
基于Nutch的校园网信息检索系统的研究与实现*
2010-10-18 08:10:42宋光慧郭建康
中国教育信息化 2010年15期
宋光慧,聂 琰,郭建康
(1.浙江大学宁波理工学院 信息与教育技术中心,浙江 宁波315100;
2.宁波大学科技学院理工学院计算机系,浙江宁波 315212)
基于Nutch的校园网信息检索系统的研究与实现*
宋光慧1,聂 琰2,郭建康1
(1.浙江大学宁波理工学院 信息与教育技术中心,浙江 宁波315100;
2.宁波大学科技学院理工学院计算机系,浙江宁波 315212)
本文通过分析校园网内信息资源的特点,在Nutch搜索引擎的基础上,构建了基于校园网各Web网站站内检索和统一检索平台两层体系结构的校园网信息检索系统,有效地提高了检索效果。
Nutch;信息检索;搜索引擎;索引优化;汉语分词;排序算法
目前校园网信息检索主要采用两种方式。一种方式是Web网站构筑站内搜索功能,采用数据库查询的方式进行。通常是通过匹配标题、作者、摘要等字段的关键字信息来实现信息检索,由于受到数据库性能、检索效率等因素的影响不能实现基于匹配正文内容的检索,从而导致搜索效果下降。该方式也无法实现校园网信息资源的整合和共享。另一种方式是将基于互联网的搜索引擎技术应用于校园网,构建校园网搜索引擎,但校园网在应用环境、网站构建、链接结构等方面与互联网有所不同,主要表现为各网站独立性较强,网页间链接稀疏;检索目标与内容相关度、时间的关联性较强,而与网页被链接的数量关联性较弱;文档关键字重复度高,周期性出现。因此采用互联网搜索引擎基于网页链接分析技术的页面评分与排序算法往往不能达到令用户满意的检索效果。针对上述问题,本系统采用基于Nutch的开源搜索引擎技术,构建校园网信息检索系统,从而提高检索的广度、速度和精度。
一、系统体系结构
Nutch是一个开源的、Java实现的Web搜索引擎,提供了构建搜索引擎所需的基本工具模块,包括网络爬虫、文本分析、分词工具、建立索引、搜索功能和结果过滤等,具有透明性高、易于理解和扩展性好等特点。本系统以MyEclipse8.0作为开发平台,在Nutch搜索引擎的基础上对其分词模块、索引模块、搜索和排序模块进行了二次开发,以适应校园网的具体应用环境。
校园网信息检索系统体系结构分为两层。下层面向各Web网站,基于Nutch构建站内文档搜索引擎,建立各自网站的文档索引并提供搜索功能,替代基于数据库的检索方式,从而提高检索效果和效率;上层为面向校园网范围的信息检索平台,通过对各个Web网站的索引进行合并和优化,来构建统一共享的检索平台,系统体系结构如图1所示。
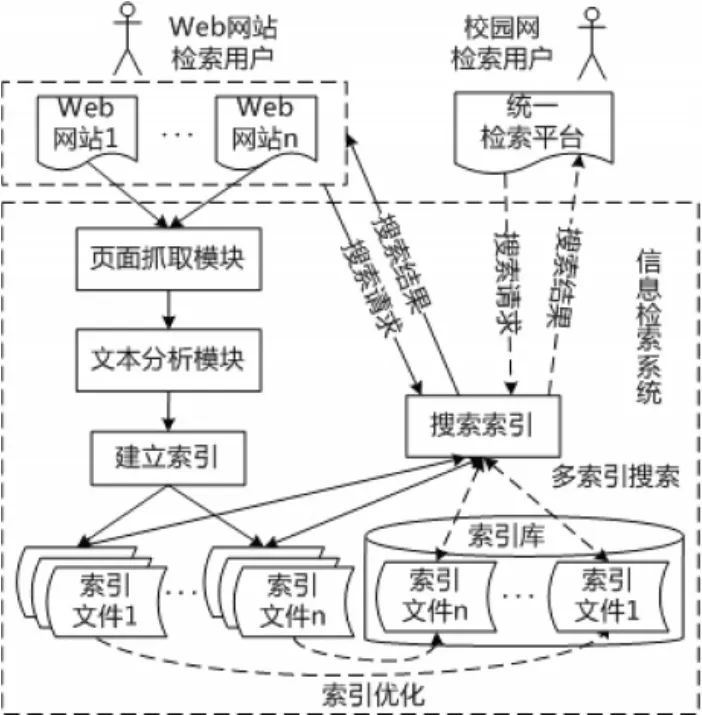
图1系统体系结构
通过该体系结构在下层可以为各个Web网站提供全文信息检索功能,既可以有效缓解各Web网站服务器的压力,又可以提高网站的检索性能。基于Nutch的搜索引擎对各Web网站的网页进行抓取,经过文本分析与分词处理后建立索引,校园网内每个Web网站都建立各自的索引文件,并为各自的Web网站用户提供独立的信息检索功能。在上层系统通过对校园网内各Web网站索引文件的整合,经过索引优化后,实现对多索引的搜索功能,从而为校园网用户提供统一的信息检索平台,并利用各Web网站用户的检索关键词记录建立智能辅助检索关键词库,方便校园网用户的使用。
二、系统主要功能模块
1.汉语分词模块
信息检索的基础是文本分析,而文本分析在很大程度上依赖于分词模块对语言的处理。Nutch自带的CJK分词模块对中文分词的效率和准确度上不能满足实际需要。为此,在对比了JE分词、Paoding分词和ICTCLAS分词等多款中文分词模块后,Paoding分词由于其开源性和良好的分词效果被本系统采用,并通过Nutch的插件机制集成到系统当中。其原理是Nutch中的抽象类Analyzer类实现了配置和插入中文分词模块的接口,该抽象类中定义了一个公有的抽象方法tokenStream(String fieldName,Reader reader),返回的类型是TokenStream。Paoding分词的分词类返回类型也是 TokenStream,故只需将参数fieldName和reader作为Paoding分词的输入参数并将其结果返回给Analyzer类即可。
2.索引优化与多索引搜索
为了有效整合多个Web网站的索引文件,并作为整体提供给统一的信息检索平台,需要进行索引优化,使每个网站只生成一个索引文件。优化索引其实就是将多个索引文件合并成单个文件的过程,目的是减少索引文件的数量,并且能在搜索时减少读取索引文件的时间。Nutch中的IndexWrite类提供了 optimize方法实现该优化操作。要使校园网用户在输入一个关键词后,能够得到全部Web网站的查找结果,就要对不同Web网站优化之后的索引文件进行检索。利用Nutch中的MultiSearcher类可实现该功能,检索结果会以一种指定的顺序合并起来。
3.自定义文档排序方法
根据Nutch自身的关键字相关度排序、索引顺序排序和基于互联网的PageRank引用机制排序都不能在校园网中取得很好的效果。在综合考虑了网页的时效性、访问量和相关度等因素后,系统采用了自定义的排序机制,文档内容相关度作为主要的排序依据,并通过激励因子boost值来改变文档的得分,从而调整文档的出现顺序。激励因子boost=1+max(0,距本学年开始的发布时间)+页面访问量/平均访问量。对于在页面中无法抓取到发布时间和访问量的情况,上述两值别分按照0和平均值处理。由于boost值必须在建立文档索引阶段进行设置,所以目前系统每天进行一次校园网内网页抓取并建立索引。
4.多文档结构的支持
在校园网内,师生大量使用Word、Excel、PDF等文档格式,因此检索系统提供了对上述文档的全文检索功能。由于上述文档并不是纯文本格式,在处理时需要根据他们的特殊格式提取内容后再进行分析处理。在Java对Word、Excel的开源解决方案中,本系统采用了POI插件的方式;用PDFBox插件来实现对PDF文档的读取。
5.智能辅助搜索
系统的两层体系结构能够使位于上层的统一信息检索平台充分利用下层各Web网站的用户检索信息。对于使用Web网站站内检索的用户来说,通常都是熟悉该网站或与该网站内容相关性较大的用户,他们的检索记录在经过一定的分析处理后,可作为知识库来为统一信息检索平台提供智能的辅助检索功能。
三、系统运行环境
系统整体采用Java语言实现,采用Windows平台运行。但由于运行Nutch自带的脚本命令需要Linux环境,所以必须首先安装 Cygwin来模拟这种环境。为了确保Nutch1.0版本能够正确运行,Java虚拟机需采用JDK 1.6以上的版本。系统采用Tomcat 6.0作为各级Web检索平台的容器。运行环境示意如图2所示。
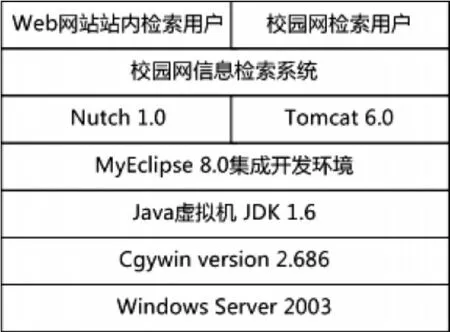
图2 运行环境示意
四、结束语
基于Nutch的校园网信息检索系统建设有效地解决了各Web网站全文信息检索功能不足的问题,同时统一检索平台的搭建为校园网用户提供了方便快捷的信息检索通道,对校园信息化建设起了很好的推进作用。目前系统已经在站内搜索和统一检索平台两个层面实现了基于关键字的检索功能,排序算法也达到了预期的设计要求。今后工作的重点是在此系统基础上对各种校园网资源进行整合、共享,提供对多种异构数据源的支持,使之成为一个综合性应用平台;同时在信息检索技术的基础上对校园网舆情监控技术进行深一步的研究。
[1]Otis Gospodneti,Erik Hatcher.Lucene in Action中文版[M].北京:电子工业出版社,2007.
[2]邱哲,符滔滔.发自己的搜索引擎[M].北京:人民邮电出版社,2007.
[3]马志强等.校园网搜索引擎的研究与实现[J].北京机械工业学院学报,2007(22):12-15.
[4]李粤,安捷,李星.排序融合算法在校园网搜索引擎中的应用[J].大连理工大学学报,2005(45):257-260.
[5]蔡建超,郭一平,王亮.基于Lucene.Net校园网搜索引擎的设计与实现[J].计算机技术与发展,2006(11):73-80.
(编辑:金冉)
TP393.08
B
1673-8454(2010)15-0065-02
宁波市教育科学规划研究课题(2010-YGH057)。
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
高中生·天天向上(2016年9期)2016-11-22 09:10:34
新闻传播(2016年18期)2016-07-19 10:12:06
现代计算机(2016年11期)2016-02-28 18:35:15
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
河南科技(2014年11期)2014-02-27 14:10:19
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
图书馆界(2013年5期)2013-03-11 18:50:29
