
一种基于聚类的多数据库分类方法设计
2010-08-07 08:20曹慧
网络安全技术与应用 2010年6期
曹慧
广西师范大学计算机科学与信息工程学院 广西 541004
0 引言
数据挖掘这一概念最早是在 1995年的美国计算机年会(ACM)上提出的。数据挖掘(Data Mining)又称知识发现,概括来说是指从大量的,不完全的,有噪声的、随机的数据中,提取出隐含其中的不为人知的潜在有用的知识的过程。数据挖掘是一种新型的数据分析技术,被广泛应用在金融、保险、教育、制造等行业和国防科研上,带来了巨大的经济和社会效益。正因为如此,数据挖掘这一研究领域吸引了许多专家和学者的关注。随着研究的深入,越来越多的新方法被提出,对整个数据挖掘领域的发展起到了巨大的推动作用。就目前而言,数据挖掘的方法大多数集中在对单个的数据库进行挖掘。但是在实际应用中,需要挖掘的数据往往不是单一的数据库,而是多个数据库。如许多大型的公司,其下属的每个子公司都有自己相应的数据库,当总公司需要对各个子公司的数据进行分析的时候,就必须寻找一种新的方法来进行挖掘,因为传统的单数据库挖掘算法已经不再适用了。
总体来说,多数据库挖掘的方法可以归结为以下三类:①先把挖掘任务涉及到的所有数据库进行集成,生成一个大数据库,然后应用常规的数据库挖掘算法进行挖掘;②使用基于归纳逻辑编程的方法(Inductive Logic Programming),用命题逻辑表示各个实例,直接从多个数据库中挖掘模式;③对每个数据库进行单独挖掘,得到局部模式,再通过模式集成把这些局部模式集成得到一个全局模式。本文提出一种中间的方法,把多个数据库进行聚类,结构相似的数据库聚到同一个簇中,可以使用同样的方法进行挖掘,最后集成各个簇中的模式。
1 多数据库挖掘的相关研究
最早的多数据库挖掘算法是将多个数据库合并成一个大数据库,然后用传统的数据挖掘方法对这个大的数据库进行挖掘。但是由于目前的数据库集成技术不够成熟,在集成过程中会产生大量的冗余数据,结果有可能陷入组合爆炸的窘境,而且会生成大量无用的模式,同时丢失很多有用的模式。结合归纳逻辑编程的多数据库挖掘方法需要将每个实例都转换成一阶逻辑的形式,模式发现过程需要耗费相当的时间。采用数据选择的方法来减少总数据量,从多个数据库中选出与挖掘任务相关的数据,然后在这些数据上进行数据挖掘。这个方法是依赖于特定的数据挖掘任务的,对于不同的挖掘任务,需要的数据集不同,选择数据会耗费很多时间。而且,很多挖掘任务并没有详细的指明需要的数据集。由于各个数据库不是同构的,单独对每个数据库进行挖掘得到局部模式,再将局部模式集成为全局模式会丢失很多重要的模式。还有一种中间的方法就是先把数据库进行分类,然后对各个类中的数据库进行挖掘,最后把各个类中的模式进行集成得到全局模式。
2 AN-DBC算法
提出了一种数据库分类方法,用于事务数据库分类:把项集作为数据库的特征,两个数据库项集中相同项越多,则两个数据库的相似度越大,最后把相似系数最大的数据库放在同一个类中。在本节中,我们定义了一种新的数据库相似度(距离)度量,提出了基于聚类的数据库分类方法,对于包含任何数据类型的数据库都可以进行较好的分类。
2.1 相关定义
定义 1 假设 D1,D2,…,Dn是数据库集合 D中的 n个数据库,aDi1,aDi2,…,aDim是数据库 Di的m个属性。数据库Di与Dj之间的距离表示为:
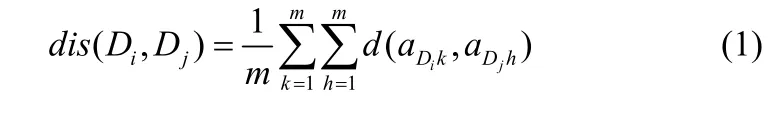
其中d(aDik,aDjh)表示的是属性 aDik与属性 aDjh之间的距离。
定义 2 假定 aDik与 aDjh分别为数据库 Di和数据库 Dj中的属性,aDik与aDjh的距离定义如下:
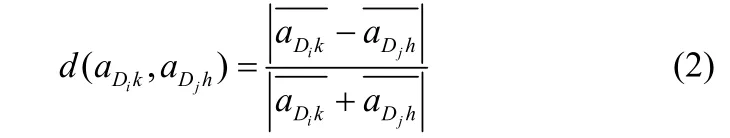
或
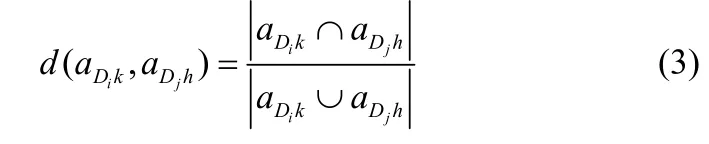
若aDik与aDjh均为数值属性,则用公式(2)表示,其中表示属性aDik的均值。若aDik与aDjh为概念属性,则用公式(3)表示。其中|·|是集合的秩。下面我们对d(aDik,aDjh)作以下说明:
(1)对于数值属性
(2)对于概念属性
由定义1和定义2我们可以推出以下结论:
结论3
2.2 AN-DBC算法描述
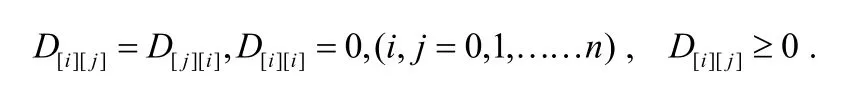
对于给定的一个数据库集合D1,D2,…,Dn,由上述定义的公式(1)可以计算出其中任意两个数据库Di和Dj之间的距离dis(Di,Dj),我们可以得到一个n行n列的矩阵D。很容易看出D满足如下条件:且数据库Di与Dj越相似,D[i][j]的值越接近 0,Di与 Dj差距越大,D[i][j]的值越大。因此D是一个单模的相异度矩阵,我们可以用聚类的方法把D中的数据库分成几个数据库簇。由于要聚类的对象是各个不同的数据库,这里选择的聚类方法是基于层次的聚类方法。
层次聚类方法将数据对象组成一颗聚类树。根据层次分解是自底向上的方式,还是以自顶向下的方式,层次聚类的方法可以分为凝聚层次聚类(Agglomerative Nesting)和分裂层次聚类(Divisive Analysis)。凝聚层次聚类算法的思想是这样的:首先把每个单独的对象作为一个原子簇,然后基于某个距离(或相似度)度量合并这些原子簇为更大的簇,如此迭代,直到最终所有的对象在一个簇中,或者满足某个终止条件。分裂层次聚类算法的思想刚好相反:首先将所有的对象放在同一个簇中,然后根据一定的条件逐步分解,形成越来越小的簇,直到每个对象自成一个簇或者满足某个终止条件。
本文设计了一种基于凝聚层次聚类的多数据库分解算法AN-DBC。算法描述如图1。其中簇之间的距离用平均距离来度量:
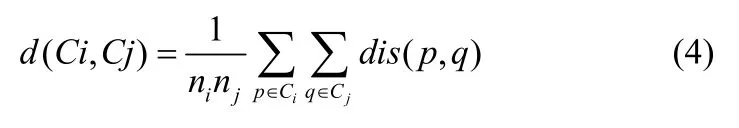

图1 AN-DBC算法
3 算法分析
在上述AN-DBC算法中,参数k表示的是最终分成的数据库簇的个数,是由用户输入的。下面我们先分析该算法的可行性。假定有 n个数据库 D1,D2,…,Dn,每个数据库Di有m个属性aDi1,aDi2,…,aDim,p条数据记录。如果用传统的方法,先把所有的数据库合并成一个数据库然后再进行挖掘,则算法的复杂度为o(pn+(n*m)2)。使用AN-DBC算法分类之后再挖掘,算法的复杂度为o(m2+n2),由此可见,我们的方法可以大大降低多数据库挖掘算法的复杂度。
4 下一步的工作与展望
在本文中我们介绍了一种基于聚类的数据库分类方法AN-DBC算法,用于对多数据库进行分类。实验证明该方法是正确的并且是可行的。对数据库进行分类之后,下一步的工作就是对各个类别的数据库进行挖掘,而最后也是非常关键的一步,是对各类数据库中的局部模式进行集成。选择怎样的集成方法跟分类有着非常紧密的联系,如何选择一种有效的集成方法将是我们下一步的工作。
[1] NingZhong.et al. “Peculiarity Oriented Multi-database Mining”.PKDD’99,LNAI1704.1999.
[2] Kaile Su. et al. “A logical framework for identifying quality knowledge from different data sources.” Decision Support Systems 42.2006.
[3] Xindong Wu. et al. “Database classification for multi-database mining”. Information System 30.2005.
[4] Ireneusz Czarnowski. “Prototype selection algorithms for distributed learing”.Pattern Recognition 43.2010.
[5] H.Liu,H.Lu,J.Yao.Identifying Relevant Database for Multidatabase Mining.In:Proceedings of Pacific-Asia Conference on Knowledge Discovery and Data Mining.1998.
[6] J.Yao and H.Liu,Searching Multiple Database for Interesting Complexes.In:Proc of PAKDD.1997.
[7] 张师超,张成奇.多数据库挖掘的研究.广西师范大学学报.2003.
[8] 唐懿芳,牛力,钟智,张成奇.多数据库挖掘中独立于应用的数据库分类研究.广西师范大学学报.2003.
[9] 尚世菊,董祥军,赵龙.多数据库中的负关联规则挖掘技术及发展趋势.计算机工程.2009.
[10] 路松峰,胡和平.多数据库开采中相关数据库的识别[J].计算机工程与应用.2000.
[11] 米捷,李可.对单数据库和多数据库中挖掘模式的评价[J].电脑知识与技术.2008.
[12] Jiawei Han,Micheline Kamber.数据挖掘概念与技术.机械工业出版社.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
铁道通信信号(2019年6期)2019-10-08
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
山东青年(2016年1期)2016-02-28
智能系统学报(2015年4期)2015-12-27
信息通信技术(2015年6期)2015-12-26
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
