
结合景气指数的GDP组合预测模型研究
2010-09-15 08:50:06冯韵,何跃
统计与决策 2010年20期
冯 韵,何 跃
(四川大学 工商管理学院,成都 610064)
结合景气指数的GDP组合预测模型研究
冯 韵,何 跃
(四川大学 工商管理学院,成都 610064)
文章首先对中国季度GDP序列建立了AR-GMDH预测模型;然后加入对GDP相关性较大的景气指数,建立了ARCH模型;最后利用GMDH自组织建模方法提出新的组合预测模型。对比分析各模型预测结果表明:两种单一模型预测误差均在可接受范围之内,基于GMDH组合的GDP预测模型的拟合和预测效果比单一模型更优。
GDP;GMDH;ARCH;景气指数;组合预测
0 引言
GDP是衡量一个国家和地区经济发展状况的核心指标,它的重要性使其一直为研究的热点。围绕GDP的预测,学者们也从不同角度采用各种方法进行了许多研究。近年来,将自组织数据挖掘(SODM)思想运用到实际预测工作中的研究越来越多,因为复杂性科学的观点认为,宏观经济系统是一个复杂系统,众多因素相互关系十分复杂,很难断定其比较固定的变化规律。但宏观经济数据中往往也具有一些特征,其时序模式可能代表着存在的某种周期性、某种趋势和相关关联,我们可以利用这些相对丰富的时序模式来描述宏观经济指标的动态变化。
在现代经济数据调查与统计中,景气指数是重要组成部分,它定性地反映了企业生产经营和宏观经济发展的变动趋势。景气分析能够较为科学地确定和预测经济运行中的转折点,对宏观决策部门及时、准确的把握国民经济运行态势起到了很好的作用。
本文拟首先对中国GDP季度数据序列建立GMDH自回归(AR-GMDH)预测模型;然后用同样能模拟时间序列变量波动性变化的自回归条件异方差模型加入与GDP相关性较大的景气数据建立预测模型;最后运用参数型输入输出GMDH模型进行组合预测。组合预测是一个能聚集各单个预测模型包含的有用信息,从而可提高预测精度的有效方法。
1 模型理论简介
1.1 GMDH模型
数据分组处理方法(Group Method of Data Handling,简称GMDH)是由乌克兰科学院A.G.Ivakhnenko院士在1967年提出的,是一种基于遗传与进化的演化方法,它依据给定的准则从一系列候选模型集合中挑选较优模型[1]。该方法的特点是数据分组和贯穿于整个建模过程中的内、外准则的运用。它将观测样本数据分为训练集 (training set)和检测集(testing set)。用GMDH方法建模时,从参考函数构成的初始模型(函数)集合出发,在训练集上利用内准则(最小二乘法)进行参数估计得到中间待选模型(遗传、变异),在检测集上利用外准则进行中间候选模型的选留(选择)。重复这样一个遗传、变异、选择和进化的过程,使中间候选模型的复杂度不断增加,直至得到最优复杂度模型。
GMDH算法的基本步骤由以下四阶段组成:
(1)将样本集 W 分为学习集 A(training set)、检测集 B(testing set)(W=A+B)。
(2)建立输入变量和输出变量之间的一般函数关系。一般使用Kolmogorov-Gabor多项式参考函数。
(3)选择一个外准则作为一个目标函数。GMDH算法允许众多选择准则,为不同系统确定各自的复杂性,如最小偏差准则。
(4)计算选择准则(外准则)值,选择满足外准则的传递函数作为最优模型继续构建网络,直到最后模型结构不能再改善,得到最优复杂度模型。
1.2 ARCH模型
ARCH模型又称为自回归条件异方差模型(Autoregressive conditional heteroskedasticity model,ARCH),1982 年由恩格尔(Engle,R.)提出。ARCH模型通常用于对主体模型的随机扰动进行建模,它能够有效地提取残差中的信息,被广泛的应用于经济学的各个领域,尤其是在金融时间序列分析中。因此ARCH模型在经济预测中也取得了良好的效果。
ARCH模型建立步骤如下:
(1)建立时间序列数据。
(2)对序列做ARCH效应的LM检验,只有存在ARCH效应时才能继续建立相应的ARCH模型;如果序列存在高阶ARCH效应,即存在GARCH效应,则可以建立GARCH模型。
(3)通过试验进行ARCH模型定阶和参数估计。
(4)根据AIC及SC准则,配合方差表达式参数是否满足平稳性条件及残差独立性检验,通过比较选择适宜的模型。
为全面贯彻国家大力发展特色小镇建设精神,《广西培育特色小镇意见》提出,到2020年,要培育30个左右全国特色小镇、100个左右自治区级特色小镇、建设200个左右市级特色小镇。该意见的出台为广西贯彻国家特色小镇发展战略、发展广西区域经济明确了方向。
1.3 组合预测
由于经济系统复杂多变,在实际应用中,单一模型往往受随机因素影响较大而影响预测效果。组合预测则是对所建立的多个单一预测模型进行综合处理,它能够综合并最大效用地利用各个模型的有用信息,减少单个模型受随机因素的影响。基于GMDH输入输出模型方法的组合预测模型就是利用自组织数据挖掘算法在尽可能多的模型结构形式中进行择优选择,而不仅仅在线性形式中进行计算选择,体现了复杂性科学研究思想[2]。
2 实证研究
本文从国家统计局网站得来2003年1季度至2009年3季度的中国GDP(现价)累计值与当季度的企业景气指数共27组数据,并对GDP累计值作换算季度值处理后作为实验原始数据。将其中2003年1季度至2008年4季度共24个季度的数据用作建模,2009年1至3季度的数据作为预测检验数据。首先利用GDP数据用GMDH模型进行预测,得到YGMDH值;然后运用GDP值与相关景气数据用ARCH模型进行预测,得到YARCH值;再将各单项模型预测结果使用GMDH输入输出模型方法进行组合预测。
2.1 AR-GMDH模型预测GDP
(1)将真实GDP值环比指数化,即用环比预测消除量纲影响:

(2)用自组织建模软件(KnowledgeMiner)计算机筛选出最优复杂度模型:
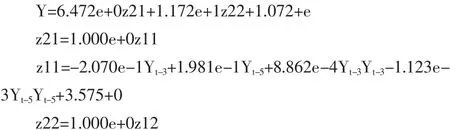

(3)预测结果指标分析
在模型拟合与预测中,R2(R-squared)越接近 1,效果越好。此模型中R2=0.9859,十分接近1,拟合效果好;平均绝对百分比误差(Mean Absolute Percentage Error)越小越好,控制在5%以内均是可接受水平,此模型中MAPE=1.41% ,误差小;预测误差平方和(PESS)越小越好,此模型中PESS=0.0194,预测误差较小。
2.2 ARCH模型预测GDP
进行景气预测。首先通过相关性分析从众多的景气指数中挑选出与被预测指标相关程度较高的特定景气指数i然后将被选定的景气指数连同原先模型中的输入变量组成新的输入变量开始模型计算,从而得到模型结果进行预测[3]。
(1)将 2003年 1季度至2008年 4季度 GDP真实值和2003年1季度至2009年3季度景气指数作为建模数据,根据前面介绍的步骤建立模型,模型定阶为ARCH(1)。
(2)用Eviews软件[4]建立最终模型为:

(3)预测结果指标分析:
此模型中R2=0.9982,充分接近1,拟合效果很好;平均绝对百分比误差 (Mean Absolute Percentage Error)=1.56%,误差较小。
2.3 组合模型预测
上述两个模型从不同角度建立。第一个模型运用单序列自回归,ARCH模型属于多变量建模,因此组合上述两个模型可以结合各种模型优点、综合利用各方面有用信息。
分析预测值与实际值发现,二者之间存在着非线性关系,使用非线性组合预测法更适用于GDP预测[5]。GMDH输入输出模型是根据自组织数据挖掘原理,并允许以非线性模式建模的方法。本文以 YGMDH、YARCH作为模型输入,使用GMDH输入输出模型将各个单模型预测结果组合起来,得到最终的组合模型为:

此模型中R2=0.9951,充分接近1,拟合效果很好;平均绝对百分比误差 (Mean Absolute Percentage Error)=1.19%,预测误差平方和(PESS)=0.0075,误差均非常小,预测效果好。
2.4 实验结果对比分析
从各模型的实验结果参数(R2值与平均绝对百分比误差值等)可以看出,各模型预测效果不错,相对误差均能控制在4%以内。表1为各模型预测效果对比,其中AR-GMDH模型预测结果是季度GDP环比预测值换算成为真实值。

表1 2009年前3季度预测结果对比
从表1可以看出,基于GMDH组合模型在GDP预测中取得了良好的效果:组合模型的平均绝对百分比误差最小,相对误差均在1%左右,效果比较满意。虽然在某些年份的预测中,单模型可能会好于组合预测(如2009年1季度ARCH模型预测值好于组合模型,2季度GMDH模型预测好于组合模型),但是标准误差却远大于组合预测的标准误差,并且相对误差的波动性较大。这均说明了组合预测是能够提高整个模型的预测精度的。
3 结语
本文首先以2003年1季度至2008第4季度中国GDP值建立了AR-GMDH预测模型,然后加入相关景气数据建立了ARCH预测模型,对2009年第1季度至第3季度的GDP进行预测。在此基础上为了提高模型预测精度,利用GMDH组合预测方法对两个单一模型预测结果进行了组合。通过将组合预测值与2009年1至3季度的GDP实际值以及各模型预测值进行比较,得出以下结论:
(1)虽然单个模型预测效果也令人满意,但组合模型能够集合单个模型的优点,提高预测精度。
(2)加入相关景气数据能增加建模的有用信息,提高模型预测能力。每个单模型的拟合预测效果好,更能提高组合模型的精度。
[1]Ivakhnenko A.G.,Mueller J.A.Problems of an Objective Computer Clustering of a Sample of Observations[J].Soviet Journal of Automation and Information Sciences c/c of Avtomatike,1991,24(1).
[2]贺昌政.自组织数据挖掘与经济预测[M].北京:科学出版社,2005.
[3]何跃等.运用统计指标与景气指数对工业经济的组合预测[J].统计与决策,2007,(9).
[4]易丹辉.数据分析与EVIEWS应用[M].北京:中国统计出版社.
[5]魏仕强等.基于ARMA-ARCH的GDP组合预测[J].统计与决策,2007,(5).
(责任编辑/亦 民)
F201
A
1002-6487(2010)20-0019-03
国家自然科学基金资助项目(70771067)
冯 韵(1988-),女,四川巴中人,硕士研究生,研究方向:数据挖掘、管理信息系统。
何 跃(1961-),男,重庆人,博士,副教授,研究方向:数据挖掘、决策支持系统。
猜你喜欢
今日农业(2022年14期)2022-09-15 01:43:28
国际太空(2022年2期)2022-03-15 08:03:22
国际太空(2021年11期)2022-01-19 03:27:06
国际太空(2021年8期)2021-11-05 08:32:44
大众投资指南(2021年35期)2021-02-16 01:06:26
消费导刊(2018年7期)2018-08-22 03:28:26
消费导刊(2018年10期)2018-08-20 02:56:08
消费导刊(2018年8期)2018-05-25 13:19:21
产品可靠性报告(2017年5期)2017-08-30 09:57:46
电力与能源(2017年6期)2017-05-14 06:19:37
