
遗传算法—人工神经网络应用于城市污水量预测
2010-06-13 00:56饶世雄
山西建筑 2010年9期
饶世雄 明 丹
城市污水量的准确预测对于确定城市污水收集系统和污水厂规模有着重要的意义。城市污水量影响因素较多,各因素与污水量之间存在着高度的复杂性和非线性,故其预测模型一直是研究的难点。人工神经网络(Artificial Neural Network,简称ANN)作为非线性的动力系统,在解决该类预测问题上具有一定的优势,但传统的Backup Propagation(简称BP)人工神经网络模型存在收敛速度较慢、局部易出现极小点等缺点,为解决这些问题,提高神经网络模型精度,本文拟采用遗传算法(Genetic Algorithm,简称GA)来优化BP-ANN网络的权系和阈值,据此建立遗传算法人工神经网络预测模型,并用该模型预测武汉市武昌北区的城市污水量,以检验模型的适用性。
1 人工神经网络模型的构建
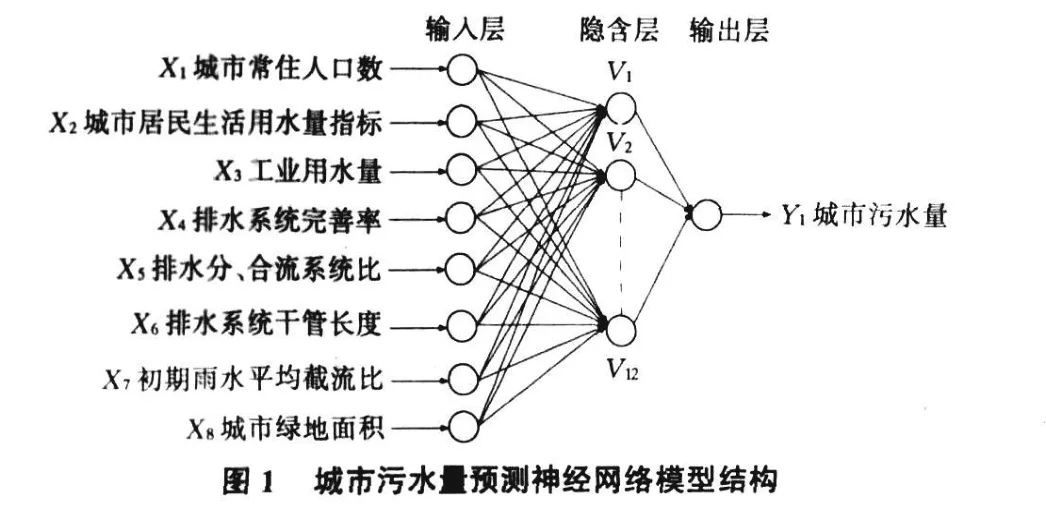
1.1 人工神经网络输入输出变量的选取
根据前人研究并综合影响城市污水量的各因素,同时考虑到BP-ANN模型的计算精度和速度,拟确定城区常住人口、城市居民生活用水量指标、工业用水量、排水系统完善率(排水管网覆盖区域与总区域的面积比)、排水系统分、合流系统比(分流制和合流制系统主干管不同管道过流断面面积与该管长度沉积的总和之比)、排水干管长度、初期雨水平均截流系数、城市绿地面积8个参数作为人工神经网络模型输入层的输入变量,将城市污水量(可采用日最高污水量或年污水总量来表示)作为输出层的输出量。采用时间移动法进行污水量预测,即当得出 t年的数据后,再预测 t+1年的污水量,依次类推[1,2]。
1.2 隐含层数和隐含单元数的确定
根据经验确定隐含层为1层,考虑到人工神经网络模型的精度和学习速度,经反复试验确定隐含层单元数为12个。人工神经网络模型结构见图1。
2 遗传算法改进的BP-ANN网络模型
2.1 步骤1:由遗传算法确定BP网络训练的最优权值和阈值
1)连接权编码。将人工神经网络的权系值按一定的顺序连为一个长串,串上的每一个位置对应着一个权重或阈值。则 L个权系值的m个个体串(即染色体)的集合可用 m行L列数组Wi表示,其元素aij是第i染色体的第j个变量[2-4]。针对参加训练的输入因子,按人工神经网络的常规方法生成网络的权重 Wi为:
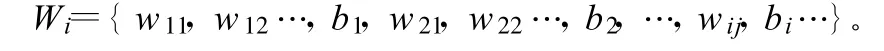
其中,wij为神经元j到神经元i的连接权重;bi为神经元i的阈值。城市污水量预测人工神经网络模型的权重108个,阈值13个,个体串长度 L=108+13=121。
2)适应度函数。将每个染色体对应的权重和阈值分配到给定的人工神经网络结构中,以训练样本为输入输出,计算神经网络的输出与期望输出之间的平均绝对误差ΔEi,则染色体的适应度函数为[2-4]:

其中,yk(k=1,2,…,n)为网络的输出;ok(k=1,2,…,n)为输出层神经元的期望输出,即实际的城市污水量;μ为p组训练样本;ρμ为加权系数,其主要用来加大近期样本所起的作用,取ρμ=1/t,对预测年限内最近一年的数据t取1,最近两年的数据t取2,依次类推。
3)选择算子。对各染色体进行选择计算。
对染色体i的选择率为:

其中,fc为交叉前父代两个个体中适应度大者;¯f为种群平均适应度。第k个染色体中aki和第l个染色体进行交叉操作的过程如下:

其中,0<βj<1为随机获取的交叉操作系数;a′kj,a′lj均为交叉后的变量值。
5)变异计算。变异率pm的自适应调整公式为:
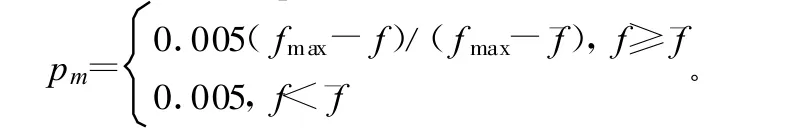
其中,f为需变异个体的适应度;¯f为种群平均适应度。
通过上述的遗传运算,得出BP人工神经网络误差最小的一组完整的初始权值和阈值。
2.2 步骤2:进行BP人工神经网络训练
1)将上述得到的初始权重和阈值输入BP网络进行前馈训练,得出计算样本的实际输出值和期望输出值的误差Δe(t)。后按正常训练原则调整网络的权值和阈值,再次进行前馈训练,得到Δe(t+1)。设 e=Δe(t+1)-Δe(t)为前后两次训练输出值与期望值的误差的差值。若Δe(t)>β(神经网络的训练精度)且e<Δ(预先设定的判断收敛速度缓慢性的指标),即认为 BP网络训练陷入局部极小值,则转入遗传算法。
2)按照各个权重变化范围本身的λ倍(人为确定)生成染色体群体。进行遗传计算方法如步骤1,得到最优权值和阈值。将此时得到最优权值和阈值代入BP网络再次进行计算,重复进行步骤2,直到全局误差小于预先设定的计算误差ε。
3 武汉市武昌北区城市污水量的预测
武汉市武昌北区区域面积约63.2 km2,2007年该区常住人口为71.5万人。现以该地区1979年~1994年的城区常住人口、城市居民生活用水量指标、工业用水量、排水系统完善率、排水系统分、合流系统比、排水干管长度、初期雨水平均截流系数、城市绿地面积、每年的日最高污水量、年污水总量等基础数据作为模型的训练样本以建立基于遗传算法的神经网络城市污水量预测模型的相关权重和阈值,用1995年~2007年该区的相应实测城市污水量数据对所建立的模型计算值进行检验,并通过该模型对该地区2010年,2015年,2020年,2025年等规划关键年的污水量进行预测。


训练模型主要参数为:初始权值取值范围(-1.0,1.0),初始阈值范围(-20,20),结构优化群体容量 n=120,最大进化代数为600,权重训练中的遗传算法的群体容量为n=60,最大进化代数为4000。训练完成后利用所得模型对1995年~2007年该区年日最高污水量及年污水总量进行计算,其计算值与实测值的对比如图2,图3所示。
另外,采用平均绝对误差 MAE,平均相对误差 MAPE,最大绝对误差 ME,最大相对误差 MRE等指标来评价图2和图3中计算值与实测值之间误差:

其中,yi分别为实测值和计算值;n为计算数据个数。经计算,日最高污水量的计算值与实测值的 MAE=0.88万t/d,MAPE=0.0196,ME=1.45万t/d,MRE=0.0307;年污水总量的计算值与实测值 MAE=311.37万t/年,MAPE=0.0216,ME=569.36万t/年,MRE=0.0395,因此计算值与实测值符合得较好,模型预测的精度较高,即该模型能较好的预测该地区实际的城市污水量。
运用该模型预测该地区2010年,2015年,2020年,2025年的城市污水量,结果如表1所示。

表1 2010年,2015年,2020年,2025年污水量预测值
4 结语
基于遗传算法的人工神经网络模型,通过交叉、变异等遗传运算能克服传统BP神经网络收敛速度慢、易陷入局部极小值的缺点,该模型能较准确地预测城市污水量,从而有助于确定合理的污水收集、处理工程规模。
[1]李杰星,章 云,符 曦.基于模糊神经网络的城市供水系统负荷预测[J].给水排水,1999,25(3):15-18.
[2]袁曾任.人工神经元网络及其应用[M].北京:清华大学出版社,1999.
[3]周 明,孙树栋.遗传算法原理及应用[M].北京:国防工业出版社,1999.
[4]王东亚,张 琳,赵国材.神经网络遗传算法在供热负荷预测中应用[J].辽宁工程技术大学学报,2005(40):161-163.
[5]P Kocalka,V Vojtek.Problem solving based on evolutionary neural network algorithms,Information Technology Interfaces,Proceedings of the 23rd International Conference on,2001:145-150.
猜你喜欢
云南化工(2021年6期)2021-12-21
空间科学学报(2020年4期)2020-04-22
电子制作(2019年10期)2019-06-17
测控技术(2018年9期)2018-11-25
智能城市(2018年8期)2018-07-06
现代园艺(2018年2期)2018-03-15
中国资源综合利用(2017年4期)2018-01-22
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
