
基于主题网络爬虫的网络学习资源收集平台的设计
2010-10-18 07:53:20郑志高刘庆圣陈立彬
中国教育信息化 2010年1期
郑志高,刘庆圣,陈立彬
(1.陕西师范大学 新闻传播学院知识媒体研究所,陕西 西安710062;2.西安陆军学院 军训教研室,陕西 西安 710108)
基于主题网络爬虫的网络学习资源收集平台的设计
郑志高1,刘庆圣1,陈立彬2
(1.陕西师范大学 新闻传播学院知识媒体研究所,陕西 西安710062;2.西安陆军学院 军训教研室,陕西 西安 710108)
收集现存于网络中的信息,对其进行加工、处理使其成为可用的学习资源是网络学习资源建设中一项重要工作,主题网络爬虫为在网络学习资源建设过程实现信息的自动收集提供了可能,本文以此为基础设计了一个能满足资源建设需要的网络学习资源收集平台并对设计过程中的关键问题进行了分析。
主题网络爬虫 网络学习资源 网络学习平台设计
收集现存于网络中的各类信息,对其进行加工、处理使其成为可用的学习资源是网络学习资源建设中一项重要工作,在其过程中资源建设者面临两大难题:
(1)如何高效、快速地从网络海量信息中筛选出资源建设所需的各种信息;
(2)如何使加工完成的资源更新速度跟上网络信息快速更新的速度。
这两个问题的解决不能靠人工操作完成,较好的解决方案是使用功能程序辅助资源建设者进行信息收集和检测,目前被广泛使用于网络搜索引擎的网络爬虫能较好地解决上述两个问题,本文就网络爬虫在网络学习资源建设中的应用方法进行研究。
一、主题网络爬虫及其工作原理
网络爬虫是一个网页自动提取程序,它从一个或若干初始网页开始,获取包含在其中的URL(Uniform Resourcl Locator,统一资源定位符)进行网页抓取,在抓取网页过程中,从被抓取的网页中抽取新的URL放入抓取队列,直到满足系统设定的停止条件终止抓取过程。主题网络爬虫是根据一定网页分析算法过滤与主题无关的链接,只保留主题相关的链接进行网页抓取。[1]主题网络爬虫工作原理如图1所示。[2]
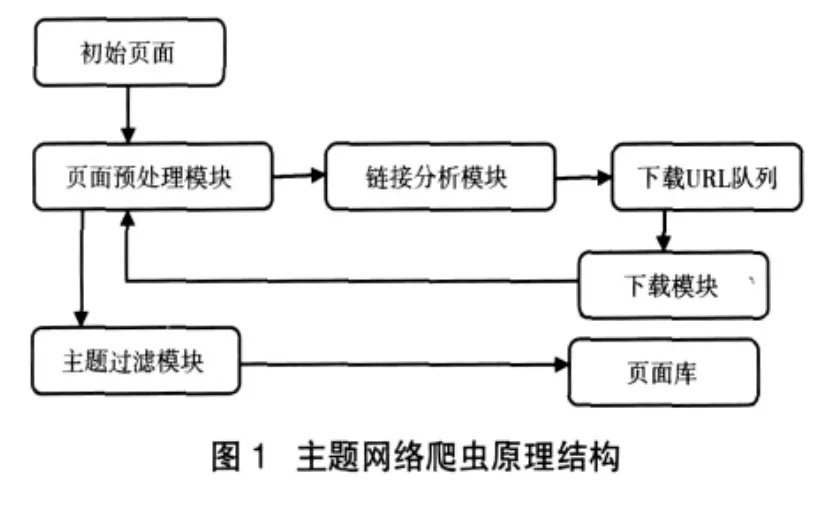
主题网络爬虫各个组成部分功能如下:
(1)初始页面:包含超链接的一个或若干个网页,主题网络爬虫从中获取要抓取的起始页面。
(2)页面预处理模块:用于页面的分析和去除页面中的无用信息(如广告链接等)。
(3)链接分析模块:用于分析页面中提取的超链接,并将有效链接放入下载URL队列等待抓取。
(4)下载模块:从下载队列中获取URL进行网页抓取。
(5)主题过滤模块:对抓取的页面按照主题进行过滤,去除跟主题无关的页面,将满足条件的页面放入页面库。
(6)页面库:用于存放被抓取满足条件的页面。
根据其工作原理,主题网络爬虫能够从一个或若干个初始页面开始自动收集分析满足特定要求的页面并对其进行保存,完成信息的收集。因而在网络学习资源建设过程中,可以以此为基础设计一个自动收集信息的平台有效地解决前文所述网络学习资源建设过程中面对的两个难题。
二、平台的结构及运行流程
1.将主题网络爬虫直接应用网络学习资源的收集会产生的问题
(1)主题网络爬虫工作时需要从一个或若干个起始页面获取URL启动抓取过程,但它本身不能产生,需要资源建设者提供,而且初始页面的内容会直接影响主题网络爬虫抓取的信息的覆盖率和准确性。
(2)主题网络爬虫只能够按照要求进行页面的获取和保存,不能分析其内容的科学性和准确性,而科学准确是学习资源对信息最重要的要求。
(3)主题网络爬虫不提供对抓取、保存的信息进行处理的功能,而信息需要进行加工处理才能成为可用的学习资源。
因此以主题网络爬虫为基础构建网络学习资源收集平台必须解决这三个问题,综合网络主题网络爬虫的工作原理和网络学习资源建设内在的要求,基于主题网络爬虫的网络学习资源收集平台结构如图2所示。
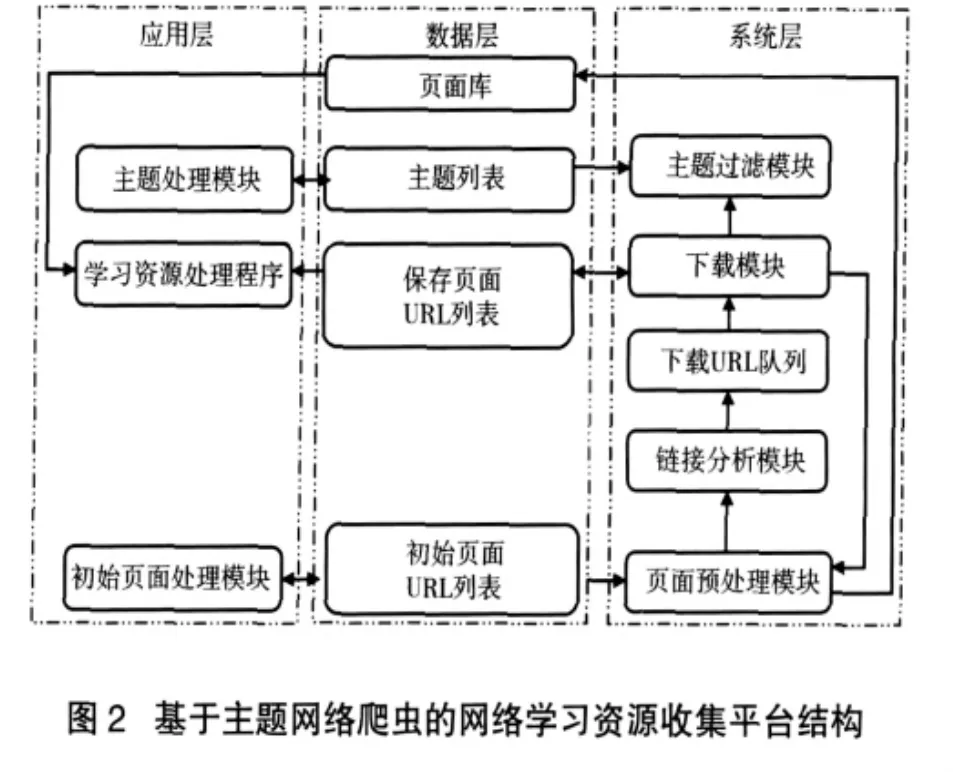
2.整个平台由数据层、系统层和应用层构成
数据层用于保存平台运行过程中需要以及产生的数据,包括:
(1)初始页面列表:用于保存初始页面的URL,初始页面既可以是已存在于网络中的页面,也可以是根据资源建设需要由建设者整理编辑完成的页面。
(2)保存页面URL列表:用于保存页面库中页面的URL。该数据可用于注明已下载的页面的出处以及减少平台在资源下载过程中对相同位置上的同一资源进行重复下载。
(3)主题列表:用于保存在信息筛选时使用的主题信息,通过修改和设置主题列表可以使平台收集不同主题的信息,提高平台的通用性。
(4)页面库:用于保存由平台下载且经过主题筛选的页面。
系统层核心是一个主题网络爬虫,根据网络学习资源建设需要进行了优化和功能扩展。体现在以下两方面:
第一,主题过滤模块每次工作时首先从主题列表中读取主题,以确定本次工作的主题信息。
第二,下载模块进行页面下载时,首先查询下载页面的URL是否存在于保存页面URL列表中,如果存在则跳过该页面的下载,进行下一个页面的下载;完成页面下载后将其URL加入保存页面URL列表中。
应用层用于平台运行环境设置和资源的处理,包括:
初始页面设置模块,用于初始页面的编辑和初始页面URL列表的管理;主题处理模块,用于主题列表的管理,包括主题的添加、删除、修改等;学习资源处理模块,用于对平台自动收集信息进行处理,使其成为满足需求的学习资源。不同类型的学习资源建设对信息处理的要求会有所差别,如有些网络学习资源建设只要求提供资源清单,而有些需要对相关信息进行重组处理,该模块要根据资源建设要求进行设计,也可以直接使用现有的信息处理软件。
3.平台运行流程
(1)用户根据资源建设需要确定主题信息,使用主题处理模块将有关信息加入主题列表或者对主题列表中的有关内容进行编辑修改。
(2)用户收集网络中与资源相关、代表性的网页作为起始页,这些页面一般要包含丰富的超链接,利用初始页面处理模块将其URL填入初始页面列表中或者对列表中的有关内容进行修改;资源建设者也可根据资源建设需要编辑初始页面并将相关信息填入初始页面列表。
(3)运行平台系统层完成信息的自动收集。
(4)运行资源处理程序完成资源的处理。
平台运行包含四个环节,这四个环节相互独立,在资源建设和维护过程中,资源建设者可以从任意一个环节开始信息的收集和处理操作;通过反复运行平台,可以实现跟踪相关网站中的信息更新,从而使处理完成的资源跟上网络信息的更新。
三、平台设计中的关键问题
1.如何提高网络学习资源收集平台信息搜索覆盖率
这一问题的解决取决于两个因素,一是初始页面的选择,选择内容与主题密切相关且包含丰富超链接的页面作为初始页面(如与资源建设内容相关的主题网站)和适当增加初始页面的数目可以提高平台搜索的范围,从而提高收集资源的覆盖率。二是平台核心构件主题网络爬虫采用的搜索策略。作为主题网络爬虫的核心技术国内外有大量与之相关的研究,文献[3][4][5][6]对目前国内外比较成熟的搜索策略进行了综述,以主题网路爬虫设计网络学习资源收集平台,可根据资源建设需要选择合适的搜索策略。
2.如何提高下载信息的有效性
下载信息对资源建设的有效性取决于主题网络爬虫采用的主题搜索算法。高效的主题搜索算法有助于平台从下载的页面包含的超链接中筛选出与主题密切相关的URL进行页面下载,从而提高下载信息的准确率。另外与主题内容密切相关的页面作为初始页在一定程度上也能提高下载信息的有效性。
3.完成处理的资源是否能跟踪网络信息的更新
网络信息的更新包括两种情况:一是新信息的添加;二是原有信息的修改。文中设计的平台可以在一定程度上跟踪其所能覆盖网站添加的信息,但不能够跟踪网站修改的信息。如果要跟踪相关网站修改的信息需在平台中应用网络爬虫的资源更新策略以及相关的算法。
4.页面库的组织形式
网络爬虫对下载的页面通常采用两种形式进行存储:纯文件和数据库。纯文件存储是用统一的文件格式对下载的页面进行保存,这种方式结构统一,比较容易实现用现有的信息处理程序对其进行处理,但存在不能适应数据的动态变化、如果文件内容缺失会导致程序无法正常读取等诸多缺点。数据库存储方式是将相关数据以记录形式存入库中,这种存储方式比较容易实现对平台下载的大量数据进行高效管理和维护,而且支持快速查询,但需要数据库系统环境的支持,如果用现有的信息处理程序对其进行处理可能会产生程序无法从数据库中提取数据的障碍。在平台设计过程中可以综合考虑资源建设需要和信息处理要求选择合适的数据存储方式。
[1]刘金红,陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007(10):26-29.
[2]戚欣.基于本体的主题网络爬虫设计[J].武汉理工大学学报,2009(2):138-141.
[3]陈方,谭爱平.主题爬虫技术研究综述[J].湖南工业职业技术学院学报,2008(10):13-16.
[4]刘汉兴,刘财兴.主题爬虫的搜索策略研究[J].计算机工程与设计,2008(6):3160-3162.
[5]杨贞.基于本体的主题爬虫的设计与实现[D].中国优秀硕士学位论文全文数据库,2008.
[6]周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005(9):1966-1968.
(编辑:杨馥红)
G250.73
B
1673-8454(2010)01-0036-03
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
房地产导刊(2022年10期)2022-10-18 08:03:52
保健医苑(2022年1期)2022-08-30 08:39:14
现代信息科技(2021年21期)2021-05-07 02:54:12
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
华东师范大学学报(自然科学版)(2014年3期)2014-03-11 16:18:15
电脑爱好者(2011年11期)2011-06-22 08:20:18
