
优化的互信息特征选择方法
2010-11-26 08:38:36胡强
湖南师范大学自然科学学报 2010年3期
胡 强
(川渝中烟工业公司长城雪茄烟厂工程部,中国 什邡 618400)
文本自动分类是文本挖掘中一个核心研究内容,它根据文档内容及其属性给文档自动分配一个或多个类别[1].目前,在绝大多数的文本分类模型中常用空间向量模型来对文档进行表示[2].在这个表示模型中,文档通常被看作是特征词的无序序列,因而特征向量空间可能由出现在文档中的全部词条构成,这就使得文本特征空间具有较大的维数,从而大大限制了分类算法的选择、降低了分类算法的性能.因此,在实行文本自动分类之前必须对文本向量空间进行降维以减少运算开销、提高分类的效率和精度[3].
特征选择是一种比较有效的降维方法,它从原始特征集中选择出一部分有代表性的、对分类类别贡献比较大的词条组成特征子集.在诸多现存特征选择方法中,互信息是一种比较有效的方法[4].论文首先对互信息进行分析,总结其不足,然后定义了一个新型文档频并把它引入互信息以期对互信息进行优化.实验结果表明,在同种条件下,优化的互信息方法能够提高分类整体性能.
1 信息(Mutual Information, MI)分析
互信息是统计学中一种用于表征两个变量相关性的方法,常被用于文本特征相关的统计模型及其相关应用标准[4-7].对于给定的特征f和c类文档,它们之间的互信息可由下式来表示[8]:
(1)
式中p(f)表示特征f在全部文档中出现的概率,p(f|c)表示特征f在c类文档中出现的概率.互信息最大的不足就是对临界特征的概率比较敏感.分析公式(1)可知:当两个特征的条件概率p(f|c)值相等时,p(f)较小的词 (也即稀有词)比p(f)大的词 (也即普通词)的互信息分值要高,因此,对于概率相差太大的两特征来说,它们的互信息值不具有可比性.互信息另一个很大的缺点在于它没有考虑特征在文本中发生的频度,因而造成了互信息特征选择方法经常倾向于选择稀有特征.在一些文本特征词选择算法的研究中发现[6-7],如果仅仅使用互信息进行特征选择,它的精度极低,其主要原因在于它滤掉了很多高频的有用特征.
2 新型文档频
论文所提的新型文档频就是把文档频方法和词频方法[5-7]结合起来,以便既考虑特征的文档频又考虑特征的词频.
定义1新型文档频.特征f关于类别C的新型文档频是指在类别C的文本集中出现特征f次数达到事先给定的阈值的文档数,可用New-DFmin(f,C) ,其中min为事先给定的一个阈值,表示特征词在文档中出现的最少次数.如果用该新型文档频New-DFmin(f,C)计算特征评估函数中的概率,则评估函数中用到的概率公式计算方法为:
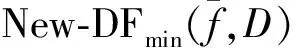
3 优化的互信息方法
通过第1节对互信息的分析可知,它仅考虑特征发生的文档频而没有考虑它发生的词频,从而导致互信息评估函数经常倾向于选择稀有词.通常情况下,稀有词也即出现频率较低的词通常对分类贡献较小,为了避免对分类系统带来干扰,需要对这类词加以过滤.为此,本文把第2节所提的文档频引入互信息,以期对互信息的缺点进行弥补. 此时特征f与c类文档之间优化的互信息Optimized-MI(f,c)的定义如下:
(2)
其中p(f)min和p(f|c)min为上述第二节所定义.从公式(2)可以看出,引入新型文档频后可以在一定程度上弥补传统互信息倾向于选择词频较低的特征的缺陷.
4 优化的互信息方法实验验证
4.1 实验数据
实验选用语料库Reuters-21578作为实验数据.目前,这个语料库已经被广泛应用于文本分类实验之中,并成为了一种标准的分类语料库,已有大量基于该语料库的实验结果公开发表,其下载网址为:http://kdd.ics.uci.edu/databases/reuters21578/reuters21578.htm.Reuters-21578语料库中共包含了22个SGML格式的数据文件夹,其中从reut2-000.sgm到reut2-020.sgm这21个文件夹中,每个文件夹由1 000篇文章组成,而reut2-021.sgm中则只包含578篇文章,因此整个语料库总共有21 578篇文章,这些文章都来源于路透社1987年的新闻.该语料库共有135个类别,一篇文章最多时同时属于14个类别,平均一篇文章属于1.24个类别.该语料库类别文档数分布极其不均匀,其中一个最大的类别由2 877篇正例训练文档组成, 有75个类别的正例训练文档数不足10篇,甚至还有一些类别根本就没有正例训练文档.本实验保留了90个类别,这些类别在训练集和测试集中都至少有一篇正例文档.实验中使用“ModApte”划分方法根据LEWISSPLIT、TOPIS、CGIPLIT等属性对这90个类别的文档进行不同的划分.经过划分和删去分类信息缺失的文档后,共得到训练文档8 237篇、测试文档3 186篇.本实验仅考虑〈TITLE〉和〈BODY〉之间的内容,使用N-gram方法抽取词干并删去停词后获得20 993个不同的词.
4.2 实验环境及参数设置
实验设备为一台普通计算机.实验中,使用的计算工具为MATLAB 7.0,采用的分类软件工具是Weka,这是纽西兰的Waikato大学开发的与数据挖掘相关的一系列数据预处理、分类、回归分析、聚类、关联规则、可视化等工具,它对学习研究数据挖掘和机器有很大益处,其下载网址为:http://www.cs.waikato.ac.nz/ml/weka/.经反复试验,本文算法中最小词频阈值设置如下:min=4.
4.3 实验所用分类器及其评价标准
实验主要用于比较Optimized-MI与MI对后续文本分类性能的影响,因此本实验在这两特征选择方法后采用相同的分类器来比较这两种特征选择方法.KNN分类器因简单、易理解而被广泛使用,本实验就选择该分类器来比较Optimized-MI与MI(实验中,KNN分类器中向量间的夹角余弦值作为文本间的距离,K设置为10).为了检测这两个方法在特征个数变化情况下的KNN分类性能,选取了不同的特征个数,将微平均F1值和宏平均F1值[8]的变化情况作了比较.
4.4 实验结果及其分析
在Reuter-21578语料库上,为了检测KNN分类器在不同的特征数目下的性能,分别对所选择的90个类别的微平均F1值和宏平均F1值进行了计算,具体结果如表1所示.
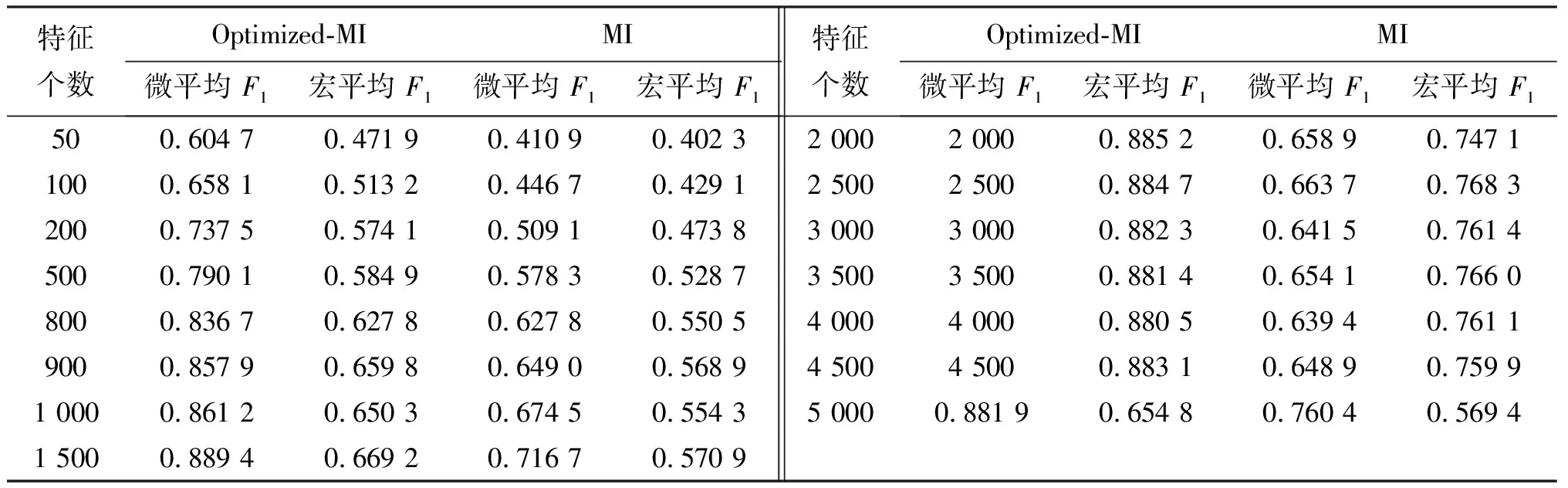
表1 特征维数变化下的微平均F1值和宏平均F1值
在特征数目变化的情况下,考察分类器的性能变化情况,可以很好地反映一个分类器对数据样本变化的敏感程度.从表1中可以看出,随着特征个数的增加,分类器的宏平均F1值随着特征个数的增加而升高,但是波动相对微平均较大,这是因为宏平均主要是受到小类别精度的影响;分类器的微平均F1值也随着特征个数的增加而升高,并将到达一个相对稳定的水平.从表1还可以看出,在同样的条件下,在宏平均F1值和微平均F1值方面,Optimized-MI都要优于MI.在50到1 500这个特征个数范围内,Optimized-MI的宏平均F1值比MI的宏平均F1值平均提高了近9%, Optimized-MI的微平均F1值比MI的微平均F1值平均提高了近20%.Optimized-MI的宏平均F1值和微平均F1值在特征个数为1 500的时候达到最高,分别为0.669 2和0.889 4,以后分别基本维持在0.66 0和0.88左右,这说明Optimized-MI选出的特征集中前1 500个特征是比较优的.MI的宏平均F1值和微平均F1值在特征个数为2 500的时候达到最高,分别为0.768 3和0.579 7,以后分别基本维持在0.57和0.76左右,这说明MI选出的特征集中前2 500个特征是比较优的.对比可知在MI选择的前2 500个特征中包含了许多对分类贡献较小甚至对分类贡献起副作用的低频特征词;在Optimized-MI中由于引进了一个新的文档频,从而能够把那些低频词过滤掉,进而提高了后续分类器的宏平均F1值和微平均F1值,这说明Optimized-MI是比较有效的.
5 结束语
论文分析了传统互信息方法,针对其倾向于选择对分类贡献较小的低频词的缺点,引入一个新型文档频,以此对传统互信息进行优化.通过在国际通用语料库—Reuter-21578语料库上的对比实验表明,优化的互信息能够克服传统互信息的不足,从而获得较为优秀的特征集.
参考文献:
[1] YAN X. A formal study of feature selection in text categorization [J]. American Journal of Communication and Computer, 2009, 6(4):32-41.
[2] ZHU H D,ZHAO X H, ZHONG Y. Feature selection method combined optimized document frequency with improved RBF NetWork[C]//Proc. of 5thInternational Cnference,ADMA 2009,Beijing:China,August 2009,796-803.
[3] 朱颢东,钟 勇. 基于优化的文档频和粗糙集的特征选择方法[J]. 湖南师范大学自然科学学报,2009,32(3):27-31.
[4] DESTRERO A, MOSCI S, MOL C D. Feature selection for high dimensional data [J]. Computational management science, 2009,6(1):25-40.
[5] 毛 勇,周晓波,夏 铮.特征选择算法研究综述[J]. 模式识别与人工智能,2007,20(2):211-218.
[6] CUI Z F, XU B W, ZHANG W F. A new approach of feature selection for text categorization [J].Wuhan University Journal of Natural Sciences (English version), 2006, 11(5):1 335-1 339.
[7] 寇苏玲,蔡庆生. 中文文本分类中的特征选择研究[J].计算机仿真,2007,24(3):289-291.
[8] LIU H W, SUN J G, LIU L. Feature selection with dynamic mutual information [J]. Pattern Recognition,2009,42(7):1 330-1 339.
猜你喜欢
电子制作(2017年23期)2017-02-02 07:17:06
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
新校长(2016年8期)2016-01-10 06:43:59
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
