
支持向量机及其在邮件过滤中的应用
2010-06-13 11:32贾银山
微处理机 2010年3期
王 强,贾银山
(辽宁石油化工大学计算机与通信工程学院,抚顺113001)
1 引言
随着互联网的快速发展和普及,电子邮件以其方便、快捷等特点受到网民的青睐。与此同时垃圾邮件也在网络上大量传输,不仅占据了邮件服务器大量的存储空间和网络带宽,而且也带来了严重的社会问题。垃圾邮件泛滥造成的危害越来越严重,已经成为一个全球性问题。因此,研究反垃圾邮件的方法有着深远的社会意义和巨大的经济价值。
2 支持向量机的基本原理
支持向量机的基本思想是:首先把训练数据集非线性地映射到一个高维空间,这个非线性映射的目的是把在输入空间中的线性不可分数据集映射到高维特征空间后变为线性可分的数据集,随后在特征空间建立一个具有最大隔离距离的最优分类超平面,这也相当于在输入空间产生一个最优非线性决策边界。这里应该注意的是,在特征空间中支持向量机的分离超平面是最优的分离超平面。有很多个分类超平面都可以把两个类分离开,但是只有一个是最优的,就是图中的实线所表示的。它与两个类之间最近向量的距离最大。最优超平面可由被这个超平面错分和处在间隔带中的向量表示,如图1样本中的两个黑方块和几个黑圆,它们就是所说的支持向量,所以这种学习机叫支持向量机(SVM)。实际上SVM最吸引人的地方不是支持向量思想,而是结构风险最小化思想,也就是上述的最优分类超平面不但使学习机的经验风险很小,同时泛化误差也很小,即结构风险最小。
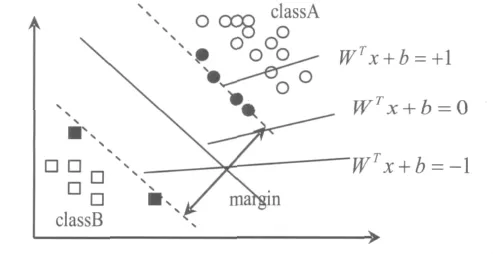
图1 最优分类超平面
2.1 线性支持向量分类机
假设有训练集 T={(x1y1),(x2y2),…,(xnyn)}∈(Xn,Yn)n表示一组训练样本,xi∈X=Rn,yi∈Y={1,-1},其中 yi= ±1 表示 xi属于类别A,yi=-1表示xi属于类别B,在线性可分的情况下就会有一个超平面使得这两个类样本完全分开。该超平面为:(w ”是向量点积。w是超平面的法线方向,w/‖w‖为位单位法向量。‖w‖是表示范数。在二维的两类线性可分情况下,有很多可能的线性分类器可以把这组数据分隔开,但是只有一个使两类的分类间隔最大,这个线性分类器就是最优分类超平面(如图1)。
引进松弛变量 ξi≥0,可得“松弛”了的条件:yi(w·xi+b)+ξi≥0,i=0,1,2…l,并把目标函数表示为:其中 C 为惩罚参数,ξi为松弛项。由此又把线性不可分问题转化为二次规划问题,如下表示:
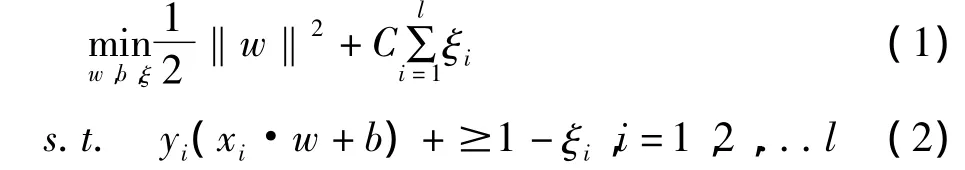
ξi≥0,i=1,2,...l,其中 C 为惩罚参数且 C >0。其对偶问题是:
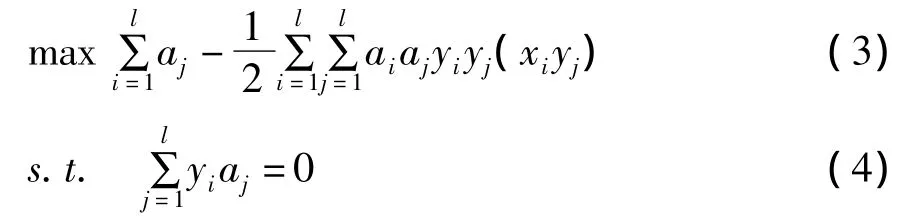
0≤ai≤C,i=1,...,l,此时引进 lagrange 函数[6]为:


2.2 核函数
核函数的引入有效地解决了在高维空间中复杂的计算问题,在解决非线性问题时K(.;.)起着直接的作用,在实际中甚至不需要知道具体的映射是什么,只要选定核函数 K(.;.)就足够了。由于不同的K(.;.)又可以产生不同的支持向量机,核函数K(.;.)的选择要满足Mercer条件。目前使用最多的核函数[6-7]如下。
(1)线性核函数

(2)多项式核函数
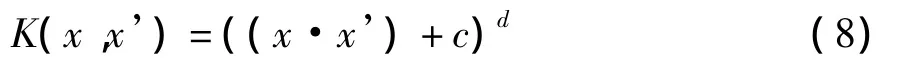
其中c≥0 是正定核,当c > 0 时,称为非奇次多x’)+c)d为奇次多项式核。
(3)高斯径向基函数
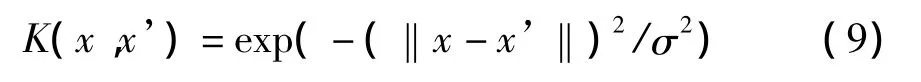
(4)Sigmiod核
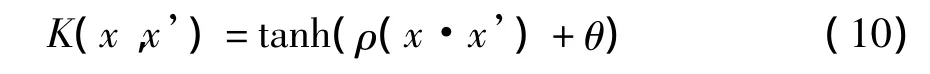
其中ρ是尺度值,θ为偏移值。支持向量机对立于感知机的第一层,lagrange乘子对应于感知机的权重。
3 电子邮件的预处理技术
3.1 邮件预处理
电子邮件也有自己的“信封”和“信文”,即邮件的首部和邮件的主体,是一种半结构化的文档。邮件的首部主要有收件人的电子邮箱地址、发信人的电子邮箱地址、传送邮件经过的路径以及信件标题等,其中主体部分就是邮件传送的内容。
首先对邮件抽取的主体内容进行分词处理。对于英文邮件而言,可以非常简单的实现分词,因为每个英文单词就是一个词组。对于中文邮件就必须进行分词处理。把中文的汉字序列切分成有意义的词,就是中文分词,也称之为切词。采用基于字典的字符串匹配的分词方法中的最大正向匹配算法进行中文分词。此方法能达到最好的分词效果。
3.2 邮件的向量化
为了能用支持向量机的方法处理邮件,就必须对邮件的内容进行处理。在机器学习与文本分类领域中,广泛采用向量空间模型来表示文本信息,文档被转换成具有高维空间的向量。用向量空间模型来表征电子邮件,这样邮件的内容就转化成高维向量空间中的一个点,对邮件内容的处理问题就转化成了向量的运算问题,实现了文档的可计算性和可操作性。
在此模型中,每个文档表示为一个特征向量V(d)=(T1,W1;T2,W2;…Tn,Wn)∈(T × W)n,其中Ti为词条项,通常为单字、词、词组、成语、短语等,词条项相当于邮件的特征。Wi表示词条项的权重,是该项在文档中的重要程度,反映文档的主题。由于Ti在训练和测试过程中其值固定不变,所以可以看成特征向量的下标,因此特征向量可以简化为V(d)=(W1,W2;…Wn),Wi采用如下的方法计算。TF -IDF公式[4]如下:

其中tfik为项Ti在文本Di中出现的次数,N为训练样本总数,nk为训练文本集中出现Ti的文本频数。
3.3 特征向量的降维处理
由于邮件文本的内容很多,词汇量很大,因此转化的向量空间的维数肯定很大,维数越大,相应分类的精确度也就会降低。学习算法的复杂度和时间也会增加,因此要对特征向量进行降维,也就是减少训练样本向量空间中特征项的数量。
一般先对文档中词条做禁用词处理,去掉一些没有实际意义的虚词,然后对文档的特征进行选择。采用评估函数的方法进行选择,评估函数对特征集中的每个特征进行评分,把分数大小进行排序,最后选取预定数目的最佳特征作为结果的特征子集。常用的评估函数很多,采用信息增益。其公式如下:
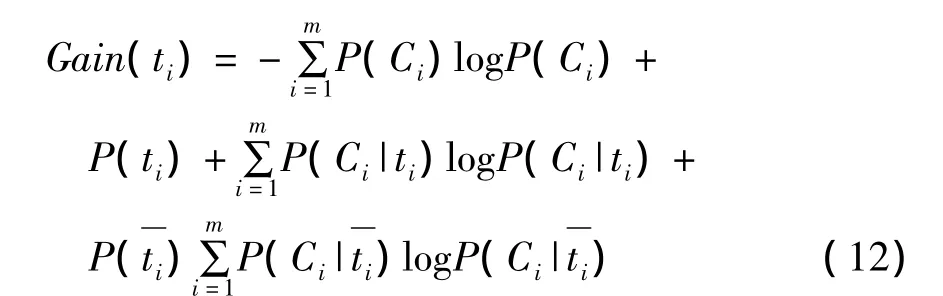
其中P(Ci)表示Ci类文档在训练集中的出现概率,P(ti)表示训练集中出现词条ti的文档概率,P(Ci|ti)表示包含词条ti的文档属于Ci类的条件概率,P(Ci︱ti)表示文档不包含词条ti时属于Ci类的条件概率,m表示类别数。最终只保留信息增益值最大的2000个特征项。
4 实验分析及结果
实验采用libsvm开源软件包,libsvm提供了四个核函数,在本实验中采用默认的径向基函数,惩罚参数C取10。对垃圾邮件过滤的性能评价通常借用文本分类的相关指标。设测试集合中共有N(N=a+b+c+d)封邮件:a表示在测试集中实际为垃圾邮件且被svm分类器判断为垃圾邮件的个数;b表示在测试集中实际为正常邮件(ham)且被svm分类器判断为垃圾邮件的个数;c表示在测试集中实际为垃圾邮件且被svm分类器判断为正常邮件的个数;d表示在测试集中实际为正常邮件且被svm分类器判断为正常邮件的个数。因此,实际垃圾数目为a+c,实际正常邮件为b+d,以下几个评价指标用来衡量垃圾邮件过滤系统的性能。
F1测试值:,实际上是查全率和正确率的综合指标。
实验采用的中文语料集是从ccert[8]网站下载的,从中选取了800封邮件,其中包括665封正常邮件,135封垃圾邮件。又从个人及同学的邮箱收集了300封邮件,其中包括200封正常邮件,100封垃圾邮件。这样总邮件为1100封,正常邮件为865封,垃圾邮件为235封。随机选取正常邮件500封,垃圾邮件140封作为训练集,剩余的365封正常邮件和95封垃圾邮件作为测试集,这样训练集和测试集没有交叉。支持向量机的方法与Bayse[5]方法和K-NN[5]方法实验数据效果比较如表1所示:

表1 试验结果指标值对比
可以看出支持向量机方法比Bayse方法和KNN方法性能要好,所以用支持向量机进行垃圾邮件过滤具有较好的效果,各项指标都达到93%以上,符合当前邮件过滤器的要求。
5 结束语
在分析支持向量机的基础之上,根据文本分类思想提出了基于SVM的垃圾邮件过滤方法,通过实验证明了该方法的可行性和高效性。同时也应注意到SVM方法的一些不足,如何根据具体问题选择适合的内积函数还没有理论依据,在核函数的选择问题上也没有很好的方法去指导针对具体问题的核函数选择,SVM对训练集和测试集的速度和规模的影响也是值得进一步研究的。
[1]Drucker H,Wu D,Vapnik V.Support Vector Machines for spam categorization[J].IEEE Transactions on Neural Networks,1999,10:1048 -1054.
[2]金展,范晶,陈峰,等.基于朴素贝叶斯和支持向量机的自适应垃圾短信过滤系统[J].计算机应用,2008,28(3):714-718.
[3]王祖辉,姜维.基于支持向量机的垃圾邮件过滤方法[J].计算机工程,2009,35(13):188 -189.
[4]秦谊,裴峥,杨霁琳.改进的一分类支持向量机的邮件过滤研究[J].计算机工程与应用,2009,45(20):151-153.
[5]张羽.基于支持向量机理论的垃圾邮件过滤模型[D].成都:电子科技大学,2006.
[6]邓乃扬,田英杰.数据挖掘中的新方法一一支持向量机[M].北京:科学出版社,2004.
[7]安金龙,王正欧.一种新的支持向量机多类分类方法[J].信息与控制,2004,6(3):262 -267.
[8]中国教育和科研网紧急响应组(CCERT)[Z].http://www.ccert.edu.cn/spam/sa/datasets.htm,2010,2.
猜你喜欢
英语文摘(2021年10期)2021-11-22
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
校园英语·月末(2021年13期)2021-03-15
潍坊学院学报(2020年2期)2021-01-18
计算机与网络(2020年4期)2020-04-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
数学物理学报(2019年1期)2019-03-21
重庆工商大学学报(自然科学版)(2018年3期)2018-05-11
