
基于数据挖掘的施工质量风险预测
2010-06-07 05:58:55黄如福
土木建筑工程信息技术 2010年4期
李 智 黄如福 黄 鹤
(1.中国建筑科学研究院建筑工程软件研究所,北京 100013;2.西安建筑科技大学信控学院,西安 710055)
基于数据挖掘的施工质量风险预测
李 智1黄如福1黄 鹤2
(1.中国建筑科学研究院建筑工程软件研究所,北京 100013;2.西安建筑科技大学信控学院,西安 710055)
质量管理是建设工程管理工作的重中之重,如何借助计算机工具协助建设工程质量监督检测单位,快捷、准确地完成质量管理工作是建设工程质量监督检测部门信息化的热点。本文通过对影响工程质量内外因素的分析,结合数据挖掘的理论,提出了将数据挖掘技术引入施工质量管理系统的思路,并在此基础上构造了施工质量风险预测系统的模型。最后,结合Weka软件的特点和优势,本文分析了将Weka软件与系统集成的可行性,并对Weka软件的预测效果进行了展示。
建设工程;质量管理;信息化;数据挖掘;风险预测;Weka
1 引言
随着行业范围内施工企业信息化的全面推行和计算机信息技术的发展,施工企业逐步建立起了集团级或企业级的数据库,积累了一定数量的施工数据。一些走在信息化前沿的企业,逐渐不满足于仅仅实现数据的储存和查询功能,越来越希望对现有数据进行分析和挖掘,进而产生对工程质量管理部门的决策分析提供辅助支持。
质量是人类文明进步的标志,随着全行业范围内对施工质量的日益关注,施工质量管理逐渐成为衡量一个施工企业管理水平的重要因素。传统的企业级质量管理模式仅仅停留在企业定期质量检查的方式,对于检查中发现的问题,也仅能做到发现一处,整改一处,没有连续性和针对性,造成质量检查过程中的重复劳动和效率低下。
为了克服施工过程中质量管理后知后觉的弊端,早在上个世纪90年代,欧美的一些学者就提出了利用建立模型对施工风险进行预测的理论。但由于施工情况复杂多变,给实际建模带来了很多的困难,也使预测模型的推广面临很大的障碍[1]。直到近几年数据挖掘的技术越来越成熟,利用数据挖掘工具建立的预测模型才重新走回人们的视野,成为研究的新热点。
本文通过对施工企业业已积累的建设工程项目数据进行分析,并使用数据挖掘的方法找寻与质量检查结果相关的信息,在此基础之上建立质量检查结果的预测模型,用以实现对质量风险的预测,建立施工企业的质量风险预测系统。利用此系统,工程质量监督检测人员可以在立项之初,根据建设工程项目已知信息预测项目施工质量检查结果,对预期风险较大的项目进行资源再调配,以期达到降低施工风险提高决策效率的目的。同时,质量风险预测系统分析产生的结果可作为立项可行性报告的依据,为领导决策层提供可靠的参考信息。
1 项目施工主要质量影响因素分析
建设工程施工质量有着严格的要求和标准。在所有影响工程质量的因素中,人、材料、机械和环境方面的因素是主要因素。如何对这些因素数据进行跟踪管理,并严格加以控制,是保证工程质量的关键。
(1)人的因素
人的因素是影响施工质量的最主要因素。主要包括领导者的素质,工程师的理论、技术水平,以及其他施工人员熟练程度和工作态度等。选择人员组织素质较高的施工队伍,对现有的人员进行组织优化,有针对性地实行培训和优选,进行专业岗位技术训练,对于提升质量管理水平起到至关重要的作用。因此,施工过程中人员的选择往往直接决定了施工质量风险的大小和最终质量验收的通过与否。
(2)材料因素
要创一流的工程质量,必须有高质量的材料加以保证。材料指原材料、成品半成品、构配件等,它是工程施工必要的物质条件。在实际施工过程中,因材料质量造成的安全事故时有发生,例如,一些“豆腐渣”工程,就是因为使用劣质建筑材料,最终造成重大事故,也给施工企业的声誉带来无法弥补的损失。所以,在施工的质量管理过程中,一定要加强材料质量的管理,严把材料质量关。同时要建立供应商材料信息库和信用考评机制,对所提供的材料进行跟踪,对供应商进行考评,最终达到控制材料质量的目的。
(3)机械设备因素
施工机械设备是实现施工机械化的重要物质基础,是现代化工程建设中必要的设施,对工程施工的进度和工程质量都有直接的影响。因此,机械设备的购置、管理、检查验收、安装质量以及运转情况等,是否符合技术要求和质量标准就显得十分必要。
(4)环境因素
在施工过程中,环境因素也并不是一成不变的,不同的工程项目会有着不同的工程技术环境、管理环境和劳动环境。而且同一个工程项目,在不同时间,环境因素也是变化的,如气象条件,温度、湿度、风雨等都是变化的,而这些变化都会对工程质量产生一定的影响。例如,在冬雨期、炎热季节或者风季施工时,尤其是混凝土工程、土石方工程、水下工程及高空作业等,容易受到冻害、干裂、冲刷等的危害而影响工程质量。由此可见,环境因素也是质量风险因素中不可或缺的一部分。
2 施工质量风险预测系统的构建
根据以上影响质量因素的分析,可以整理出构建施工质量风险预测系统的基本思路。即通过对相关因素的分析,找寻这些因素之间以及与质量检验结果的联系,最终实现通过已知因素预测质量风险的目的。
基于以上理念,可将企业级的施工质量风险预测系统划分为三个层次:数据层、模块层和界面层(如图1所示)。
数据层的核心功能是对数据进行提取和预处理。质量风险预测系统的数据主要来自施工企业数据库,但企业信息库中的信息纷繁复杂,并不是所有的信息都有助于对施工质量进行分析,所以首先要有数据提取和处理的过程,有关提取和处理的方式将会在下文中详细论述。这些影响质量的相关信息将会被分类汇入专用的风险决策数据库。以该库为基础,系统将创建模型库、方法库和知识库三个衍生数据库。模型库用来存放数据挖掘中建立的模型;方法库将对数据关联的方式、方法进行记录;而知识库则主要用来储存数据挖掘后产生的数据和规律。
模块层的核心是风险预测模块,另外还包括数据分析模块和决策支持模块。风险预测模块是整个系统的核心,主要功能基于风险决策数据库的信息,对项目实施的风险进行预测;数据分析模块的功能是对数据库中影响施工质量的信息进行分析,找出内在的关联性;决策支持模块是基于以上两个模块的分析结果,为领导决策层提供参考数据和决策支持。
界面层是提供人性化的操作界面,使不熟悉计算机和数据挖掘知识的人员,经过简单的培训,可以轻松地掌握本系统。
由图1可见,建立企业施工质量风险预测系统的首要任务是要进行数据的提取和处理,之后是建立预测专用的数据库。建立专用数据库的目的是提升系统预测效率,同时也避免了预测过程中对原数据库产生的影响。在完成必要的数据准备工作之后,接下来就可以通过数据挖掘工具找出这些因素与施工质量的关系。
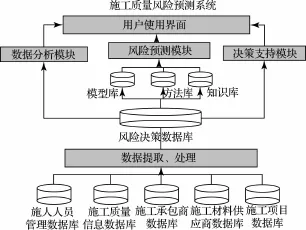
图1 施工质量风险预测系统功能模块图
3 数据挖掘工具介绍
目前,全世界有很多统计分析和数据挖掘软件,最著名的包括SAS的企业挖掘者和IBM的智能挖掘者,SPSS的CLEMENTINE,Megaputer的PolyAnalyst等。这些软件几乎覆盖了所有可能盈利的商业应用领域,使用的分析方法包括有回归、决策树、神经网络、聚类分析等等。但由于这些产品使用成本过高,操作复杂,对于一些处在数据挖掘起步阶段的企业来说未必是最好的选择。怀卡托智能分析环境Weka是一个基于java、用于数据挖掘和知识发现的开源项目,被公认是数据挖掘开源项目中最著名的一个。以其技术门槛很低和强大的数据挖掘功能而著称,可以完全胜任大中型施工企业的数据挖掘工作。对于广大施工企业来说,在质量预测系统中集成Weka软件,有以下几个明显的优势:
(1)免费。随着建筑行业信息化的不断深入,广大施工企业都投入了大笔的资金进行企业信息化建设。这在大力推进本企业信息化的同时,也给企业或部门带来或多或少的负担。由于质量风险预测系统在国内施工行业的实施尚无先例,使用免费的数据挖掘软件意为着可大比例减少对系统的投入,对该系统在行业内的快速推广极为有利。
(2)功能强大。虽然Weka是免费软件,但其强大的功能并不逊色于CLEMENTINE等商业数据挖掘软件。Weka里有非常全面的机器学习算法,包括数据预处理、分类、回归、聚类、关联规则等。其图形界面对不会写程序的人来说非常方便,甚至提供了“KnowledgeFlow”功能,允许将多个步骤组成一个工作流。
(3)开源。为了能够使不懂数据挖掘知识的人员能够无障碍使用质量预测系统,必须实现数据挖掘软件和系统之间的无缝连接。Weka作为开源软件,有着天然的兼容性和可拓展性。系统可较简单地实现软件的封装,将复杂的数据挖掘工作后台化,有助于没有学过数据挖掘知识操作人员也能够轻松地掌控系统。
4 质量风险预测流程
4.1 预测原理
通过之前对影响质量检验结果因素的分析,可以建立较为直观的数据关联表格(如表1)。表格中的每一行代表一个样本(WEKA中称作实例),表格的最后一列是目标属性(输出变量),也就是预测希望得到的结果。除了最后一列以外的其他列都作为样本的条件属性(输入变量)。对这些数据进行挖掘的目的就是根据一个样本的一组特征(输入变量),对目标进行预测,得到其目标属性(输出变量)。为了实现这一目的,需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的(如表1)。通过观察训练集中的实例,可以建立起预测的模型。有了这个模型,就可以新的输出未知的实例进行预测了。衡量模型的好坏就在于预测的准确程度。
4.2 数据准备
根据预测的原理,在进行数据挖掘之前需要进行数据准备工作,这项工作可以在预测系统中的数据提取、处理环节来完成。根据上一章节的分析,施工质量受人、材、机和环境因素的影响,数据提取的目的就是将施工信息数据库中影响质量的因素提取出来。例如,与人的因素相关的数据信息包括施工承包商、项目经理、技术负责人、质量工程师、施工队伍等;与材料因素相关的数据信息包含材料供应商、材料工程师、材料等;与机械设备相关的数据信息有机械设备供应商、设备型号、年限以及安全设备工程师、运营情况等;与环境因素密切相关的数据信息是施工月份、地点、地形、气候等。这些核心的数据信息被从企业数据库中提取出来,形成风险决策系统专用数据库。在此数据库中,建立核心信息与质量检查结果的关联,表1举例说明部分信息和最终施工质量检查结果的关系。
通过这样的信息归类,找出了影响质量检验结果的因素在数据库中对应的信息。系统将企业数据库中这些相关信息数据提取出来,就生成了专供预测使用的风险决策数据库。随后,在数据库中将这些相关数据与质量的检查结果相关联。将质量验收的最终结果(合格、不合格)作为目标属性,其他属性作为条件属性。根据表的属性生成决策树,再根据决策树和施工项目的详细信息实现对工程质量的预测。
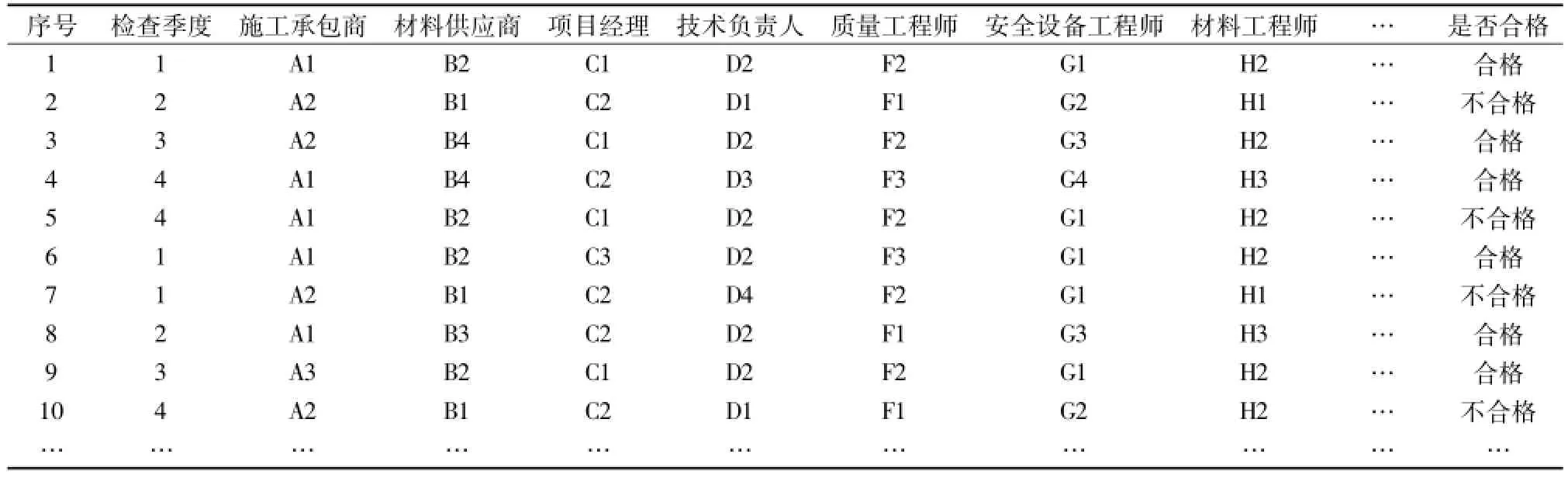
表1 施工质量检查因素关联表
4.3 预测模型和决策树算法介绍
生成决策树和预测模型是预测过程中最核心的步骤。决策树(Decision Tree)又称为判定树,是一种具有两个以上分支的流程图状树结构。决策树的每个内部结点就是一个决策属性,代表训练样本集中一个非类别属性的测试,且每个结点都与训练样本集的一个子集相关。每个分枝代表一个测试的输出结果。每个叶子结点用一个类属性来标记,代表某种条件下的一个多维数据集,也称为一个类或类分布网[2]。
决策树是一种直观而高效的模型。最常用的分类算法有CLS,ID3,C4.5,CART等算法。决策树算法一般包括两个阶段:构造树阶段和树剪枝阶段。在构造树阶段,通过对分类算法的递归调用,产生一棵完全生长的判定树。其通用算法可描述如下[2];
MakeDecisionTree(Training Damset T)
If(T满足某个中止条件)Then return;
For(i=1;i<=T中属性的个数;i++)
评估每个属性关于给定的属性选择度量的分裂特征:
找出最佳的测试属性并据此将T划分为T1和T2;
MakeDecisionTree(T1);
MakeDecisionTree(T2);
End If
算法的终止条件一般有三种情况:
①T中的所有训练样本都属于同一个类,则将此节点作为一个叶子节点,并以该类标记该节点:
②没有属性可以用做测试属性;
③训练样本的数量太少(少于用户提供的某个阈值)。
后两种情况通常以训练样本中占优势的类标记该叶子节点。属性选择度量有信息增益(information gain)(如ID3,C4.5等算法),Gini指数(如SLIQ,SPRINT算法),G-统计等。
通常情况下,一棵能够完美地分类训练样本集的决策树并不是一棵最精确的决策树,因为这样的一棵树对训练样本集过分敏感,而训练样本集无可避免的存在噪声和孤立点。树剪枝阶段的目的就是要剪去过分适应训练样本集的枝条。较为常见的剪枝算法主要有悲观错误率剪枝算法,最小描述长度(MDL)剪枝算法等。
本文采用c4.5算法,c4.5算法是对ID3算法的一种改进。能够处理描述性属性是连续型的情况。这种算法比较各个描述性属性的Gain值的大小,而后通过选择Gain值最大的属性进行分类。如果存在连续型的描述性属性,那么首先应该将这些连续型属性的值分成不同的区间,即“离散化”。
把连续型属性值“离散化”的具体方法是:
①寻找该连续型属性的最小值,并把它赋值给Min,寻找该连续型属性的最大值,并把它赋值给Max;
②设置区间【Min,Max】中的N个等分断点Ai,具体的确立方法是:
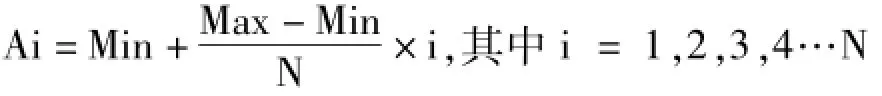
③分别计算把【Min,Ai】和【Ai,Max】(i=l,2,…,N)作为区间值时的Gain(A)=I(p,n)-E(A)值,并进行比较;
④选取Gain值最大的Ak作为该连续型属性的断点,把属性值设置为【Min,Ak】和【Ak,Max】两个区间值。
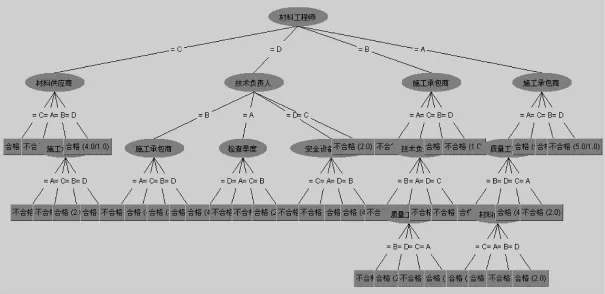
图2 施工质量风险预测决策树
C4.5算法使用信息增益的概念来构造决策树,其中每个分类的决定都与前面所选择的目标分类有关[3-4]。
WEKA里的J48决策树模型是对Quinlan的c4.5决策树算法的实现,并加入了比较好的剪枝过程,有非常好的精度[5]。因此,在Weka中选择“J48”的算法和十字交叉验证方法可生成决策树和预测模型。质量风险预测决策树生成的过程如下:
①系统从内部网各接触点收集施工质量信息,对数据信息进行合并,形成结构统一的施工质量信息数据源。
②对数据源进行数据预处理,去掉与决策无关的属性和高分支属性、将数值型属性进行概化以及处理含空缺值的属性,形成决策树的训练集。
③对上一阶段形成的训练集进行训练,对每个属性的信息增益和获取率进行计算,寻找获取率最大的但同时要保证信息增益不低于所有属性平均值的属性。将这些属性作为当前的主属性节点,并且为其每一个可能的取值构建一个分支。对该子结点所包含的样本子集递归地执行上述过程。如果得到的子集中数据记录在主属性上取值都相同,或没有属性可继续划分使用,则可生成初始的决策树。
④对上述的初始决策树进行树剪枝。一般采用后剪枝算法对初始决策树进行剪枝,并在此过程中使用悲观估计来补偿树生成时的乐观偏差。
⑤提取决策树的分类规则。对从根到树叶的每一条路径创建一个规则,形成规则集。
⑥当新项目产生时,根据施工项目的主要影响因素的信息,运用决策树进行分析,预测质量检查合格的概率,从而为项目管理决策提供辅助支持。
图2为是weka分析后,产生的分类决策树。每个节点代表一个表示一个判断条件,根据对该条件的判断结果分为若干子树,每一个叶子节点表示分类结果。从决策树根到决策树叶子节点的任意一条路径都对应着一个判断过程,越是接近树根的判断条件其优先级越高。
4.4 预测结果分析
模型生成后,可对其各项指标进行分析,当然考虑的最重要指标是模型预测的准确度。
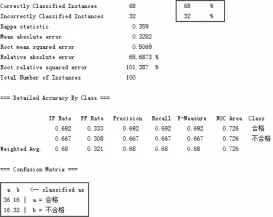
图3 施工质量风险预测决策模型参数
图3 上方的方框中给出了模型的准确度,此模型仅有68%左右。对原属性进行处理和修改算法的参数均可对模型的准确度进行调整,直到达到满意的准确度为止。图3下方的方框中该分析结果表示在决策树的矩阵之中,原本质量检查合格的样本中,有16个被误判为不合格;原本质量检查不合格的样本中,也有16个被误判为合格。这是对十字交叉验证方法准确性的补充说明。
4.5 质量风险预测
模型建立以后,可用来对质量风险进行分析和预测。搜集新建项目的相关数据导入数据库,此时项目质量检查的结果为未知条件,需对其进行预测(如表2所示)。当然不同模型有着不同的准确率。因此,适当调整模型各项参数,达到令人满意的准确度是提高风险预测效率的关键。

表2 施工质量风险预测表
结语
本文结合施工质量管理理论与数据挖掘技术提出了施工质量风险预测系统构建的思路,并对Weka软件与预测系统的集成的可行性做出论证。在文章的最后,对Weka的预测效果进行了分析。目前,国内的施工行业中,数据挖掘技术的应用还处于初级阶段,基于挖掘技术的预测系统更是寥寥无几。但相信随着施工企业数据的积累和领导决策需求的不断增长,数据挖掘技术势必成为未来施工企业信息化的新热点。
[1]Alaa Abdou,John Lewis,Sameera Alzarooni.Modelling Risl for Construction Cost Estimating and Forcasting.Building and Environment,2007.
[2]滕皓,赵国毅,韩保胜.改进决策树的研究叨.济南大学学报,2002,16(3):231-233.
[3]Quinlan,J.R.C4.5:Programs for Machine Learning[J].San Mateo,CA:Morgan IOufinann,1993.
[4]Ruggieri S.Efficient C4.5[J].IEEE Transactions on Knowledge and Data Engineering,2002,14(2):438-444.
[5]刘晓华.基于WEKA的数据挖掘技术在物流系统中的应用,科技情报开发与经济,2007(22).
Construction Quality Risk Prediction System Based on Data Mining
Li Zhi1,Huang Rufu1,Huang He2
(1.Institution of Building Engineering Software,China Academy of Building Research,Beijing 100013,China;2.The Information and Control Engineering School,Xi'an University of Architecture and Technology,Xi'an 710055,China)
Quality management plays a significant role in construction enterprises management.How to use computer to complete quality management accurately becomes a new hotspot for construction infomationization.This paper analyzed internal and external factors affecting the quality of the project.Combining data mining theory,this paper proposes construction quality risk prediction system.Finally,the feasibility and predicted effect of Weka were described.
Quality management;Infomationization;Data mining;Risk prediction;Weka
TU71;TP274
A
1674-7461(2010)04-0099-06
“十一五”国家科技支撑计划资助课题(2007BAF23B05)
李智(1981-),男,硕士。主要从事建筑行业信息化技术的研究与应用。E-mail:lizhi-fw@sohu.com
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电力与能源(2017年6期)2017-05-14 06:19:37
财经(2017年2期)2017-03-10 14:35:35
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
信息通信技术(2015年6期)2015-12-26 01:16:46
