
SQL Server大数据量数据库性能优化初探
2010-09-07 05:32吴纲
武汉船舶职业技术学院学报 2010年1期
吴 纲
(武汉职业技术学院计算机学院,湖北武汉 430074)
在实际业务系统中,历史数据是需要保存的,因为一是需要进行回溯查询,查看一段时间内或者历史同期的情况做出性能比较;第二,这也是数据挖掘的基础,利于性能优化。但是历史数据会占用大量的空间,本文提到的移动基站设备性能数据,每个月的数据量大概有200万条,初始系统运行近一年后,总记录量约2500万条、数据库的大小也有近70GB,频频出现查询历史数据缓慢的情况,并在Brow ser端常常显示超时报警提示。
SQL Server作为一种企业级的数据库,提供了丰富的特性,比如分区视图、索引视图、聚集索引、查询优化器等,开发者可以从多个角度进行性能分析与优化。实践表明,只要适当进行优化,在普通配置的服务器上,一亿条记录以内的情况,SQL Server数据库的性能是完全可用的。
1 优化方法
本文操作背景是一个地市级移动基站设备性能的历史数据库,经常需要对历史数据进行查询操作。性能数据的导入是通过SQL SERVER DTS(数据转换服务)定时任务来进行。
1.1 索引与查询优化
索引相当于书的目录或者索引,对于查询条件中常用的列一般需要建立索引,当根据索引码的值搜索数据时,索引提供了对数据的快速访问[1]。
(1)主键索引
建立数据库的时候,一般需要为每张表指定一个主键来唯一标识表中某一行的属性或属性组,一个表只能有一个主键,主键还常与外键构成参照完整性约束。
(2)聚集索引与非聚集索引
索引有两种类型,聚集索引是对表的物理排序,相当于书的目录,每个表只能有一个聚集索引,而非聚集索引则相当于书的索引,可以有多个[2]。
聚集索引有两个最大的优势:以最快的速度缩小查询范围和以最快的速度进行字段排序。聚集索引对于那些经常要搜索范围值的列特别有效,使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期,这样有助于提高此类查询的性能[3]。
聚集索引是重要和唯一的,因此要将聚集索引建立在最频繁使用的、用以缩小查询范围的字段上或最频繁使用的、需要排序的字段上等。查询特定时期特定地区的历史数据,自然要对时间字段和空间字段进行索引,按日期或者地区来建立聚集索引是好的选择,后面的试验结果印证了这一点。
(3)查询优化器
SQL Server、Oracle这些企业级数据库在执行查询之前,利用查询优化器来“智能地进行分析”,自动选择最优的查询计划。查询优化器检查查询条件是否满足SARG约束,满足称之为可优化的,并可以利用索引快速获得所需数据;如果查询条件表达式不能满足SARG的形式,索引这时候是无用的。值得提醒的是,虽然SQL查询优化器大部分时间工作性能好,但也有例外,必要的时候可以强制使用索引或者查询计划[4]。
(4)分页存储过程与索引
对于B/S类应用,查询结果展示依赖分页的存储过程,分页的一个前提是分页的列应该是个唯一列。上面提到聚集索引是提高性能的关键之一,对于历史数据聚集索引是日期,而日期是不唯一的,因此不能作为分页列,这样就产生了矛盾。解决的技巧是可以用日期列getdate()作为辅助列,配置 UNIQUE约束,从而满足分页的需要,并且将此列作为聚集索引列。
1.2 其它优化方法
1.冗余与缓存机制
根据空间换取时间的原则,在数据库设计进行优化的时候,可以采用适当的冗余或者缓存机制。索引也可以算是一种特殊的空间换取时间机制。
冗余的例子比如对于一些经常要计算得到的列,可以增加一个冗余的计算字段,这样除了生成的时候进行一次计算,再查询的时候就不需要重新计算,从而提高查询速度。
对于某些性能瓶颈,可以考虑引入缓存或者中间表,缓存典型用法就是中间表,例如要分区域统计历史性能数据,如直接从历史数据表实时进行统计处理的话,需要很长时间计算,可以设计一个统计结果中间表保存中间统计结果,即分区统计结果的历史数据缓存,这样进行分区域统计的时候就可以直接存取这个中间表,避免性能问题。还可以充分利用DTS/SSIS服务和SQL Server自动化机制,后台不断的定时计算并生成这个中间结果。
2.数据分片与分区
除了表模式优化、索引、内部调校、冗余处理外,最有效的方法就是“分而治之”。实际操作中多是下面三种手段及其组合应用:
(1)分散(分片)
根据数据的时间局部性和空间局部性原则,将海量数据表Sharding(分片)/分割成多个表,如按IP地址散列、按时间切割、按地理范围等,解决数据库扩展性问题,一般有两种分片方法,即横向分片和竖向分片。开源数据库如MySQL广泛使用数据库分片技术,用户可以自己编写程序来实现,也可使用一些HSCALE等第三方分片软件来实现。商业数据库如Oracle、SQL Server等还内置标准化的分片机制,如分区视图[5],例如处理本文提到的基站设备性能历史数据可以按时间分区或者地理分区。
另外将数据库分成不同的文件和文件组,充分利用RAID及在多个驱动器之间分配 I/O,也可以认为是一种底层的分片思路,可以提高磁盘操作的寻道时间和访问速度。
⑵分布
多台机器的分布式存储,著名的如Google的分布式存储。
(3)分层(级)
多级存储访问,如内存文件系统、Memcache缓存和内存数据库等。
2 测试与性能分析
2.1 性能分析方法与工具
(1)性能计数器分析
在window s xp/2003 server中打开管理工具→性能,添加SQL性能计数器,其有很多SQL组,通常关注的有:用户连接;锁请求/秒,如发现锁操作总体过大,应该从应用层面进行分析优化;完全扫描/秒,计数器指示有多少不使用索引而进行的全表扫描,应分析SQL查询语句和数据库索引的对应关系,追加必要的索引以减少全表扫描的次数。
(2)通过使用SQL事件探查器和查询分析器等工具对SQL Server内部语句执行的性能状况列出明细表,并可将CPU占用较高的任务列出。
(3)通过SQL查询分析器分析查询的执行计划,找出性能瓶颈的SQL语句,进行针对性优化。
2.2 测试环境与测试项目
本文的测试平台为:软件系统是Windows 2003 server SP2,SQL Server2000 SP4企业版;硬件平台为Xeon 5110,4GB内存,1TB SATA硬盘。
(1)查询时间计算

(2)回避查询缓存的影响
SQL Server占用的内存主要由三部分组成:数据缓存(Data Buffer)、执行缓存(Procedure Cache)以及SQL Server引擎程序(所占用缓存一般相对变化不大)。查询缓存会对测试有所影响,因此每次测试后要清理缓存,保证测试结果的客观。
清除步骤如下:
CHECKPOINT--将当前数据库的全部脏页写入磁盘。
DBCC DROPCLEANBUFFERS--从缓冲池中删除所有清除缓冲区。
DBCC FREEPROCCACHE--从过程缓存中删除所有元素。
DBCC FREESYSTEMCACHE('ALL')——从所有缓存中释放所有未使用的缓存条目
DBCC FLUSHPROCINDB({DBID}):清理指定数据库实例中存储过程使用的缓存。在测试时保证以前的存储过程计划不会对测试结果造成负面影响,可以使用这个存储过程。
值得指出,清理缓存后,应紧接着执行查询,因为SQL Server会时刻自动往缓存里读入最需要的数据页。
2.3 索引的测试
测试分三种情况:
(1)没有任何索引;
(2)非聚集索引(在时间字段上建立一个非聚集索引);
(3)聚集索引(在时间字段上建立一个聚集索引)。
分别运行如下测试样例,每次测试前使用前述计算时间的算法并且清理缓存。
(1)查询性能测试
测试样例1:导出某一时段的历史数据,测试基本历史数据查询功能。

测试样例2:历史数据统计分析,测试聚合查询功能。

测试结果数据如表1所示,绘制分析图如图1所示。
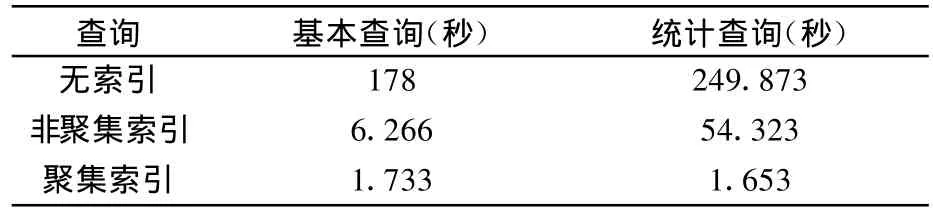
表1 查询操作测试数据
从图1容易看出,在实际测试中,在数据数量巨大的情况下,使用或不使用索引对查询性能影响非常显著,没有使用索引之前,查询一段历史记录需要3 min左右,使用非聚集索引一般就是在6~7 s,而使用聚集索引后基本就在2 s内,聚集索引比非聚集索引又有一定提升,尤其是使用聚合函数进行统计分析查询时,性能提升十分显著。

图1 查询性能图
(2)Update/Insert/Delete性能测试
测试样例3:测试Update/Insert/Delete单条记录的性能。

测试结果数据如表2所示,绘制分析图如图2所示。
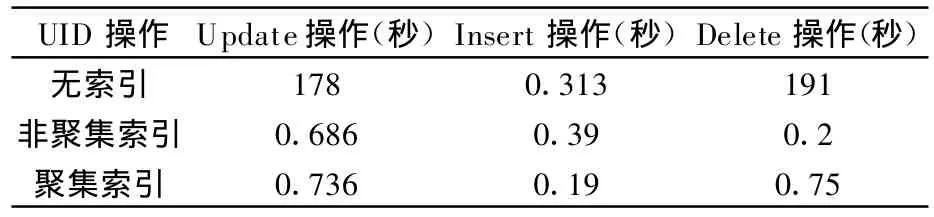
表2 Insert/Delete/Update操作测试数据
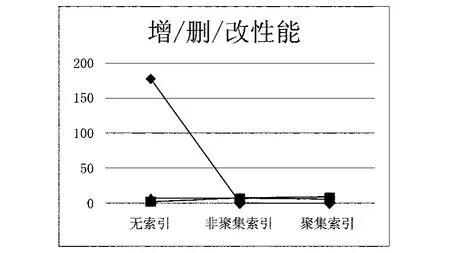
图2 增/删/改性能图
从图2看出,插入操作当有索引时反而可能会降低速度,因为还增加了写索引操作,而更新和删除操作首先是要按条件检索数据,然后进行更新操作,对于一个海量数据表来说,检索是主要的消耗,因此这种情况下的更新和删除操作,在有索引的时候性能有很大提升。
3 结 语
数据库的发展趋势是数据量越来越大,开发数据库时对海量数据,如历史数据等,进行分析和挖掘也越来越重要,利用SQL Server等企业级数据库提供的特性,使用多种方式组合对表进行优化,如本文得出的一个结论是聚集索引非常关键,而一个表只能有一个聚集索引,应该合理应用。同时要善于利用数据库的工具,如系统性能计数器、查询分析器、SQL事件探查器等,有针对性地分析和调校性能。
1 Ryan K.Stephens,Ronald R.Plew.何玉洁等译.数据库设计[M].北京:机械工业出版社,2001,9.
2 Kalen Delaney.聂伟等译.Microsoft SQ L Server 2005技术内幕:存储引擎[M].北京:电子工业出版社,2007,9.
3 胡百敬,姚巧玫,刘承修.SQL Server 2005 Performance Tuning性能调校[M].北京:电子工业出版社,2008,6.
4 Robert Vieira.董明等译.SQL Server 2005高级程序设计[M].北京:人民邮电出版社,2008,4.
5 使用分区视图.SQ L Server联机丛书[EB/OL].http://technet.microsoft.com/zh-cn/library/ms190019.aspx
猜你喜欢
词学(2022年1期)2022-10-27
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
智能制造(2021年4期)2021-11-04
河北电力技术(2021年2期)2021-07-29
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
火控雷达技术(2018年4期)2019-01-15
知识经济·中国直销(2018年7期)2018-07-27
电脑知识与技术(2017年16期)2017-07-14
