
道路交通事故宏观预测模型*
2010-12-01 03:58:16秦利燕邵春福
武汉理工大学学报(交通科学与工程版) 2010年1期
秦利燕 邵春福 赵 亮
(山东交通学院交通与物流工程系1) 济南 250023) (北京交通大学运输学院2) 北京 100044)
0 引 言
近年来,中国的道路交通安全形势十分严峻,连续多年来交通事故死亡人数在10万人左右[1-2],影响了经济发展和社会稳定,保障人们的出行安全和货物运输安全,变得十分必要和迫在眉睫.因此对中国的交通安全形势做出科学的预测,同时,为政府宏观改善政策及具体应对措施的出台提供依据十分必要.
目前国内外有多种方法应用于事故预测.Hong[3]等通过综合考虑道路类型和交通特性的影响,改进了原有的交通事故预测模型;裴玉龙[4]提出的交通事故死亡人数预测模型,由于网络收敛速度慢且预测结果的误差较大.本文在对中国交通领域相关数据的分析整理的基础上,用遗传算法作为优化算法来优化神经网络的权值和阈值,克服自身缺陷,较好地实现了事故死亡人数预测,使事故预测的方法更加完备.
1 道路交通安全评价指标及相关因素的确定
1.1 交通安全评价指标特性
在道路交通安全系统里面,交通安全水平面普遍采用事故次数、死亡人数、受伤人数和经济损失这四个统计指标来衡量.
对事故次数来说,大多数的道路交通事故仅涉及物损,不涉及人员伤亡的事故统计中被大量遗漏,不同国家、区域统计的遗漏的程度也不同;对于经济损失而言,由于各个国家和地区的货币体系的不同、事故处理人员的认知程度不同,统计主观因素很大,而缺乏可比性;受伤人数的统计也存在类似的问题,因此也缺乏可比性.
交通事故死亡是交通安全危害最大的一种结果,并且涉及人员死亡的道路交通事故历来受到高度重视,在统计中很少遗漏,所以它最能表征安全与不安全的特征.而且从各国、各区域的数据统计上来看,都对死亡情况作了详细记录,可比性也较强,因此应本文将死亡人数作为表征衡量交通安全程度的预测指标.
1.2 相关影响因素
道路交通安全不但与宏观道路交通背景直接相关,而且与社会环境的大背景相关.道路交通事故的发生具有很大的随机性,影响因素众多,本文选取人均GDP、机动车保有量、公路里程作为道路交通事故预测模型的核心的指标.相关因素的近年数据变化情况和主管部门对未来发展趋势的预测和规划情况见表1.
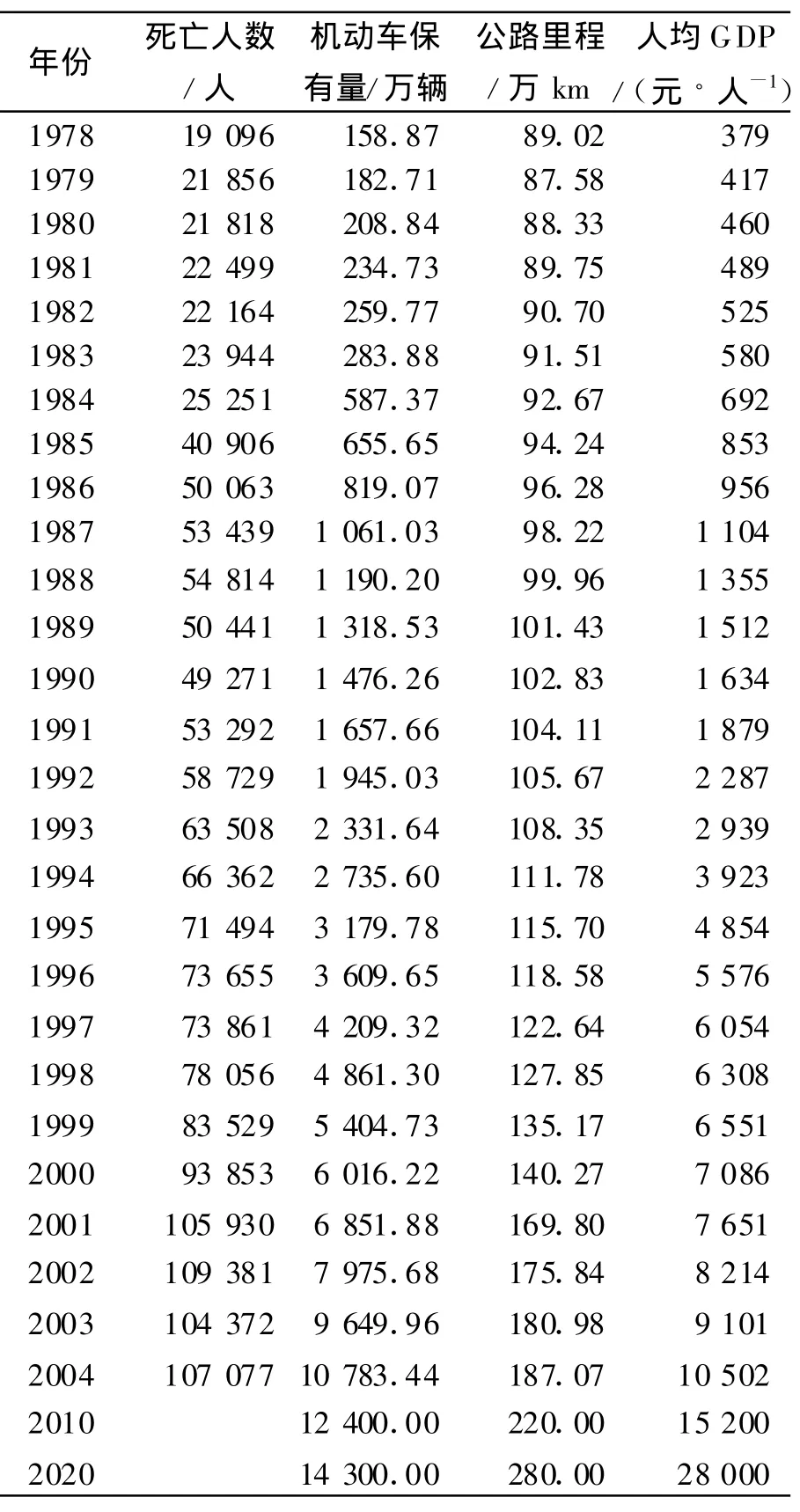
表1 中国历年道路交通各项指标统计
2 遗传优化神经网络预测模型
2.1 用遗传优化神经网络学习算法
本文引入遗传算法来优化神经网络的权值和阈值,从而建立了一种新的事故死亡人数预测方法.其基本思想是以GA优化BP网络的初始权值和阈值,再由BP算法按负梯度方向,修正网络的权值和阈值,进行网络训练.这种方法避免了BP网络易陷入局部极小的问题,实现优势互补,达到优化网络的目的[5-7].
1)编码 对网络中连接权值和阈值进行编码主要有两种方法:一是采用二进制编码,另一种采用实数制编码方案.本文采用二进制编码.
2)产生初始群体M 种群的大小对遗传算法影响很大,种群数目大,可增加种群中个体的多样性,容易找到最优解,但会延长收敛时间;种群数目小可加快算法的收敛,但容易陷入局部极小(即不成熟收敛).本文中取M=40.
3)计算适应度 构造适应度函数 f,对于极小值采用下式

式中:C为常数;
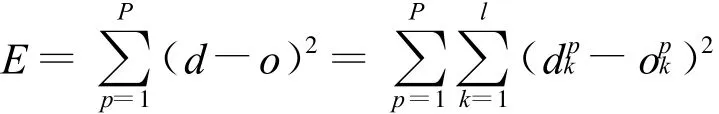
然后,根据适应度函数计算出各个体的适应值,按适应值大小将个体进行递减排列.
4)选择(复制)操作 选择适应度大的个体遗传到下一代,本文应用适应度比例法.即各个个体的选择概率与与其适应度成正比.如第i个个体的适应值为f i,则其被选中的概率为
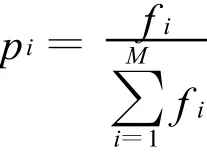
式中,M是群体规模.
5)交叉操作 从种群中按一定的交叉概率Pc随机选择2个权值个体,然后在个体字符串随机设定一个交叉点,对该点后2个个体部分结构进行交换,生成新个体.
6)变异操作 以一定的概率P m从群体中随机选取若干个体,对选中的个体,随机地确定基因座即变异点对这些基因座的等位基因进行变异,在即将1换为0,将0换为1,其概率很小.
7)重复步骤3)、4)、5)、6),使初始权值及阈值分布不断修正进化,取在整个操作中最优个体作为神经网络的初始权值,然后对BP网络进行训练,求得全局最优解.
GA优化神经网络的道路交通事故预测模型的学习过程框图如图1所示.

图1 基于GA的神经网络模型的事故宏观预测学习过程图
2.2 预测模型的训练
采用1978~2004年的中国道路交通事故死亡人数的27组预测样本(见表1),其中前21组作为训练样本,后6组作为检验样本.
GA优化神经网络模型确定输入层神经元为3个,即公路里程、机动车拥有量、人均GDP;隐层节点确定为5个,输出层为1个.在样本的训练过程中,取初始种群 M=40,交叉概率Pc为 0.65,变异率P m为0.005,终止进化代数K max为400,初始权值与阈值取值范围(-15,16),取神经网络的学习率η为0.7,误差要求E m in为0.01.
BP网络训练确定了3个输入层单元,分别是公路里程、机动车拥有量、人均GDP共3项因素,最佳隐层单元采用试算法确定为26,输出层单元为预测未来年限的道路交通事故死亡人数.在样本的训练过程中,取神经网络的学习率η为0.7,初始权值取值范围(-1.0,1.0),误差要求E min为0.01.
2.3 预测结果及分析
网络训练好后,同时将遗传神经网络和传统的单独的BP算法进行比较,结果见表2.将遗传神经网络和BP网络的相对误差取绝对值,计算平均误差分别为5.40%和9.31%.
用训练完毕且已掌握了“知识信息”的网络进行预测时,只需将待测时段的3个影响因素资料输入网络,通过正向计算输出各单元输出值即刻可得到2010年和2020年的预测结果[8].
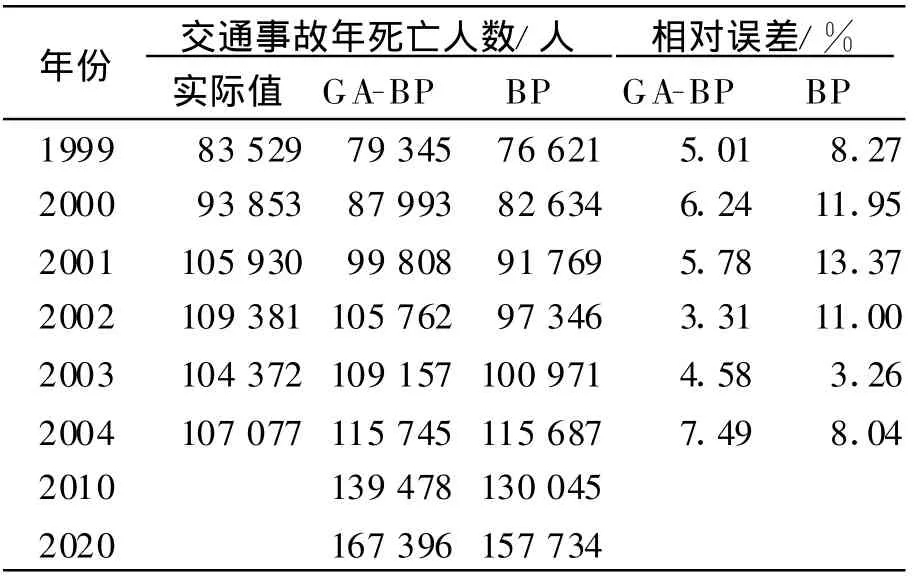
表2 道路交通事故死亡人数预测结果
2个模型的对比计算来看,用遗传算法学习神经网络权值,计算精度远远高于传编统的单独的BP算法,收到了比较好的预测效果,由于遗传算法适合于处理规模较大的并行问题,收敛速度加快,网络性能大大改善.
3 结 论
1)道路交通安全状况的影响因素主要有机动车保有量、公路里程、人均GDP等.
2)借鉴遗传算法全局寻优性和神经网络局部寻优的特点,建立了基于遗传算法的神经网络道路交通事故宏观预测模型.通过对两个模型的计算和对比研究发现,基于遗传算法的神经网络事故预测模型计算精度高,网络泛化能力强.
[1]公安部交通管理局.中华人民共和国道路交通事故统计资料汇编(1991~2006)[G].北京:公安部交通管理,2007.
[2]付 锐,刘浩学.关于中国道路交通安全政策框架的探讨[J].交通运输工程学报,2001(1):122-126.
[3]Hong D,Lee Y,K im J,et al.Development of traffic accident p rediction models by traffic and road characteristics in urban areas[C]//Proceedding of the Eatern A sia Society for Transportation Studies,Chiyoda-ku,Tokyo,2005:2046-2061.
[4]裴玉龙.道路交通事故成因分析及预防对策研究[D].南京:东南大学交通运输工程系,2002.
[5]戴 葵.神经网络实现技术[M].长沙:国防科技大学出版社,1998.
[6]吕 俊,张兴华.几种快速BP算法的比较研究[J].现代电子技术,2003,24(5):78-82.
[7]刘勇健.基于智能算法的地下水位动态预测模型的建立与应用[J].水文地质工程地质,2004(3):55-58.
[8]秦利燕.道路交通事故预测预防理论与方法研究[D].北京:北京交通大学交通运输学院,2006.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
公民与法治(2020年17期)2020-10-27 02:27:52
小雪花·成长指南(2020年2期)2020-10-12 02:39:11
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
自动化学报(2017年7期)2017-04-18 13:41:02
统计与决策(2017年2期)2017-03-20 15:25:24
灾害医学与救援(电子版)(2016年4期)2016-03-11 20:18:15
