
基于减法聚类改进的模糊c-均值算法的模糊聚类研究*
2010-08-14 01:11:50李义杰
网络安全与数据管理 2010年16期
于 迪,李义杰
(1.辽宁工程技术大学 研究生学院,辽宁 葫芦岛 125105;
(2.辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
模糊聚类作为无监督机器学习的主要技术之一,广泛应用于数据挖掘、矢量量化、图像分割、模式识别、医学诊断等领域。引入模糊数学方法,通过建立数据样本类属的不确定描述,将相似性质的事物分开并加以分类,能比较客观地反映现实世界。
模糊c-均值(FCM)算法是模糊聚类的基本方法之一,它是一种聚类不定归属的方法。它通过引入隶属度函数来表示每个样本点属于各个类别的程度,从而决定样本点的类属,对数据进行软划分。
FCM算法就是通过搜索目标函数的最小点,反复修改聚类中心矩阵和隶属度矩阵的分类过程。目前算法的收敛性已得到证明[1],但它是一种局部搜索算法,对初值的选取十分敏感,如果初值选取不当,它容易收敛到局部极小点。且FCM对孤立点数据、样本分布不均衡也很敏感。鉴于此,提出基于减法聚类的改进的模糊c-均值聚类,使得算法的收敛速度和准确性都得以改善。
1模糊c-均值算法分析
设样本空间为X={x1,x2,…,xn},其中每个元素包含 s个属性。模糊聚类就是将x划分为c类,c个聚类中心为v={v1,v2,…,vc}。uij是样本空间X中的第 j个元素对第i个类中心的隶属度。dij=‖vi-xj‖是第 i个聚类中心与第j个数据点之间的欧几里德距离,在FCM聚类算法中,隶属度矩阵和聚类中心分别为U={uij}和V={vi},FCM算法的目标函数为:

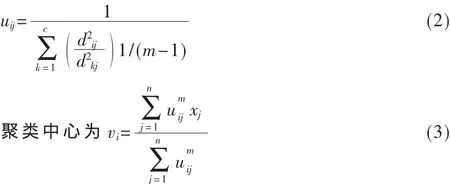
2基于减法聚类的改进的模糊c-均值算法
2.1初始聚类中心的选择
减法聚类是一种爬山法,它把所有的样本点作为聚类中心的候选点,其基本思想是计算每个样本点的密度指标,如果该样本点周围的点多,则密度指标就大,就选取密度指标最大的样本点作为聚类中心。减法聚类是一种快速独立的近似的聚类方法,用它计算,计算量由样本数目决定且与样本点的数目成简单的线性关系,而且与所考虑问题的维数无关。
M维空间的 n个样本点 xi(i=1,2,…,n)全部都为聚类中心的候选点,定义样本点xi处密度指标为:

减法聚类的过程如下:
(1)用式(4)计算每个样本点 xi的密度指标,选择具有最高密度指标的数据点xc1作为第一个聚类中心,Dc1为其密度指标。其中ra是一个正数,定义了该点的领域半径,半径以外的数据点对该点的密度指标贡献非常小,这里取:
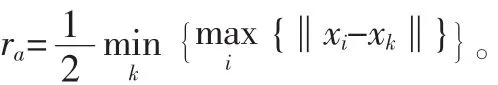
(2)令xci为第 i次选出的聚类中心,Dci为其密度指标,则其他样本点的密度指标可用式(5)修正。选出密度指标最高的数据点xci+1作为新的聚类中心。其中rb是一个正数,定义了一个密度指标函数显著减小的领域,这里取 rb=1.2ra。
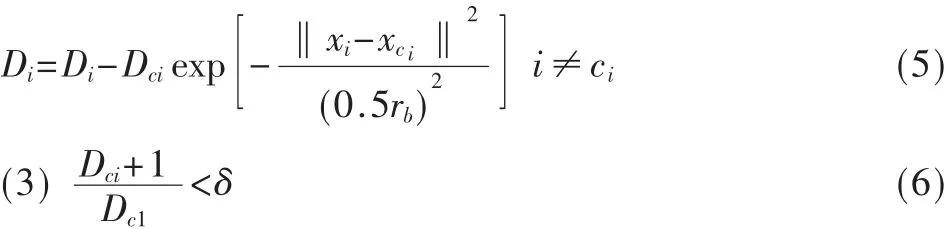
判断式(6)是否成立,若不成立,则转到步骤(2);若成立则退出。预先给定参数δ、ra、rb。δ决定了最终产生的初始聚类中心数目,δ越小,产生的聚类数越多;反之则聚类数越少。ra,rb越大,产生的类数就越少,反之,则产生的类数就越多。
2.2改进的FCM算法
(1)为样本加权
样本空间为X={x1,x2,…,xn},每个样本点对于分类结果来说贡献是不同的,例如样本空间中,孤立点就是对分类不重要的样本点,FCM算法对于这一点不敏感。因此为了区分各个样本点的不同之处,给每个样本点赋予一个权值 wi[4]。

则计算聚类中心的公式变为:

其中 d(xi,xj)表示两个样本点 xi与 xj之间的欧式距离,d(xi,xj)的值越接近0则表示xi与xj之间越相似或越接近,则权重wi越大;反之,xi,xj差异性越大或越远,则权重wi越小。如果样本点周围的点越多,则它的权重越大,因此可以用权重wi表示第i个样本xi对分类的影响程度。由于算法中噪声和孤立点的权重比较小,这样就能消除它们的影响。为样本加权后目标函数为:

(2)修正隶属度矩阵
FCM算法的思想是:迭代调整隶属矩阵和聚类中心使目标函数值最小,为保证FCM算法每次的迭代都朝着全局最优的方向逼近,其关键就在于保证确定V的下一次迭代值,加快收敛于全局最优点的速度。在此采用修正隶属矩阵来计算下一次迭代的聚类中心,使得到的V更靠近聚类中心,更合理,从而提高FCM算法的收敛速度。因此修正隶属度矩阵[5]可以提高聚类速度,使聚类效果更好。
样本离聚类中心距离越远属于该聚类中心的程度越小,反之越大,样本对类中心的影响即称为样本对类中心施加的吸引力,在这里设定了一个抑制因子,由它来控制对离样本点次最近的类中心的抑制作用。
当α=1时,算法退化为 FCM算法,对离样本点次最近的类中心没有任何抑制作用。
当α=0时,算法完全抑制了样本对离它次最近类中心的吸引力,对离样本最近类中心的吸引力的增强力度最大。
当1<α<0时,算法对离样本次最近类中心的吸引力有一定的抑制作用,对离样本最近类中心的吸引力有一定的增加作用。
修正隶属度矩阵的过程如下:
(1)初始化类中心为V(0)。迭代次数L=0给定模糊指数m,m∈(1,∞)置吸引力抑制因子α(即样本点对离它最近的类的吸引力),α∈[0,1]。
(2)计算出 U(L):
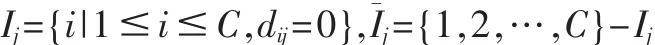
当 Ij=φ 时;

当 Ij≠φ 时,∀i∈Ij,uij=0,

(3)修正隶属度矩阵 U(L):假设样本 xi对第 q类的隶属度最大,值为uqi;它对第s类的隶属度次最大,值为usi。
对其进行修正后,样本xi对第q类的隶属度为:

对第s类的隶属度为:

除此之外各类的隶属度不变。
(4)用修正后的U(L)计算下一次的迭代中心V(L+1)(加 权 后 的 Vi)。

(5)判断是否终止迭代。终止而退出,否则,L=L+1,返回步骤(2),继续迭代。
经过对隶属度矩阵的修正可知:改进后的算法,样本点增大了对离它最近的类中心的吸引力强度;样本点减小了对离它次最近的类中心的吸引力强度,从而减弱了离样本次最近类中心对离样本最近的类中心收敛速度的延缓作用。对其余类中心的吸引力强度不变,从而提升了FCM算法的收敛速度。
2.3基于减法聚类改进的模糊c-均值算法过程
为保证改进的FCM聚类结果为全局最优解,采用减法聚类的聚类中心作为改进的FCM聚类的初始聚类中心。算法步骤如下:
(1)设定聚类参数:领域的半径 ra、rb,比例参数 δ,FCM聚类数c,模糊指数m和最小误差ε,迭代次数L,吸引力抑制因子α。
(2)应用式(4)计算所有样本点的密度指标,将密度指标最高的一个作为第一个聚类中心点xc1。
(3)依据公式(5)利用减法步骤(2)中的 xc1进一步计算余下的n-1个数据点的密度指标,找出最高的作为第二个聚类中心xc2,依此类推,找到 p个聚类中心,从中选取前c个作为FCM的初始聚类中心v(0)。
减法聚类中心中,密度指标越大的聚类中心出现得越早,越有可能成为改进的FCM初始聚类中心。所以,当聚类数为c时,取减法聚类产生的前c个聚类中心作为改进的FCM的初始中心,无须再重新初始化,从而提高了聚类的效率。
(4)求式(10)的最小值
(5)按式(11)和式(12)计算出隶属度U(L)
(6)依据式(13)和式(14)修正隶属度矩阵 U(L)。
(7)依据式(15),用修正后的 U(L)计算下一次的迭代中心 V(L+1)。
(8)判断是否满足终止迭代条件。对给定的阈值,‖U(L+1)-U(L)‖<ε如果终止而退出,否则,L=L+1,返回步骤(5),继续迭代。
3仿真与结果分析
为验证基于减法聚类的改进的FCM算法的效果,利用Iris植物样本数据进行仿真实验,将结果与传统FCM进行对比。Iris数据集是公认的最适用于数据挖掘的数据集,它有四个属性、三种植物种类(setosa、versicolor、virginica),每个种类含有50个样本。Iris的实际中心分别为(6.588、2.974、5.552、2..026)、(5.006、3.418、1.464、0.244)、(5.936、2.77、4.26、1.326)。分别用传统的 FCM 和基于减法聚类的改进的FCM对Iris数据集进行聚类分析。实验中,设定允许最小误差ε均为10-3,模糊指数m=2,ra=0.5,rb=0.6,α=0,Iris数据集的聚类结果如图 1、图 2所示。Iris数据集的比较如表1所示。
从图1、图2与表1中可以看出,传统FCM与本文中的算法相比迭代次数少、搜索速度更快、聚类平均准确率更高。

图1两种算法收敛速度的比较
基于减法聚类的改进的FCM算法很好地解决了FCM算法对初始值敏感及易陷入局部最优的问题,同时也改善了FCM对孤立点敏感的问题,提高了聚类的速度,具有很高的实用价值。
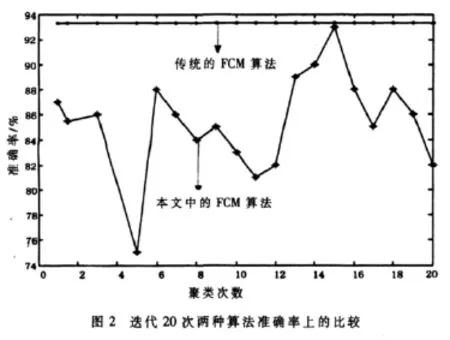

表1 Iris数据集的性能比较
[1]GAMES R A,CHAN A H.A fast algorithm for determining the linear complexity of a pseudorandom sequence with period 2n[J].IEEE Trans Inf Theory,1983,IT-29(1):144-146.
[2]HAND D,MANNILA H,SMYTH P.Principles of data mining[M].Cambridge MA:MITPress,2001.
[3]PAL N R,CHAKRABORTY D.Mountain and subtractive clustering method;Improvements and Generalization.International Journal of Intelligent Systems,2000,15(4):329-341.
[4]齐淼,张化祥.改进的模糊c-均值聚类算法研究[J].计算机工程与应用,2009,45(20).
[5]闫兆振.自适应模糊c-均值聚类算法研究[D].济南:山东科技大学,2006.
猜你喜欢
Journal of Palaeogeography(2022年1期)2022-03-25 04:17:00
快乐语文(2021年35期)2022-01-18 06:05:30
法律方法(2019年4期)2019-11-16 01:07:28
故事作文·低年级(2019年4期)2019-04-17 18:51:26
故事作文·低年级(2019年4期)2019-04-17 18:51:26
电子测试(2017年15期)2017-12-18 07:19:27
时代英语·高一(2017年5期)2017-11-14 17:00:51
摄影之友(影像视觉)(2017年1期)2017-07-18 11:12:16
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
