
个性化搜索引擎算法研究
2010-12-27 01:05胡立娜
河北省科学院学报 2010年3期
胡立娜
(河北省电子信息技术研究院,河北石家庄 050071)
个性化搜索引擎算法研究
胡立娜
(河北省电子信息技术研究院,河北石家庄 050071)
搜索引擎是用户利用网络资源不可或缺的工具,但目前搜索引擎的查准率有待提高。对于不同的用户而言,即便是相同的查询词其期望的查询对象可能不同,那么搜索引擎此时的查准率其实就是让搜索引擎具有个性化搜索的特点。个性化搜索引擎的关键是用户兴趣的确定和文档兴趣值的确定,只有把抽象的个性化兴趣量化成数值类的模型,才可以了解用户真正的需求和量化文档与兴趣的相关程度,从而准确地对网页进行筛选并达到个性化排序的功能。
搜索引擎;网络蜘蛛;PageRank;感觉查询;反馈技术
1 引言
面对浩瀚的网络资源,搜索引擎为所有网上冲浪的用户提供了一个入口,毫不夸张的说,所有的用户都可以从搜索出发到达自己想去的网上任何一个地方。因此它也成为除了电子邮件以外最多人使用的网上服务。现在有很多帮助大家查找信息的搜索引擎,比如现在大家普遍使用的 Yahoo,sina,百度,google等,这四种搜索引擎已经成为现在人们使用最多的搜索引擎,是目前使用量最大的工具之一。从国内外对因特网环境下的搜索引擎研究的现状来看,随着信息的指数倍增长,真正意义上的搜索引擎Lycos创建于1994年,Spider程序被首次应用到其索引程序中;随Yahoo.Google等搜索引擎的出现,搜索引擎的发展也进入了黄金时代,但是就算是目前最好的搜索引擎所提供的结果也并不太令人满意,搜索引擎目前仍然存在很大局限性,总的来说主要包含信息丢失、返回无用信息及信息无关等几个方面。用户迫切需要更完善的搜索引擎来满足更方便、更快、更精确的查询需要。
2 搜索引擎的构成
2.1 搜索引擎概述
搜索引擎是根据用户的查询请求,按照一定算法从索引数据中查找信息返回给用户。为了保证用户查找信息的精度和新鲜度,搜索引擎需要建立并维护一个庞大的索引数据库。系统结构如图1。

图1 系统结构图
2.2 搜索引擎的构成
搜索引擎是一种最为常见的Web信息检索系统,主要由以下几部分组成:
2.2.1 网络机器人
网络机器人就是我们常说的 robot或者是craw ler,它能定期根据预先设定的地址去查看对应的网页,如网页发生变化就重新获取该网页,否则根据该网页中的链接继续去访问。网络机器人访问页面的过程就是对互联网上信息遍历的过程。在大多数情况下,爬行器不可能下载网络中所有网页,只能下载其中一部分的网页。网络机器人只能下载那些比较“重要”的网页。
2.2.2 索引器
网络机器人把遍历得到的页面存放在一个临时数据库中,这样就不会出现用SQL直接查询信息速度难以忍受的情况。为了提高检索效率,需要建立按照倒排文件的格式存放的索引。这样当用户输入搜索条件后搜索程序便会将通过索引数据库进行检索,然后把符合查询要求的数据库按照一定的方式进行分级排列并返回给用户。
3 个性化搜索引擎算法设计
3.1 设计概述
本文的个性化算法主要基于这种考虑:现在有很多通用搜索引擎如 Google,Yahoo,百度等给大家带来了很大的方便,但是对于每个特定用户而言并不是十分理想,不能根据特定用户的爱好提供合适的信息,而是任何用户,任何时间只要输入相同的关键字就一定得到相同的搜索结果,这并不是用户所期待的。用户理想的搜索引擎应该能够判断出各个特定用户,为不同用户提供与用户兴趣相关的搜索信息。此时就需要搜索引擎能把用户的个人信息考虑进去。
3.2 个性化搜索引擎的原型系统
笔者提出了一种个性化搜索引擎的原型系统,这种个性化搜索引擎是在传统搜索引擎的基础上,加入用户Agent模块、用户反馈处理模块、用户特征数据库,在提交请求阶段,用户agent就把用户的请求处理成个性化请求,从而使得返回结果符合用户个性化特征,用户能够搜索到自己最想要的信息,该个性化搜索引擎把无关网页限制到最低程度。
3.2.1 用户特征文件数据库
其中的主要操作有:用户特征文件的收集、建立、更新等;在这篇论文中,我们对用户特征文件的提取,提出了基于综合索引的文件提取方法,这种方法对于建立与用户兴趣相关的特征文件极其有效。对于用户特征文件的更新,我们提出用菲泊拉契数列方式来进行及时调整用户兴趣。处理用户特征文件数据算法可分为如下五个部分:
(1)收集整理用户信息:输入用户访问日志表,输出用户访问统计表。
(2)找分组键值:输入用户访问统计表,输出兴趣衰减。
(3)用户分组:输入分组信息表中的键,用户访问统计表,输出填入分组情况的用户访问统计表。
(4)寻找组内关联:输入分好组的用户访问统计表,输出包含组内关联信息的分组信息表。
(5)兴趣衰减:输入用户访问统计表,输出权重重新调整了的用户访问统计表。
3.2.2 用户反馈模块
这是程序自动提取用户兴趣的重要操作模块,如果用户不手动输入自己的兴趣,那么我们就必须通过用户反馈模块来分析用户已经访问过的网页,对文档进行分类,并对用户使用过的模糊概念进行分析,从而得到用户独有的搜索词习惯和用户感兴趣的主题。在这个用户反馈模块中,我们提出用感觉索引来提取用户特征文件。这是提取特征文件的一种新方法。
3.2.3 用户agent模块
本模块具体算法包括:
(1)处理用户的搜索请求使之变成个性化请求:
(2)产生出符合用户兴趣特征网站。
其具体操作步骤为:
第一步:从传统搜索中得到搜索结果;
第二步:建立用户兴趣与结果文档集矩阵;
第三步:基于兴趣与文档矩阵,得出某一特定文档的兴趣向量值;
第四步:计算某一文档与用户兴趣的相似性;
第五步:按照用户兴趣特征对网站排序,并把结果提交给用户。
3.2.4 个性化搜索引擎系统框架
本文使用基于个人兴趣特征文件和反馈技术的页面权重排序算法,从而获得理想的具有用户兴趣特征的网页。这是本论文对个性化搜索引擎系统原型的重大突破。以往的网页重要性排序算法只使用链接结构和入度来计算,但实际上网页重要性(PageRank)不光要考虑其超链接数目,还要考虑资料本身的内容。假如把用户的特征文件以及用户的反馈信息考虑进去的话,网页重要性才是主观的,因为不同用户对某网页的爱好不同,则该网页对该用户来说其重要性也就不同。因此我们提出了一种个性化的计算网页重要性(PageRank)的计算方法,通过用户agent对搜索结果进一步排序,返回个性化搜索引擎,最终达到搜索引擎的个性化。
3.3 提取用户兴趣爱好方法
提取用户特征数据库中的用户特征数据有两种方法,最直接的方式是:搜索引擎能够接受用户直接输入的个人特征资料,并将这些特征资料保存在客户端。这样作的结果是搜索引擎能够返回给用户更加满意的网页,可以把用户不感兴趣的信息控制到最小范围。另一种方法就是:通过用户反馈模块来自主获取用户特征资料,我们利用用户信息反馈模块来收集用户搜索的历史,同时由具有这个模块的搜索引擎来跟踪并记录用户的搜索历史,以便对用户的特征进行自主学习。
3.4 相关反馈技术
用户反馈处理模块是来自主生成用户特征文件,在用户反馈处理模块中,必须使用的一项技术是相关反馈技术,相关反馈技术是一项常用的传统的信息检索技术。反馈的两项基本技术是:查询词扩展,查询词重要性更新。在用户进行搜索时,搜索引擎会给出几种可能的搜索词,从这些搜索词中用户便有可能找到自己真正想要查询的表达方式。特别是那些搜索技能比较差或者对某领域不太熟悉的用户来说,反馈技术可以帮他们找到自己无法描绘的需求。再者相同单词可能有多个不同意义,简单的查询词难以表达出作者的真正意愿,而通过相关反馈技术用户可以轻而易举的表达自己的需求。也就是说相关反馈中包含了作者的兴趣爱好,以及对某些网页的偏爱性,所以说相关反馈技术对提高个性化页面的重要性(PageRank)起到至关重要的作用。
3.5 个性化设计具体方法
3.5.1 传统的页面重要性排序(PageRank)计算方法
传统的页面排序思想来源于下面这样的一个假设[1]:它把超链接看成是对链接页面的赞许。当某个页面l通过超链接指向页面2时,它隐含了这样的意义:页面l与页面2是主题相关的,同样页面2对于页面1来说也很重要且值得关注。其页面s的重要性计算公式为:
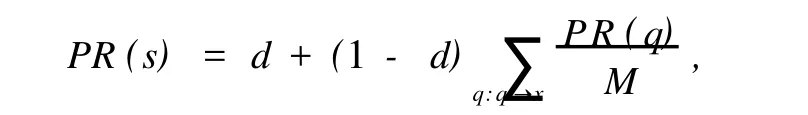
其中在公式中d是跳转因子,是从一个主题切换到另外一个主题的概率,q是指所有链接到页面上的页面。M指页面q的链接总数。假如忽略跳转因子d,那么页面s的权重只跟它的链入页面的平均权重有软席。因为这种排序的计算方法在一定程度上确实能标识某个网页的重要性,所以这个计算公式是我们改进算法的思想来源。
3.5.2 用户特征文件的计算方法
用户特征文件指从用户历史记录中筛选出来的与其他用户相区别的关键词等,为了消除歧义存储这些兴趣资料,以便返回用户所需要的有针对性的信息。网页P对应的兴趣值Rf计算公式如下:

上面公式原理见文献[2],随着用户兴趣变化的情况,我们用菲波拉契数列来调整用户兴趣值wi,①在用户访问统计中加上di项,执行di=di+l来表示没有访问过的天数增加一天。当有新的兴趣加入时,天数置为-1,在做完第一步后di=0,表示用户刚刚访问过。②用Fibo(di)表示菲波拉契数列的第di项,再用wi=wi-Fibo(di)。我们可先把wi置大点,再另设置一个临界值,当wi小于临界值时我们就删去用户的这个兴趣,当wi增加到某个临界值时我们可以加入这个兴趣,这样便可避免一开始兴趣值变成负数。
3.5.3 相关反馈的重要性值的计算
相关反馈中可能包含用户对返回的网页标记为好坏的网页信息,这种标记可以是显式的,也可以是隐式的。显式方式就是搜索引擎提供一个界面,让用户提交自己的意见。隐式方式则是通过对用户历史记录的分析,找到某词汇对于该用户而言好的页面,当下一次用户输入相关词汇时,就可以知道该词汇相对于此用户的自然语意了,从而减小搜索范围,返回结果更加具有个性化特点。这种反馈信息对进一步改进用户个性化有很大的帮助。
3.5.4 基于个人兴趣和反馈技术的页面重要性排序(PageRank)算法
网页的重要性值应该来源于三个方面[3]:页面权重、用户的兴趣爱好值和相关反馈值。网页重要性值R的计算公式如下:
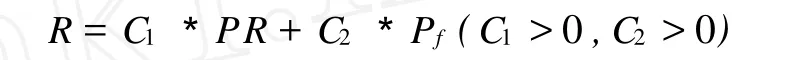
其中C1,C2为重要性系数,并且是大于零的实数。如果用户对得到的结果不满意,用户可以对搜索的结果标记好或坏,通过这些反馈信息来进一步计算得到用户反馈值Pb。这样网页的最终权重便就可以调整为:R=C3*R+C4*Pb(C3> 0,C4>0),从上面公式我们可以看出,计算网页重要性综合考虑了用户的兴趣以及对结果的反馈情况,这样我们至少可以得到当前的搜索引擎能够搜到的结果。当搜索引擎获得越来越多的特定用户的兴趣资料以及反馈之后,它的个性化程度将会越来越高,而且搜索结果越来越好。从以上理论证明可以看出我们的用户agent模块确实能够处理出符合用户兴趣的网站。从而使搜索引擎具有个性化特征,这正是用户期待的结果。
[1] 刘悦,杨志峰.利用连接分析技术提高搜索引擎查找质量的研究[J].微电子学与计算机,2002,(5).
[2] Glen Jeh and Jennifer Widom.Sim Rank.A measure of structural-context similarity.In Proceedings of the Eighth ACM SIGKDD intemational Conference on Know ledge Discovery and Data M ining,2002,7.
[3] 王小玲,胡平.基于个人兴趣和反馈技术的PageRank算法研究.合肥工业大学学报(自科版),2006,29(3):313-315.
Personalized Search Engine Algorithm
(Hebei Electronic&Information Technology Academ y,Shijiazhuang Hebei050011,China)
HU Li-na
Search engine is an indispensable tool of using resourceson the internet for users,w hile the p recision rate is very low at p resent.For different users,the query object expected w ill be different acco rding to the same query term s.Then the search engine p recision means personalized search engine algorithm.The key to research personalized search engine is the confirming of users’interest and interest in the value of the document.When the abstract personal interests is converted to the digital matrix,w e can get the real customer demand and the relevance betw een documents and users interests,and then filter the useless documents and so rt them accurately.
Search Engine;Net spider;Page Rank;Perceiving Query;Feedback
TP311
:A
1001-9383(2010)03-0027-04
2010-08-01
胡立娜(1980-),女,河北唐山人,助理工程师,主要研究方向:软件工程。
猜你喜欢
保健医苑(2022年1期)2022-08-30
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
电子测试(2015年18期)2016-01-14
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
科学导报·学术论坛(2013年5期)2013-06-26
网络安全技术与应用(2011年3期)2011-03-14
赤峰学院学报·自然科学版(2010年11期)2010-09-21

- 河北省科学院学报的其它文章
- 新形SrCO3晶体的制备
- 项目网络评审系统设计与应用