
汉语块分析评测任务设计
2010-06-05 09:02:44李玉梅
中文信息学报 2010年1期
周 强,李玉梅
(清华大学 信息技术研究院 语音和语言技术中心,清华大学 信息科学与技术国家实验室,北京100084)
1 引言
有效的真实文本评测任务设计是提升自然语言处理技术的一个重要途径。英语方面的一个典型例子CoNLL设计的一系列共享分析任务,包括基本名词短语识别[1]、文本块分析[2]、子句识别[3]、命名实体识别[4-5]、语义角色标注[6-7]、依存分析、句法依存和语义角色一体化处理等,从简单到复杂,通过设计合适的分析任务,构建共享评测数据(Benchmark),吸引了国内外大量感兴趣的研究人员探索了各种机器学习模型在不同的分析任务中的应用方法,开发出一组可共享的英语文本句法语义分析工具。
在汉语方面,从2003年起,SigHan分别组织了三届汉语词语切分评测Bake-off,大大推动了相关研究技术的发展。2007~2008年,又与中国中文信息学会联合举办了第4届Bake-off评测[8],进一步增加了汉语词性标注和命名实体识别评测任务。但与英文相比,在句法语义分析层面上的评测任务则比较少。
受中国中文信息学会委托,从2008年10月起,清华大学和东北大学开始筹办中国中文信息学会句法评测CIPS-ParsEval-2009[9]。其主要目标是针对汉语描述特点,设计合适的评测任务,开发有效的评测数据集合。并以此为契机,推动国内汉语文本句法分析的研究水平。通过深入研究,我们提出了5项评测任务[9],包括:汉语词性标注(任务1)、基本块分析(任务2)、功能块分析(任务3)、事件描述小句识别(任务4)和句法树分析(任务5)。其中3项(任务2~4)涉及汉语文本的块分析问题。本文将对有关内容进行具体介绍和说明。
2 块分析任务设计
本次评测设计了以下3项块分析子任务:1)基本块分析; 2)功能块分析; 3)事件描述小句识别。其处理要点是对经过正确词语切分和词性标注处理的汉语句子自动分析形成不同层次的块标注序列。对每个子任务,都可以使用以下两种开发模式:1)封闭学习,即只使用训练数据习得相关分析模型; 2)开放学习:可以使用其他任何资源习得合适的分析模型。下面通过一个具体实例简要介绍这3个分析任务,有关详细标注格式和标记含义可参阅文献[9]。
原始输入:要/vM 使/vJY 这/rN 项/qN 工作/n 抓出/v 成果/n,/wP 首先/d 需要/v 这些/rN 部门/n 的/uJDE 主要/b 领导/n 以身作则/v 、 /wD 身先士卒/v 。/wE*相关词类标记简要说明:vM-助动词;vJY-兼语动词;rN-名代词;qN-名量词;n-名词;v-动词;wP-分隔点号;d-副词;uJDE-结构助词:的、之;b-区别词;wD-顿号;wE-结句点号。
基本块分析输出:[vp-SG 要/vM ] [vp-SG 使/vJY ] [mp-ZX 这/rN 项/qN ] [np-SG 工作/n ] [vp-PO 抓出/v 成果/n ],/wP [dp-SG 首先/d ] [vp-SG 需要/v ] [np-ZX 这些/rN 部门/n ] 的/uJDE [np-ZX 主要/b 领导/n ] [vp-SG 以身作则/v ] 、 /、 [vp-SG 身先士卒/v ] 。/。*相关基本块标记简要说明:vp-动词块;mp-数量块;np-名词块;dp-副词块;SG-单词语块;ZX-右角依存结构;PO-述宾关系结构。
功能块分析输出:[D 要/vM ] [P 使/vJY ] [J 这/rN 项/qN 工作/n ] [P 抓出/v 成果/n ],/wP [D 首先/d ] [P 需要/v ] [S 这些/rN 部门/n 的/uJDE 主要/b 领导/n ] [P 以身作则/v ] 、 /wD [P 身先士卒/v ] 。/wE
事件描述小句输出:[E2 要/vM 使/vJY 这/rN 项/qN 工作/n 抓出/v 成果/n ],/wP [E2 首先/d 需要/v 这些/rN 部门/n 的/uJDE 主要/b 领导/n 以身作则/v 、 /wD 身先士卒/v ] 。/wE
我们的块分析体系设计的基本理念是:块是句法语义信息的结合体,块内部的词语关联性是句法语义联系的桥梁。一个理想的块设计应该既能找到明确的句法判据,又可以形成合理的语义解释,达到形式和意义的完美结合。目前,基本块主要采用了内聚性判据,通过分析其内部词语组成的不同拓扑结构特点来判断是否成块;功能块和事件描述小句主要采用了外延性判据,通过分析它们在更大的事件句式和复杂句子中所处的功能位置及其与其他相邻成分的句法语义关系来判断是否成块。下面几节将对有关内容进行简要说明。
1) 基本块(Base Chunk, BC)
我们把基本块定义为单个或多个实词按照一定的关联关系组合形成的基本信息单元[11]。通过对基本块内部各种词汇关联关系的深入分析,我们提炼出了三种典型的拓扑结构:左角中心结构(LCC)、右角中心结构(RCC)和链式关联结构(CHC),它们覆盖了基本块内部的以下句法关联关系:1)修饰关系:覆盖体词块和谓词块RCC和CHC; 2)并列关系:覆盖体词块和谓词块CHC; 3)述宾、述补和附加关系:覆盖谓词块LCC。
这样,就形成了以下基本块内聚性判据:1)句子中的实词组合符合上面的一种拓扑结构,则形成一个多词语基本块; 2)句子中的其他独立出现的实词直接形成一个单词语基本块。对分析出的每个基本块,将给出“成分标记+关系标记”的双标记描述[11]。
2) 功能块(Functional Chunk, FC)
汉语功能块主要描述句子中反映不同事件内容的基本单元。确定依据主要是它们在事件描述小句的不同层次事件句式中所处的功能位置。目前主要考虑了以下两类事件句式:1)小句层面上的基本句式结构。据此,可以确定主、谓、状、宾、补等功能块。2)复杂名词短语层面上的句式结构变体。据此,确定定语块、中心块等功能块。
为了简化起见,在本次评测中,我们只考虑各个事件描述小句的事件骨架树中最低层次(即叶子节点)的功能块,将它们按照从左到右的顺序排列形成整个事件描述小句的功能块标注序列。
这样,就形成了以下功能块外延性判据:选择事件描述小句的事件骨架树中最低层次(即叶子节点)的词语组合形成各个功能块。对分析出的每个功能块,将分别使用以下10个功能标记来标注:主语块(S)、状语块(D)、述语块(P)、宾语块(O)、补语块(C)、兼语块(J)、定语块(A)、中心块(H)、独立块(T)和其他特殊块(X)。
3) 事件描述小句(Event Descriptive Clause, EDC)
我们以句号、问号和叹号等作为完整汉语句子的分隔符。在此基础上的事件描述小句确定主要依据了以下判定条件:1)以逗号、分号、句号、问号等点号分隔而形成的词语序列; 2)内部包含完整的主、状、谓、宾等事件句式,考虑到各种省略情况,其中至少应包含一个谓语块; 3)复句层面的状语和独立语成分可以作为一个特殊的EDC。它们共同形成EDC的外延性判据。
我们使用以下4个标记来标注不同的EDC:1) E1——包含主题信息的EDC;2)E2——主题信息省略的EDC;3) D1——复句层面的状语块;4) T——复句层面的独立语块。其中E1和E2组成了典型的事件描述小句。
3 评测数据库分析
以汉语句法树库TCT[10]作为统一的数据源,充分利用其中提供的丰富句法成分和关系标记信息,将上面设计的三种块的句法判据进行具体化和实例化,我们可以自动提取形成不同的块标注语料库,从而可以对这三个不同层次的块分析任务的处理难度进行初步估计。在下面的实验中,主要选择了TCT中所有的新闻类文本。其基本统计数据是:文件数185,汉字总数325 806,词语项总数207 372,句子总数8 137,平均长度为25.49词/句。
1) 基本块数据分析
从6个主要基本块的长度分布数据可以看出[11],真实文本句子中描述实体内容的名词基本块和描述动作状态的动词基本块占了大多数,达到单词语块总数的91%和多词语块总数77%,是我们研究的重点。相对而言,动词块的平均长度较短。在多词语块中,只包含两个词语的块占了93%以上;而在np多词语块中,包含两个词语的块只占了71%左右,约30%的名词块长度超过了3个词语。因此,基本名词块的内部描述复杂度更高,进行自动准确分析的难度也更大。
2) 功能块数据分析
表1列出了功能块长度分布数据。从中我们可以发现:
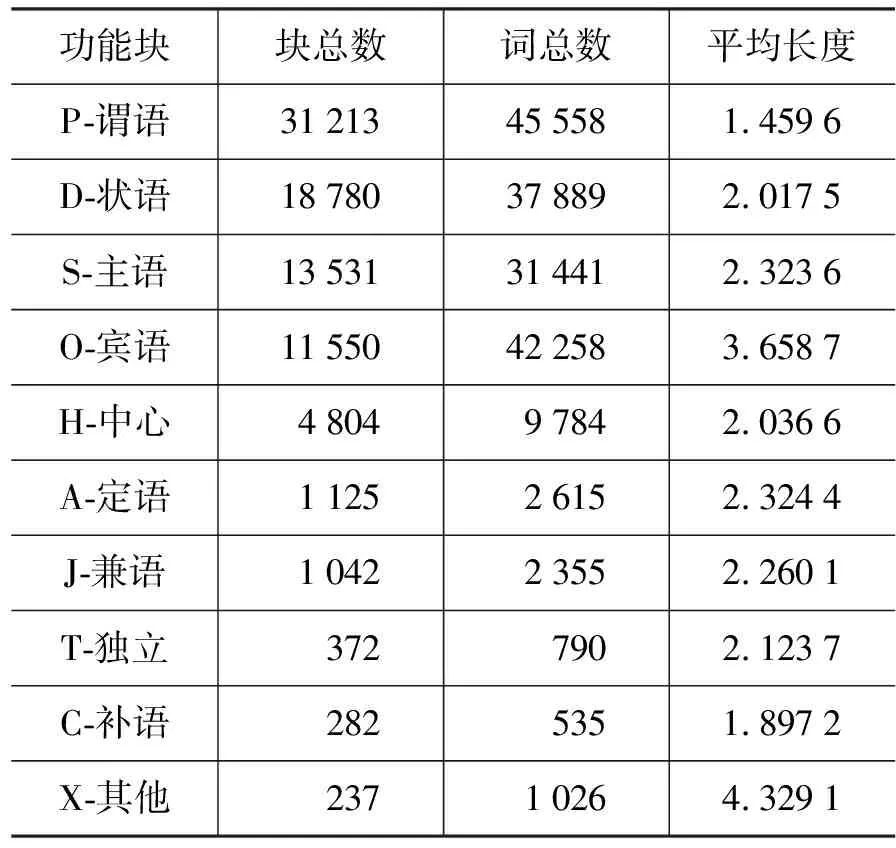
表1 功能块长度分布
• 真实文本句子中P、D、S、O块占了绝大多数,它们是形成事件句式的基本单元。其中的主要识别难点是复杂的宾语、状语和主语块。
• H和A块主要出现在定语从句中,其平均长度和分布特点基本与S块相当,但由于出现数量较少,再加上汉语典型歧义结构“V N 的 N”的影响,会导致统计学习模型训练不充分,从而增大识别难度。而H块由于前面一般有助词“的”,会更容易识别。
• 在剩余的4个非典型功能块中,J和C尽管出现频度较少,但由于语境特征明显,其识别难度应该与H块相当。而T和X则由于组合情况复杂和语境分布特征不明显,自动识别难度会很大,但由于其绝对数量很少,对整体性能的影响可以忽略。
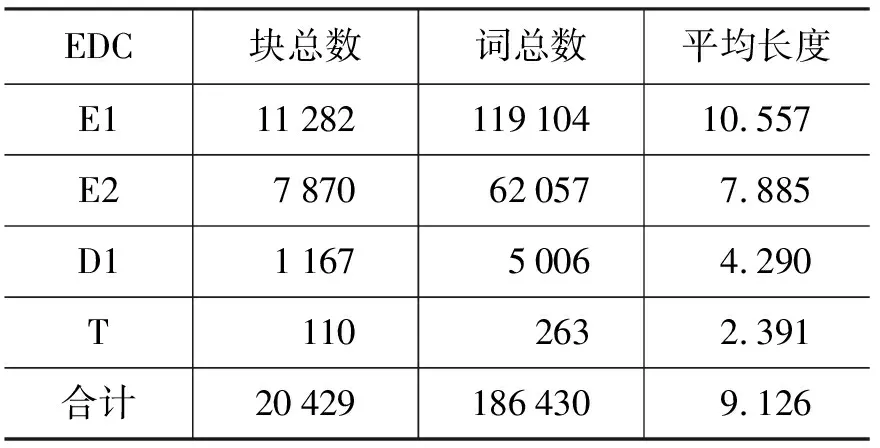
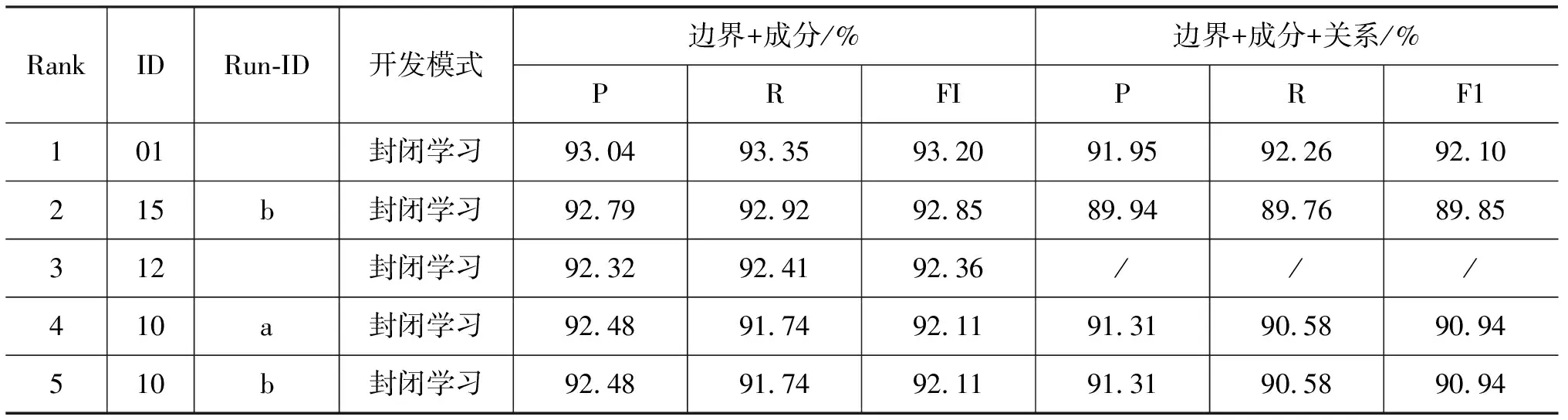
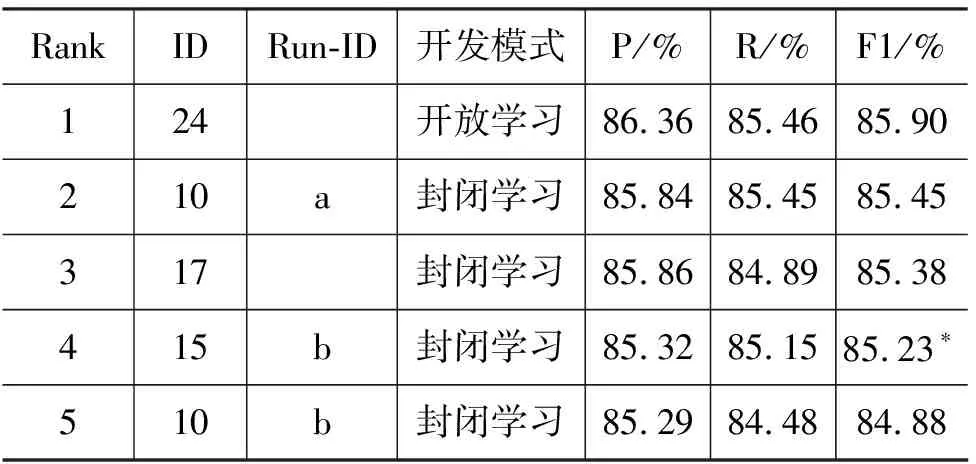
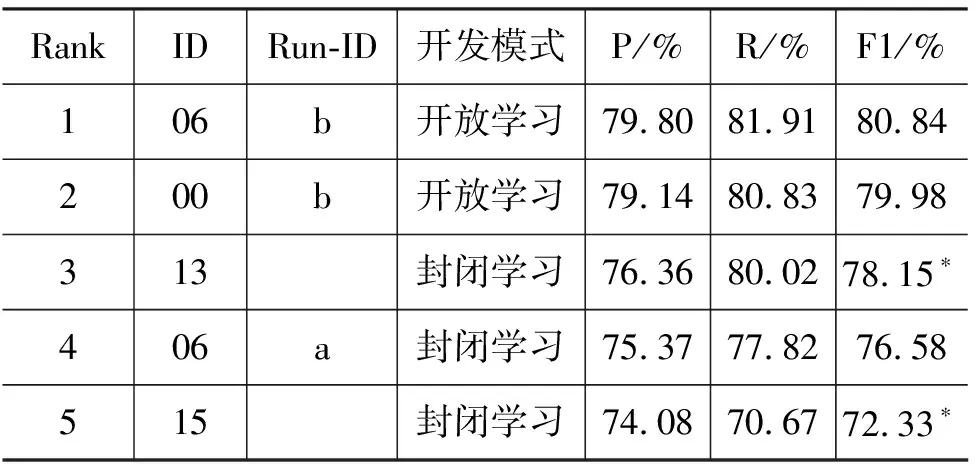
综上所述,在我们关注的8个功能块(PDSOHAJC)中,预期的识别难度排列会是:P, 简单D,S,O 3) 事件描述小句数据分析 表2列出了不同类型的事件描述小句的长度分布数据。 图1 不同长度EDC 所占比例分布 表2 事件描述小句长度分布 图1显示了其中不同长度EDC 的分布比例。从这些数据可以看出: • 汉语真实文本中包含完整事件内容的典型EDC块(E1+E2类)占了95%以上,是自动识别研究的主体。 • 典型EDC块的平均长度达到9个词以上,远高于功能块和基本块,并且长度大于10个词的EDC块比例超过了30%,长度大于20个词的EDC块比例也达到了6%,这就进一步加大了相关EDC块的识别难度。 • 点号作为事件描述小句的天然分隔符,应该可以在EDC识别中发挥重要作用。但汉语点号使用非常灵活,可用来分隔主、状、宾等功能块,可用来分隔各个功能块内部的并列成分,也可用来分隔复杂从句内部的各个小句,以上这些情况在我们目前的EDC划分原则下都应包含在某个EDC内部。对目前的2万多个EDC进行内部信息分析,发现包含 点号的EDC占块总数的16%,占覆盖词语总数的32%。这表明仅仅依靠点号信息来切分EDC会带来很大的副作用,需要引入更多有效的判别特征。 • 汉语事件描述小句内部的功能块组合非常复杂,包含多个谓语块的EDC比例达到了37%以上,其中包括复杂从句和连谓、兼语、并列等复杂谓语结构,它们会形成复杂的事件句式和事件骨架树。这些情况与灵活的点号使用习惯混杂在一起,对准确识别表征完整事件描述内容的EDC任务,提出了很大的挑战。 本次评测各个分析任务统一采用块分析准确率(P)、召回率(F)和F-1测度等评价指标。并针对不同层次的块分析任务,确定不同的正确性判据(详见文献[9])。从中分别选择“边界+成分标记”、“边界+功能标记”以及“边界”识别正确判据下的整体评价F-1值作为任务2、3、4的主要评价排序指标。 表3、表4和表5列出了参加三个块分析任务的性能最好的前5个系统的相应评测成绩。其中的ID列表示各个参评单位编号,Run-ID列显示了各个参评队伍提交的不同系统编号。 从中可以看出,在本次评测提供的完全相同的测试数据集上,Top-5基本块识别系统的整体F-1值(在“边界+成分+关系”正确性判据下)达到了90%~92%左右,而Top-5功能块识别系统的整体F-1值只达到了85%左右,两者相差了5%~7%。如何分析与挖掘对功能块识别更为重要的新特征,并把它们有机结合入不同的统计模型中,应该是下一步的研究重点。另外,使用更大规模的功能块标注语料是否会对性能提升有帮助,也值得深入研究。 表3 任务2的前5个系统的评测结果 表4 任务3的前5个系统的评测结果 表5 任务4的前5个系统的评测结果 最好的EDC识别系统的F-1值达到了80%左右(开放学习),其中使用了外部语义知识库和功能块分析器提供的功能块描述特征。完全使用EDC标注库信息的最好系统的F-1值为78%左右(封闭学习)。这表明了EDC识别问题的处理难度。如何发现与挖掘小句层面的描述特征,以提升EDC识别性能,将是今后研究的一个重要方向。 在基本块层面,英语方面的工作主要基于Abney(1991)提出的语块(Chunk)概念[18]。CoNLL-2000在《华尔街日报》语料库上进行的全面测试表明,在这个体系下建立的英语基本名词和动词块的识别性能达到93%左右[2]。在汉语方面的类似工作有清华大学[13]和哈尔滨工业大学[14]的基本短语描述体系和微软的块描述体系[15]等。这些体系的共同点在于它们都是从句法层面上来定义和描述块信息,主要侧重块边界确定和句法成分标注问题,不太关心各个块的内部关系分析。另一类相关的研究则关注类似基本块的实词组合的整体语义表现和内部组合关系,典型的工作包括命名实体定义和识别[4-5]、多词表达的内部词汇语义组合性评估问题[12]等。 而我们提出的基本块描述体系则以语义中心驱动的典型拓扑结构分析为基本判据,将以上两部分的工作有机结合起来,达到了基本块形式和意义的初步融合。另外,还首次将紧密结合的述宾结构关系纳入基本块描述体系中,使之基本覆盖了汉语中所有实词之间的重要词汇关联关系,为在此层面上进行汉语词汇关系的自动获取研究打下了很好的基础。 在功能块层面,英语方面的研究主要集中在语义角色标注(SRL)方面,通过对句子进行浅层语义分析,确定各个目标动词控制的核心语义角色的准确边界,在语义层面上直接完成事件框架的分析识别。目前在英语Propbank测试库上的最好系统的SRL性能F值达到了80%左右[7],近几年也没有很大性能提升[19]。对实验结果的深入分析发现,其中的主要问题出在论元成分识别阶段:在81%边界识别正确的论元成分中,95%以上都可以准确标注上合适的语义角色[7]。而且核心角色和外围角色的识别性能差异明显(80% VS 60%),显示出一定的统计偏置性。 而我们的研究则侧重从句法层面先识别出进行可以充当论元成分的功能块以及相应的事件句式,从而抓住了SRL的核心问题。这个研究从最初的单层次功能块[16],到逐步细化的二层次功能块[17],到目前的覆盖所有基本事件描述小句的功能块,再配合以事件骨架树的准确分析,可以实现语义层面的SRL在句法层面上的有效模拟。 在事件描述小句层面,国内外的相关研究不是很多。CoNLL-2001曾提出一个英语子句识别任务[3],其目标是自动识别英语句子中的所有嵌套子句。考虑到这个问题的复杂性,他们把它拆分成三项子任务:子句起点识别、终点识别和完整嵌套结构识别。其中最困难的第三项子任务基本上与我们定义的事件描述小句识别任务相当,只是我们只处理最上层的EDC。当时最好系统的开放测试F1值为78.63%[3],后来,通过改进算法,将分析性能提高到了80.44%[20]。 英语子句一般由先行词引导,具有比较明显的形式标记,这是设计嵌套子句识别任务的描述基础。而汉语各个从句之间一般没有特别的形式标记,因此我们选择以点号分隔的EDC作为识别重点,可能更适合汉语的描述特点。 本文针对汉语的描述特点,提出了三项汉语块分析评测任务:基本块分析,功能块分析和事件描述小句识别。基于真实文本标注库的数据统计分析和国内外相关体系的对比分析研究显示,这套块分析评测任务设计具有以下特点:1)在基本块层面,以语义中心驱动的拓扑结构分析作为基本块的主要判据,并加入紧密结合的述宾关系描述,使之基本覆盖了汉语中所有实词之间的重要词汇关联关系; 2)在功能块层面,选择不同层次事件句式中的各个最小描述单元作为处理对象,最大限度地保留了句子中各个不同层面的事件描述信息,形成了进行事件骨架树分析的研究基础; 3)在事件描述小句层面,以点号分隔的完整事件单元识别作为突破口,可以形成进行汉语“句→段”意合分析的中枢桥梁。 从目前的评测结果看,这三项块分析任务的识别难度为:基本块<功能块<事件描述小句。在此基础上,下一步的研究方向是:1)利用基本块和功能块的信息互补特点,通过适当的融合处理,获取信息更完整的功能块(功能标记+成分标记+中心词位置),以此作为事件骨架树分析的叶子节点;2)探索有效的事件骨架树分析方法,准确识别句子中由功能块组合形成的不同层次的事件句式,补充“功能块→事件描述小句”之间的事件信息描述空白。 [1] Introduction to CoNLL-1999 Shared Task: NP braketing [OL].http://www.cnts.ua.ac.be/conll99/. [2] Erik F. Tjong Kim Sang and Sabine Buchholz. Introduction to CoNLL-2000 Shared Task: Chunking [C]//Proceedings of CoNLL-2000 and LLL-2000. Lisbon, Portugal, 2000: 127-132. [3] Sang T K and D jean H. Introduction to the CoNLL-2001 Shared Task: Clause Identification [C]//Proc. of CoNLL-2001, Toulouse, France, 2001: p53-57. [4] Erik F. Tjong Kim Sang Introduction to the CoNLL-2002 Shared Task: Language Independent Named Entity Recognition[C]//Proc. of CoNLL-2002,2002. [5] Erik F. Tjong Kim Sang & Fien De Meulder Introduction to the CoNLL-2003 Shared Task: Language Independent Named Entity Recognition[C]//Proc. of CoNLL-2003,2003. [6] Carreras, X. and M`arquez, L. Introduction to the conll-2004 shared tasks: Semantic role labeling [C]//Proc. of CoNLL-2004,2004. [7] Carreras X. and M`arquez, L. Introduction to the conll-2005 shared tasks: Semantic role labeling [C]//Proc. of CoNLL-2005,2005. [8] Guangjin Jin, Xiao Chen The Fourth International Chinese Language Processing Bakeoff: Chinese Word Segmentation, Named Entity Recognition and Chinese POS Tagging [C]//Proc. of Sixth SIGHAN Workshop on Chinese Language Processing,2008. [9] 中文信息学会句法分析评测CIPS-ParsEval-2009介绍[OL]. http://www.ncmmsc.org/CIPS-ParsEval-2009/. [10] 周强. 汉语句法树库标注体系 [J]. 中文信息学报,2004, 18(4): 1-8. [11] 周强. 汉语基本块描述体系[J]. 中文信息学报,2007,21(3): 21-27. [12] Ivan A. Sag, Timothy Baldwin, Francis Bond, Ann Copestake, and Dan Flickinger Multiword Expressions: A Pain in the Neck for NLP [C]//Proc. Third International Conference of Computational Linguistics and Intelligent Text Processing (CICLing 2002), Mexico City, Mexico, February 17-23, 2002. [13] 张昱琪,周强. 汉语基本短语的自动识别 [J]. 中文信息学报,2002,16(6): 1-8. [14] Tiejun Zhao, Muyun Yang et al. Statistics Based Hybrid Approach to Chinese Base Phrase Identification [C]//Proc. of the Second Chinese Language Processing. ACL 2000, Hong Kong,2000. [15] Li, H., C. N. Huang, J. Gao, and X. Fan Chinese Chunking with Another Type of Spec [C]//Proceedings of the 3rd ACL SIGHAN Workshop, Barcelona, Spain, 2004: 41-48. [16] 周强,赵颖泽. 汉语功能块自动分析 [J]. 中文信息学报,2007,21(5): 18-27. [17] 陈亿,周强,宇航分层次的汉语功能块描述库构建分析 [J]. 中文信息学报, 2008,22(3): 24-31. [18] Steven Abney(1991). Parsing by Chunks [C]//Robert Berwick, Steven Abney and Carol Tenny (eds.) Principle-Based Parsing, Kluwer Academic Publishers. [19] L. Marquez, X. Carreras, K.C. Litkowski, and S. Stevenson. Semantic Role Labeling: An Introduction to the Special Issue[J]. Computational Linguistics, 2008,34(2): 145-159. [20] Xavier Carreras1, Lluis Marquez, et. al. Learning and Inference for Clause Identification [C]//Proc. of ECML'02, 2002.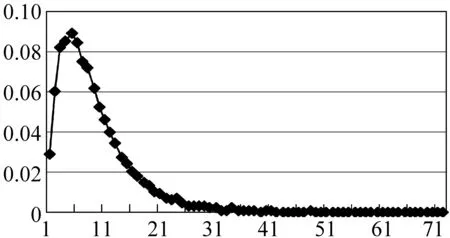
4 评测结果分析
5 相关研究工作评述
6 总结与展望
猜你喜欢
小型微型计算机系统(2022年5期)2022-05-10 08:45:42
家庭影院技术(2021年2期)2021-03-29 07:19:02
家庭影院技术(2021年1期)2021-03-19 05:14:58
计算机工程(2021年3期)2021-03-18 08:03:34
计算机与现代化(2020年8期)2020-08-17 13:59:50
中国自行车(2018年11期)2018-12-03 08:20:30
科技与创新(2017年14期)2017-08-09 15:16:16
中国自行车(2017年1期)2017-04-16 02:54:06
中国氯碱(2015年9期)2015-11-02 01:03:41
化工自动化及仪表(2015年7期)2015-01-13 04:24:26
