
基于DSP的网络并行计算系统设计与实现*
2010-06-13 11:33卜祥飞柏正尧洪田荣李新庆
微处理机 2010年3期
卜祥飞,柏正尧,洪田荣,李新庆
(云南大学信息学院,昆明650091)
1 引言
为了处理日益复杂的实时计算问题,当今的通信系统采用了大量的高性能计算芯片,包括各种CPU,FPGA和DSP。对更高计算速度的需求促使人们相应地提高时钟频率,但是受到微电子技术发展速度的制约不可能无限制的提高时钟频率,于是人们开始使用多块DSP芯片并行处理高实时性数据。目前最常见的高性能硬件体系结构是基于总线的分布式多处理器,以其结构简单、成本相对较低、可靠性高的优点得到很多人的青睐。但是总线是系统的“瓶颈”,一旦系统总线出现故障,将使整个系统受到影响,而且在软件开发过程中难度较高。更重要要的是如果系统计算能力无法满足实际需求,硬件部分必须重新设计,成本较高,开发周期长。于是提出一种基于以太网主从模式的多DSP并行计算系统,用以太网作为传输媒介代替传统总线,采用UDP协议进行数据通信,其中主机移植了uclinux操作系统来进行全局任务调度,从机采用ADI公司提供的VDK实时操作系统内核进行数据计算。
2 并行计算
并行计算是一种用多台处理机联合求解问题的过程,其执行过程是将给定的问题首先分解成若干个尽量相互独立的子问题,然后使用多台计算机同时求解它,从而最终求得原问题的解。并行计算的提出是当今人们对快速处理大量复杂数据的迫切需求。首先,对于那些要求快速计算的应用问题,单处理机由于器件受物理速度的限制而无法满足要求,所以使用多台处理机联合求解就势在必行了;其次,对于那些大型复杂的科学工程计算问题,为了提高计算精度,往往需要加密计算网格,而细网格的计算也意味着大计算量,它通常需要在并行机上实现;最后,对于那些实时性要求很高的应用问题,传统的串行处理往往难以满足实时性的需要而必须在并行机上用并行算法求解。设计一个针对要求实时性较高的数据处理系统,它不依赖于传统的PC或多阵列DSP芯片作为处理器,而是使用可以灵活配置的单个DSP芯片组成一个以太网,在此基础之上采用UDP协议进行数据通信。通过实验测试表明,这样可以得到较高的实时数据处理能力。
3 系统开发
3.1 移植uclinux操作系统
uclinux的优点在于它的版权免费、源码开放、结构紧凑,这为日益增长的应用软件提供了坚实的基础。ucLinux是一个全功能的操作系统,支持完整的TCP/IP协议,网络编程易于实现,这对嵌入式系统来说是很重要的,因为它必须在任何时间任何地点进行计算。系统的服务器端是在BF548开发板上移植了uclinux操作系统,移植步骤如下:
(1)在装有 linux操作系统的 PC机下建立blackfin交叉编译环境
(2)移植u-boot
(3)移植uclinux操作系统
所有用到的源代码可以在 http://blackfin.uclinux.org上免费下载。移植成功后借助uclinux操作系统对socket和多线程编程良好的支持来实现复杂的任务调度。
3.2 VDK 编程
VDK(Visual DSP Kernel)是ADI公司DSP软件开发工具Visual DSP的一个重要组成部分,它特别适合用来编写需要精巧控制代码的应用程序。某些大型系统可能需要许多算法完成,而每个算法还可能包含许多功能模块,这就要由控制代码加以组织。处理器日益强大功能的发挥也需要精巧的控制代码。基于VDK开发的程序中,这些控制码是由一个叫“内核”的程序管理的,内核常驻在DSP中。VDK实际上是一种带API(Application Program Interface)函数库的实时操作系统内核,特别适合算法的实现,并且屏蔽了嵌入式系统开发过程中的一些硬件细节,在Visual DSP++开发平台下直接建立VDK/LwIP工程,利用VDK提供的一些socket API函数,实现了UDP客户端通信。
4 并行计算的实现
4.1 服务器端实现
服务器端软件运行在已经移植好uclinux操作系统的BF548 EZ-KIT评估板上,服务器端软件流程图如图1所示。首先创建一个socket套接字,使用bind函数进行绑定,在主函数中分别创建两个线程来完成服务器端数据的收发。线程函数recv_thread()负责接收客户端的数据,其中调用了socket API函数recvfrom()运行在阻塞模式下,等待接收各个客户端发送的测试字符串,同时存储客户端的地址信息。待所有客户端准备好之后,利用send_thread()函数向各个客户端发送数据,该发送过程中调用了sendto()函数。出于调试目的,当所有客户端的运算结果返回之后,在服务器端把得到的结果打印到终端上输出,之后再次把新数据发送给各个客户端。
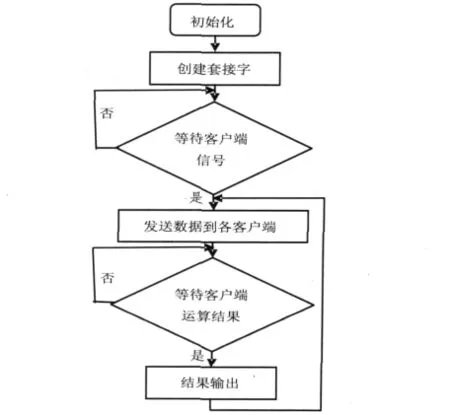
图1 服务器端软件流程图
4.2 客户端实现
客户端程序的编写采用了ADI公司提供的VDK+lwIP进行开发,采用这种方式进行开发主要是考虑到客户端软件复杂程度远远小于服务器端(主要用于运算),而且Visual DSP开发环境已经提供了一个完整的网络应用程序开发框架,无需手工编写大量底层代码。因为客户端的应用程序主要用于数据运算,过程相对简单,客户端软件流程图如图2所示。首先创建一个socket套接字,但无需进行绑定,创建套接字成功之后,向服务器端发送一个测试字符串,表示该客户端已经准备好接收数据,然后等待服务器端发送来的数据。待需要进行运算的数据接收完整之后开始进行数据运算,再把运算得到的结果发送给服务器端,再次进入等待接收服务器端数据状态。
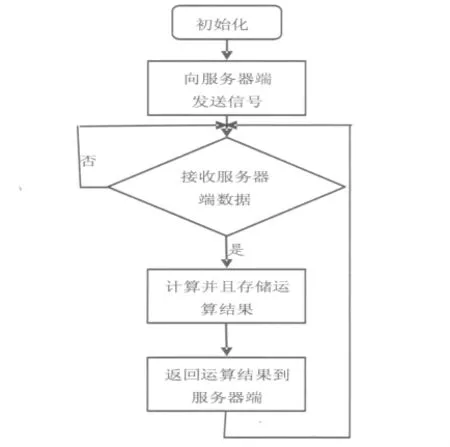
图2 客户端软件流程图
5 实验与结果
5.1 矩阵的乘法实现
为了验证这个并行计算系统的性能,设计了一个矩阵乘法运算试验。假设矩阵A、B、C均是n阶方阵,其中A被划分为n个n阶的子矩阵,A、B是将要进行乘法运算的初始矩阵,C存放运算结果,C在运算前为零矩阵。现在假设有Pn个客户端(n≥2),初始化进程后,各个客户端的存储器中存有划分好的子矩阵A和完整的矩阵B,用于存放局部运算结果的矩阵Ci(2≤i≤n)。然后利用各个客户端已有的数据进行局部矩阵运算并传输数据结果,最后将各客户端的子矩阵进行汇总,即得矩阵相乘的结果矩阵C。作为对比,又把矩阵相乘在单处理机上进行试验,即将A矩阵的一行和B矩阵的一列一一做串行运算。理论上来讲,除去通信开销外,并行计算矩阵乘法的速度应该是单处理机进行同一矩阵乘法的2倍(所有处理机的硬件配置相同)。
衡量一个并行计算系统的优劣主要有以下几点标准:各计算结点负载的均衡性,即应使各计算结点的计算量尽量相同;算法的效率(即计算结点计算能力的利用率)及加速比(即计算速度和计算结点数之间的关系),理想的情况是效率为100%,计算速度和计算结点数成正比关系;算法的容错性,即在系统中若干计算结点出故障,不会影响计算结果的正确性,好的算法应有强的容错性。有关参数定义如下:
加速比=单机计算时间/n个计算结点并行计算完成时间;
并行效率=加速比/n;
5.2 结果及分析
采用不同节点对1000×1000矩阵做乘法矩阵运算,由于网络延迟的不确定性,于是对同一结点数进行了5次矩阵运算,取平均值后得到的实验结果如表1所示。并行计算的运行时间取决于结点计算时间最长的那个。
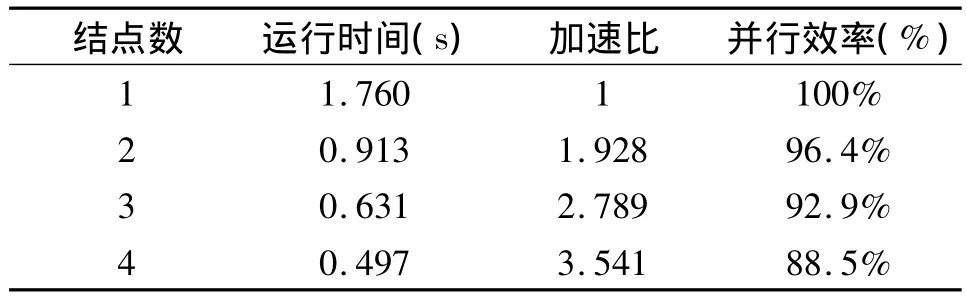
表1 不同计算结点的实验结果
客户端均采用相同的硬件结构,因此运算速度比较接近。通过表中的数据可知,与单个处理机的矩阵运算速度相比,多结点情况下的矩阵运算速度有明显提高。系统具有很好的可伸缩性,为解决大量实时性数据的处理速度问题提供了新的途径。
6 结束语
基于以太网的多DSP并行计算系统对大量实时性数据的运算速度有明显的提高,并且易于扩展。首先移植了uclinux操作系统,在此操作系统基础之上建立了以太网通信,并移植了并行算法到此操作系统进行试验,以矩阵相乘为例,得到了较好的处理结果。在下一步的研究工作中,将把并行算法的改进作为提高系统效率的重点。
[1]戴光明,戴晓明.基PVM的微机网络并行计算及其应用[J].计算机工程与应用,2000,25(4):154 -156.
[2]张新菊,刘羽,韩枭.行划分的矩阵相乘并行改进及其DSP实现[J].微计算机信息(嵌入式与 SOC),2008,24(7):216-218.
[3]朱美能,李德华,金良海,黄翔.基于多DSP的并行实时视频处理系统[J].计算机与数字工程,2007,35(8):41-44.
[4]Pierre G Paulin,Chuk Pilkington.Parallel programming models for a multiprocessor SoC platform applied to networking and Multimedia[J].IEEE Transactions on Very Large Scake Integration(VLSI)Systems,2008,33(7):667-680.
[5]ADI.Visual DSP++4.5 Kernel(VDK)User’s Guide[M].Analog Devices,Inc.April 2006.
猜你喜欢
河北农机(2020年10期)2020-12-14
数码世界(2020年11期)2020-11-23
广东第二师范学院学报(2020年3期)2020-06-28
北京航空航天大学学报(2017年12期)2017-04-23
网络空间安全(2016年11期)2017-02-13
电子技术与软件工程(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
电子制作(2016年1期)2016-11-07
文体用品与科技(2016年7期)2016-06-15
软件导刊(2015年6期)2015-06-24
