求出。

该公式用来计算领域本体中概念c包含的信息量。p(c)为概念c的任一实例出现的概率,Ires(c)为概念c的信息量。可知,随着概念概率的增加,它所包含的信息量是逐渐减小的。


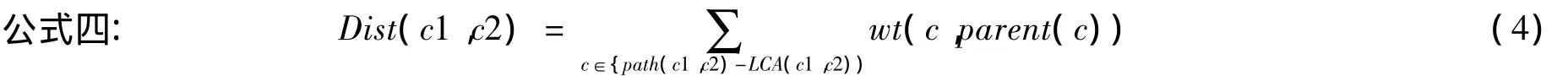
该公式用来计算概念c1和概念c2最短语义距离,由概念c1、c2连接路径上的边的权值累加求和得出。其中:parent(c)为概念c的直接父节点。path(c1,c2)为概念c1、c2连接路径中的所有概念节点,包括c1和c2概念节点。LCA(c1,c2)为c1、c2的最近共同祖先,在计算时,应将LCA(c1,c2)排除在外。
1.3 算法过程
计算概念间的语义距离,就是计算它们连接路径上的边的权值之和,而边的权值确定,需要从根概念开始计算每个概念所包含的信息量,然后再根据信息量确定相邻概念间连接边的权值。
定义1 概念c1,c2的生成子树:从根节点到概念c1、c2连接路径上的所有节点构成的树。
定义2 概念c1,c2的最小生成子树:从概念的最近共同祖先到概念c1、c2连接路径上所有节点构成的树。
具体过程分为以下3步:
step1:从概念节点c1、c2回溯到根节点,确定概念的生成子树、最小生成子树。
step2:从根节点往概念节点c1、c2扫描,计算概念c1、c2的生成子树上每条边的权值。
step3:对概念c1、c2的最小生成子树中的每条边的权值累加,并进行相似度转化,即为所求结果。
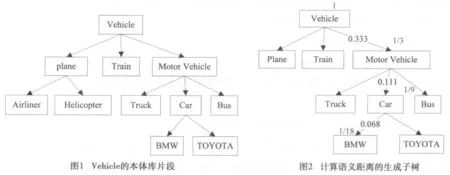
下面以图1的Vehicile本体中概念BMW和Car为例说明计算相似度的计算过程。
计算生成树上的各个概念的出现概率和包含的信息量:
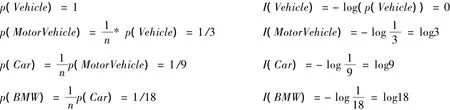
计算连接边的权值:

最终的计算结果如图2所示。
则概念BMW和Car的语义距离dist(BMW,Car)=0.068。
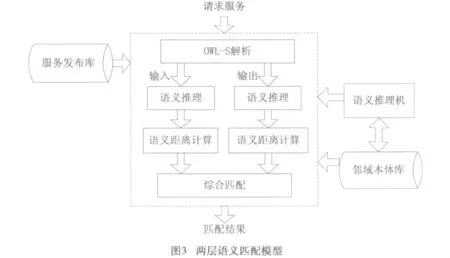
2 两层服务匹配模型
给出本体概念相似度计算方法之后,就可以把它应用于语义Web服务的匹配。一般来讲,对服务的匹配主要是通过对服务的IOPE进行匹配来实现的,根据本文的算法,本文关注的是对服务IO的匹配。服务W的描述如下:
W={WName,WIn,WOut},其中:
Wname为服务的名字;
WIn=<in1,in2,...inn>为服务的输入参数集,是实际输入参数在领域本体库中对应的概念表示;
WOut=<out1,out2,...outn>为服务的输出参数集,是实际输出参数在领域本体库中对应的概念表示。
为减少服务匹配的规模,降低问题的复杂度,在对服务的IO进行语义相似度计算之前,先进行语义推理,排除那些不符合条件的服务。首先对比较的两个服务利用OWL-S解析,获取服务IO的相关概念,再利用Paolucci[3]提出的方法进行语义推理,进行第一层语义匹配。然后根据匹配结果,来决定下一步是否进行语义距离的计算。当结果为Exact服务匹配成功时,或者Fail,服务完全不匹配时,这时就不再进行后面的语义距离计算,只有在语义推理结果为PlugIn或Subsume,提供的服务能部分满足请求服务时,才使用本章提出的算法进行概念的语义距离计算,对请求服务和提供服务的输入、输出进行语义距离计算。最后将对输入、输出语义距离计算的结果进行综合和排序,返回给服务请求者。这是第二层的匹配。两层的语义匹配模型结构图如图3所示。
3 结束语
在服务匹配和发现中,传统的UDDI基于关键字和简单分类的发现机制已经不能很好的满足要求,存在查全率和查准率较低的情形。本文通过对两种相似度算法—基于网络距离模型和基于信息论模型的有效融合,提出了一种基于IS-A关系的概念相似度混合算法,该方法计算过程简单,复杂度低,并和语义推理方法结合起来,搭建了一个两层语义匹配模型。通过该模型,可以有效地、准确地对Web服务进行区分和匹配。
参考文献:
[1] 俞坚,韩燕波.面向服务的计算—原理和应用[M].北京:清华大学出版社,2006.
[2] Conrath D.,Jiang J.Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy.In Proceedings of International Conference on Reaseareh in Computational Linguistics,Taiwan,1997.
[3] Massimo Paolucci,Takahiro Kawamura,Terry R.Payne,et al.“Semantic Matching of Web Services Capabilities,”I In Computer Science,2002,Vol.2342:333 -347.
[4] Lin Dekang.An information - theoretic definition of similarity.in proceedings of the 15th international Conference on Machine Learning,Madison,Wisconsin,1998.
A Web Service Matching Algorithm Based on Similarity of Ontology
YIN Hua-ying1,2,LIU Xun-pei2,GENG Shuo-yang2
(1.Department of Computer and Information Engineering,Chengde Petroleum College,Chengde 067000,Hebei,China;2.Information School,Liaoning University,Shenyang 110036,Liaoning,China)
Service matching is also considered to be the concept of ontology-based similarity calculations.For the IS-A relationship between the concepts of ontology structure,the paper puts forward a kind of similarity algorithm that combines information theory model with semantic distance model through the research to semantic similarity algorithm.Based on this,it also builds up a second service matching model to fulfill the effective distinguishing and matching service.
ontology;concept;similarity;semantic distance;service matchmaking
TP393
B
1008-9446(2011)03-0050-04
2011-05-31
殷华英(1976-),男,河北承德人,承德石油高等专科学校计算机与信息工程系讲师,主要从事计算机软件教学工作。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
哈哈画报(2021年10期)2021-02-28
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
沉积与特提斯地质(2019年4期)2019-07-19
西南交通大学学报(2018年5期)2018-11-08
自动化学报(2017年7期)2017-04-18
制造业自动化(2017年2期)2017-03-20
现代电子技术(2016年15期)2016-12-01
新闻传播(2016年11期)2016-07-10
武夷学院学报(2014年5期)2014-07-19

- 承德石油高等专科学校学报的其它文章
- 姬塬油田长4+5油藏开发特征及稳产技术对策
- 抽油机井智能抽空控制技术研究
- 智能红外线自动垃圾桶设计