
一种增强的基于GCA的入侵检测方法
2010-08-13 09:19付双胜张明军刘棣华鲁晓帆
网络安全技术与应用 2010年10期
付双胜 张明军 刘棣华 鲁晓帆
长春工业大学计算机科学与工程学院 吉林 130012
0 引言
近年来,将聚类分析方法应用于入侵检测方面的研究变得非常活跃,它也是一个极富挑战性的研究领域。我们把物理或抽象对象的集合分组成为类似的对象组成的多个类或簇的过程叫做聚类。由聚类所生成的簇是一组数据对象的集合,在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。聚类分析是一种探查数据结构的工具,其核心是聚类。聚类分析也是一项基本分析技术,属于非监督学习技术,不需要以先验标识符来标定数据类别标号的假定。因此基于聚类的入侵检测技术就是一种无监督的检测技术,其优点是它可以在未标记的数据上训练并检测入侵,而且能有效的检测出未知入侵。当前无监督的检测技术主要存在以下不足:①在聚类过程中只考虑元素与类之间的距离,而没有考虑类大小产生的影响;②检测结果对参数较敏感,参数选择往往凭经验确定,没有一般的原则;③“元素个数越少的簇越可能是异常簇”的假设不尽合理。针对上述问题,文献[2]提出的基于引力的聚类方法GCA的入侵检测技术,尽管该技术在时间复杂度以及检测的准确性等明显优于其他一些检测方法,但是它的误报率相对来说还是有点偏高,本文在文献[2]的基础上提出一种增强的基于GCA的入侵检测方法,有效地降低了检测的误报率。
1 基于引力的聚类方法GCA
将万有引力的思想引入聚类分析,文献[2]提出了基于引力的聚类算法GCA,将聚类过程看成对象被已有类吸引的过程,对象依次被吸入到对其引力最大的簇中或产生一个新的簇。具体的算法描述如下:
(1)初始时,簇集合为空,读入一个新的对象;
(2)以这个对象构造一个新簇;
(3)若已到数据库末尾,则转(6),否则读入新对象,计算每个已有簇对它的引力,并选择最大的引力;
(4)若最大引力小于给定的引力阈值r,转(2);
(5)否则将该对象并入具有最大引力的簇中,并更新该簇的各分类属性值的统计频度急数值属性的质心,转(3);
(6)保存每个簇的摘要信息及引力阈值r,结束。
2 增强的基于GCA的入侵检测方法
2.1 “元素越少的簇越可能是异常簇”的假设不尽合理的原因及改良方法

图1 簇的大小与异常簇的判定的关系
如图1所示,设簇C1包含1200个对象,簇C2包含1000个对象,簇C3包含100个对象,簇C4包含40个对象。按簇的大小作为判定簇是否为异常的依据,则簇C4较簇C3异常程度大,但是直观地看簇 C3偏离整个数据集的程度较簇C4要大,簇C3较簇C4更应该判定为异常类。所以说“元素个数越少的簇越可能是异常簇”的假设不尽合理。
在给簇作标记时,倘若按照“元素个数越少的簇越可能是异常簇”的原则,原本是正常数据的簇C4就会标记为异常,而本来是异常数据的簇 C3可能标记为正常,这就导致误报率大大提高。针对这个不合理性,本文提出了一个合并算法,按照一定规则把像簇C4那样的小簇合并到像簇C1或簇C2这样的大簇中,合并后就变成簇 C3的元素最少了,把它标记为异常即可,这样标记更趋于合理,从而达到降低检测误报率的目的。
2.2 增强的基于 GCA的入侵检测方法的主要思想
对训练集先用基于引力的聚类方法 GCA进行聚类,聚类后会得到一定数目的簇,在这个基础上依据凝聚层次聚类算法的思想对这些簇进行合并,根据簇间的差异度,使用整体相似度作为聚类质量评价标准来决定是否要合并相似的两个簇,合并后能使簇中心更集中,簇内对象更紧密。再根据标记算法标记出聚类结果中哪些簇属于正常簇,哪些属于入侵簇,最后用检测算法对测试集数据进行检测。
2.3 增强的基于GCA的入侵检测算法
本文提出的增强的基于 GCA的入侵检测算法主要由GCA聚类、合并算法、标记算法与检测入侵四部分组成。GCA聚类在前面已有阐述,这里将后面三个部分作个简单的描述。
2.3.1 合并算法
第三步:查找出最小差异度Spq对应的那两个簇Cp与
第四步:计算出Cp、Cq、Cp∪Cq的整体相似度
第五步:若ovs(Cp∪Cq)≤ovs(CP)或者ovs(Cp∪Cq)≤ovs(Cq),则合并簇Cp与Cq,计算新的合并簇Cp∪Cq的数值属性中心与分类属性频度,更新聚类差异度,转到第二步;否则,在差异度排序序列中查找出Spq后继的那个差异度Spq+1,并找出对应的那两个簇Cg与Ch(1≤g≤k,1≤h≤k),转到第四步;若差异度Spq已经是排序序列的最后一个,则算法结束。
2.3.2 标记算法
根据文献[4]定义的大簇和小簇的概念,再依据数据集中正常的数据数量要远大于异常数据的数据量的假设,本文给出了如下标记算法:
(1)计算各簇Ci的成员个数,其中i=1∼k,调用Quick排序算法将按降序排列。
(2)设置参数α的值。
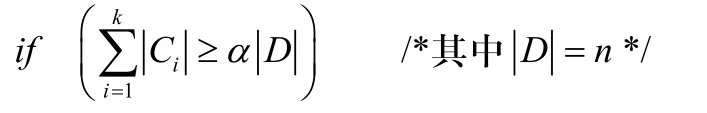
2.3.3 检测算法
检测算法主要分为两步,第一步,计算待检测的数据包与训练过程中建立的所有簇之间的距离。并找出最小距离。第二步,若最小距离大于R,则判定该数据包为未知攻击,其中 R为新的簇半径(通常利用聚类结果计算出所有数据点到所有簇的距离的平均值,将该平均值设为新的簇半径R),否则找出待检测的数据包与训练建立的簇之间的距离最小的那个簇所属的标记,若标记为正常,则待检测的数据包是正常数据,若标记为异常,则待检测的数据包是异常数据。
3 实验结果
使用KDDCUP99 15%的子集来测试算法的性能,将这个子集随机的分为P1,P2两个子集,其中P1含487052条记录(normal占 96.2%),P2 含 247948 条记录(normal占 97.8%),其中 P2中包含 P1中没有出现过的 loadmodule、perl、warezmaster等攻击类型。用P1作训练集,P2做测试集进行检测,实验结果表明,增强的基于 GCA的入侵检测方法与文献[2]总的检测率相当,误报率下降明显,并对未知攻击的检测率有所提高。表1是文献[2]与本文方法检测结果对照表。
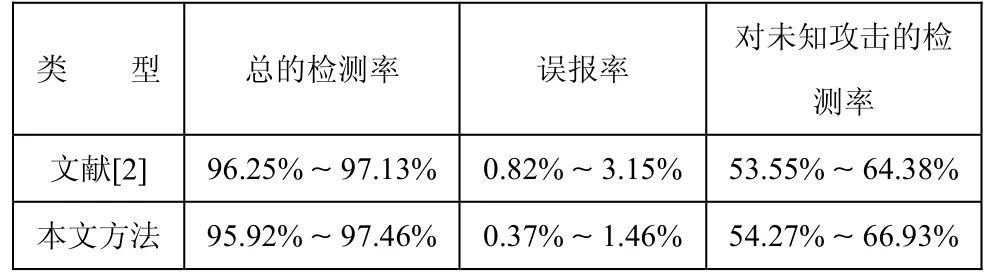
表1 文献[2]与增强的基于GCA的入侵检测方法检测结果对照表
4 总结
这种增强的基于 GCA的入侵检测方法在降低误报率等检测性能有了相当大的提高,而且该检测模型是可以增量更新的,便于扩展。但是阈值的确定要依靠抽样计算获得,虽然给出了确定阈值的方法,但比较麻烦,还有合并算法中整体相似性度量的准确性都需要我们进一步的探索。
[1] Kim,Bentley.Immune Memory and Gene Library Evolution in the Dynamic Clonal Selection Algorithm[J].Journal of Genetic Programming and Evolvable Machines.2004.
[2] 蒋盛益,李庆华.基于引力的入侵检测方法[J].系统仿真学报.2005.
[3] 曹元大.入侵检测技术[M]第 1版.北京:人民邮电出版社.2007.
[4] Zengyou He,Xiaofei Xu,Shengchun Deng.Discovering Cluster Based Local Outliers[J].Pattern Recognition Letters. 2003.
[5] Minho Kim,R.S.Ramakrishna.Projected Clustering for Categorical Datasets[J].Pattern Recognition Letters.2006.
猜你喜欢
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
计算机与数字工程(2022年3期)2022-04-07
煤气与热力(2021年6期)2021-07-28
民用飞机设计与研究(2020年4期)2021-01-21
当代陕西(2020年15期)2021-01-07
设备管理与维修(2020年14期)2020-08-12
网络安全和信息化(2018年4期)2018-11-09
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19
现代电子技术(2015年21期)2015-11-09
第二课堂(课外活动版)(2015年4期)2015-10-21
