
Kad网络节点资源探测分析
2010-06-05 07:07:20刘祥涛龚才春
中文信息学报 2010年6期
刘祥涛,龚才春,刘 悦,白 硕
(1. 中国科学院计算技术研究所,北京 100190; 2. 中国科学院研究生院,北京 100190; 3. 北京市计算中心,北京 100005)
1 引言
eMule网络[1]是一种混合类型的文件共享对等网络,它由两部分:集中式网络和纯分布式网络组成。其中纯分布式网络采用了Kademlia协议[2],是eMule网络的主要组成部分。一般来说,采用Kademlia协议的eMule网络称为Kad网络。Ipoque 2008~2009年度的因特网流量报告表明:依地理位置的不同,eMule占P2P流量的2%~47%,占因特网流量1%~26%[3],且呈上涨趋势[4-5]。
Kad网络为不健康内容的传播提供了方便,在Kad网络中存在数百万的共享资源,其中有相当一部分不合适让特定人群观看,我们称这些资源为敏感资源。所以对Kad网络中的共享资源进行探测分析是相当必要的,这样不仅可以了解敏感资源的扩散程度,也可以为不健康内容的过滤做好铺垫工作。从而减少特定人群受不健康内容侵蚀的影响,有助于社会精神文明建设。
Kad网络的探测分析存在如下挑战:
• 虽然对等网络爬虫研究已经取得了较大进展[6,9-11],但直到现在,也不存在一个可以探测“节点”即被指定了一定标识的物理机器的共享资源的爬虫;
• 节点资源名是多语言的,比如英语、中文、日语、韩语、法语、西班牙语等,给资源的敏感判别增加了难度;
• 节点资源名通常都较短,从而其特征往往不足以判定其是否为敏感资源。
针对上述挑战:
• 在已有对等网络爬虫的工作基础上,设计和实现可以采集节点资源的爬虫;
• 本文只对中文、英语和其他易判资源进行敏感判别和统计分析,但是分析方法也适用于其他语言;
• 采用两种增加文件名特征的方法。a)file-content-hash是通过哈希文件内容获得的128位标识符。一个file-content-hash可能对应多个文件名,本文称为“FCH1N现象”。我们将对应同一个file-content-hash的多个文件名集中起来加强文件名特征。b)通过在流行搜索引擎上输入文件名中包含的关键词,获得更多信息以加强文件名特征。
本文后续章节安排如下,第2节介绍研究背景,第3节介绍相关工作,第4节对节点资源进行探测和统计分析。最后,我们在第5节对全文进行总结。
2 背景
节点资源名是多语言的且长度较短,导致对其进行敏感判别的难度,见表1。为提高敏感判别的准确性,本文适当简化问题和进行特征扩展(详见4.4.1节)。

表1 文件名的复杂性
为降低问题的复杂性,本文只对英文或中文简体可识别文件名进行敏感判别。同时将文件分为3个类别:敏感文件、正常文件、忽略文件,分别简称C1、C2和C3类文件。
定义1.敏感文件(C1类文件):其内容不合适让特定人群浏览的文件。
比如:文件名为“风骚的女子_俄罗斯.rar”的文件是敏感文件。又比如:“Water Melons cd1 .www.EMuleX.es.avi”单从文件名看不出是否敏感,但通过搜索引擎查找相关信息可以获知是一个色情敏感电影。
定义2.正常文件(C2类文件):其内容合适让特定人群浏览的文件。
比如:“汉初军事史研究.pdf”是一个正常的电子书文件;“The Pointer Sisters - Automatic.mp3”是一个正常的音乐文件。
定义3. 忽略文件(C3类文件):因为文件名及其相关信息不足或因为语言差异以至不能正确区分某文件是否敏感或正常的文件。
比如:“?????.bmp”、“0094.gif”和“(Reggaeton)Tito Y Hector - Gata Salvaje.mp3”都是忽略文件。
3 相关工作
对等网络爬虫探测工作开展较早,2002年,Saroiu等人率先使用主动测量方法对当时最为流行的Gnutella和Napster进行了拓扑测量[6]。2005年,Stutzbach等人在前人的工作基础上改进了主动测量方法并开发出了快速分布式Gnutella拓扑采集器:Cruiser,证明了因为节点震荡(churn)和Crawler采集速度太慢可能导致错误的实验结论[7]。因此,使得提高Crawler的采集速度成为提高拓扑测量准确性的关键问题。2008年,王勇等人针对Gnutella网络设计了基于正反馈的分布式Gnutella拓扑采集器:D-Crawler,提出了度量采集器准确性、完整性的衡量指标,分析了Gnutella网络拓扑图的度等级分布特征、度频率分布特征以及小世界特性[10]。
Kademlia协议的实现有Kad网络和Bittorrent的DHT网络等。2006年Stutzbach等人针对Kad网络提出了计算查询性能的分析框架,并开发出了两个软件:kFetch和kLookup用于采集和计算Kad网络的查询性能[8]。2006年Stutzbach 等人对三个P2P网络:Gnutella、Kad网络和Bittorrent进行了测量分析,针对Kad网络,他们用Cruiser采集了两天的拓扑数据,然后对节点可用性进行了分析[9]。2007年Steiner等人设计了Kad网络采集器:Blizzard并进行了为期179天的Kad网络采集,获得了节点的地理分布、会话时间、节点可用性和生命周期等测度的测量结果[11-13]。2007年Falkner等人在PlanetLab实验条件下,对Bittorrent的一个客户端Azureus的DHT网络进行了测量[14]。
与节点资源分析相关的工作有对等网络垃圾过滤(P2P Spam Filtering)等,2005年,J.Liang等提出了一种垃圾过滤方法:首先下载共享音乐文件,若该文件是不可解码或者长度超出官方公布的文件长度±10%范围,则认为是垃圾文件[15]。D. Jia等将P2P垃圾文件分为四类,然后对垃圾文件的特征进行分析,最后提出确定每类垃圾文件的方法。他们的方法特点在于:不需要下载整个文件,只需要文件的相关信息(比如:文件大小)即可判断文件是否为垃圾文件[16]。2003年,D. Dutta等通过建立信誉系统,使节点可以评价彼此从而建立信誉系统以进一步检测垃圾文件,他们的方法也不需要下载整个文件,但是存在的信誉欺诈行为可能使这类方法失效[17]。
总之,之前针对实际存在的P2P网络的测量工作主要是对Gnutella和Kademlia协议网络展开的。针对Kad网络的测量也只是局限于节点可用性测量[9,11],获取的节点信息相当有限。而我们设计的Kad网络爬虫Rainbow可对节点进行TCP协议层次的探测,能获得节点更丰富的共享资源信息,本文在这基础上,首度对Kad网络的节点资源进行了相关统计分析。
4 Kad网络节点资源探测分析
4.1 节点资源探测分析框架
如图1所示,Kad网络节点资源统计分析框架由两个模块:数据采集模块、统计分析模块组成。
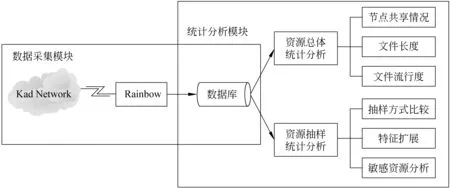
图1 Kad网络节点资源探测分析框架
1) 数据采集模块采用我们设计实现的Kad网络节点信息爬虫Rainbow进行数据采集,数据库使用SQL Server 2005;
2) 统计分析模块对数据库从两方面进行分析:a)资源总体统计分析:对采集数据的总体就资源的节点共享情况、文件长度和文件流行度等进行统计分析; b)资源抽样统计分析:抽样方式比较以确定最有代表性的抽样方式,特征扩展以更准确地进行人工标注,并从文件长度、共享用户数量、文件类型等方面对敏感文件和正常文件进行比较分析。
4.2 实验环境
本文设计并实现随机采集方式的Rainbow采集器,通过改造eMule客户端,模拟一个Kad网络正常节点,加入Kad网络,开始随机采集。进行如下三个阶段的操作:UDP节点采集阶段、TCP节点信息收集阶段和写数据库阶段。本文对Kad网络进行随机采集,即不固定k位前缀,只采集部分节点信息。其优点为:
• 采集的节点规模可调,典型值为4 000~100 000;
• 进行一次采集的时空复杂度较低,例如,对20 000节点进行一次资源探测耗时约45分钟(其中的TCP节点信息收集阶段因试图与20 000个节点建立TCP连接,为主要的耗时瓶颈,其耗时量约为40分钟);
• 采集随机目标节点,可知单次采集的节点比区域采集获得的样本节点更具有随机性,而且进行多次随机采集会比区域采集获得更多的记录条数。
限于篇幅,在此不再赘述,详情参见文献[18]。应用Rainbow在如下配置的机器上进行了数据采集。硬件环境:Intel双核2.8GHZ/内存2G/带宽2Mb/s ADSL PC一台;软件环境:Windows Server 2003 SP2,SQL Server 2005 Developer Edition。我们让Rainbow在2009年5月29日到2009年6月9日期间持续运行,共进行443次随机采集,为尽快获得节点资源信息,每次采集的节点数量阈值设为4 000,文件信息表共获得7 172 189条去重文件记录,后文简称这些文件为“总体”,且后文的分析主要对这个总体或者从中抽取样本进行统计分析。
4.3 资源总体统计分析
4.3.1 节点共享情况统计
表2对数据集的节点/文件数目进行了统计。由表2可见,UDP节点采集阶段采集的节点集合SUDP中只有65.09%的节点可以建立TCP连接,称这部分节点为Sonline。剩下的34.91%的节点可能位于防火墙或NAT (Network Address Translation)后,或者在试图与其建立TCP连接时已经离开Kad网络。
在和Sonline中的节点建立TCP连接后,向它们发送view_shared_files消息并等待TCP响应消息:view_shared_files_answer。由表2可见,Sonline中只有3.09%的节点会发回view_shared_files_answer消息且该消息中的“result count”字段大于0,在此,“result count”字段表示响应节点拥有的总文件数量;Sonline中其他节点会发回view shared files answer消息且其“result count”字段为0,或者发回view sharedfiles denied消息(表示不愿意告诉询问节点其共享文件情形),或者无任何响应消息。Rainbow采集器共收集了7 172 189条文件信息,包括文件的元信息,即文件名,文件内容哈希(File-content-Hash),文件大小,文件类型。

表2 采集节点与文件统计
4.3.2 文件长度统计
对总体的文件长度进行了统计。文件长度的中位数为4 597 982B(B为字节),即4.38MB,这正是流行音乐的文件尺寸,表示Kad网络中流行音乐占据了较大比例。最大文件长度为4 294 967 295字节,约为4G字节,正好是32位操作系统文件大小的最大值,我们发现总体中有12个文件具有这种尺寸,其中10个为iso光盘映像文件,2个为vido视频文件,说明共享的大文件一般是较大的光盘映像文件或DVD视频文件。最小文件长度为0Byte,我们发现总体中有5个此类文件,表示总体中存在无用资源。
4.3.3 文件流行度排名分布
文件流行度排名即将每个文件按照节点共享数量的大小进行排名,图2对总体的文件流行度进行统计,其中横轴表示文件,纵轴表示每个文件对应的共享用户数量,越接近原点的文件对应的共享用户数量越多,横纵轴为log-log坐标,可见文件流行度排名近似服从Zipf分布[18]:lgy(x)=lgC-αlgx,并求得α约为0.073 074,lgC约为3.681 060。

图2 文件流行度排名分布(log-log曲线)
4.4 资源抽样统计分析
4.4.1 抽样方式比较
抽样流行度Top1000文件,简称抽样方式1;抽样file-content-hash对应文件数量最多的Top100个文件,简称抽样方式2;不放回随机抽样100个文件,简称抽样方式3。
表3对三种抽样方式, 从文件类型和敏感类别方面进行了统计,其中文件类型的类别有video(视频)、audio(音频)、arc(存档)和other(其他)。比较表3的三种抽样方式的比例可见,三种抽样方式的统计结果存在较大差异。可见,用抽样方式1或2来进行敏感分类统计是不合适的。所以我们决定采取抽样方式3即不放回随机抽样方式获得样本,并在此基础上对敏感文件进行统计。
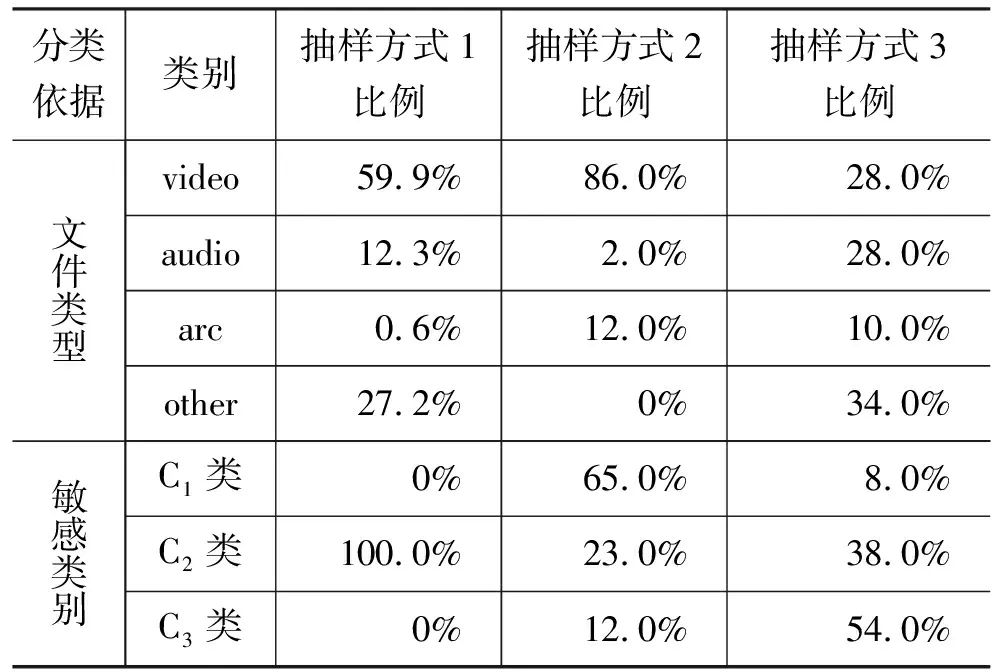
表3 三种抽样方式比较
4.4.2 资源特征扩展
eMule应用中,因文件名可以被用户更改,一个文件可能具有多个文件名,即FCH1N现象。如图3所示,我们采用抽样方式3即随机不放回抽样从eMule应用中抽取了31 490个文件,并对其文件与文件名的一对多关系进行了观察。我们观察到一个文件平均对应约8.94个文件名。
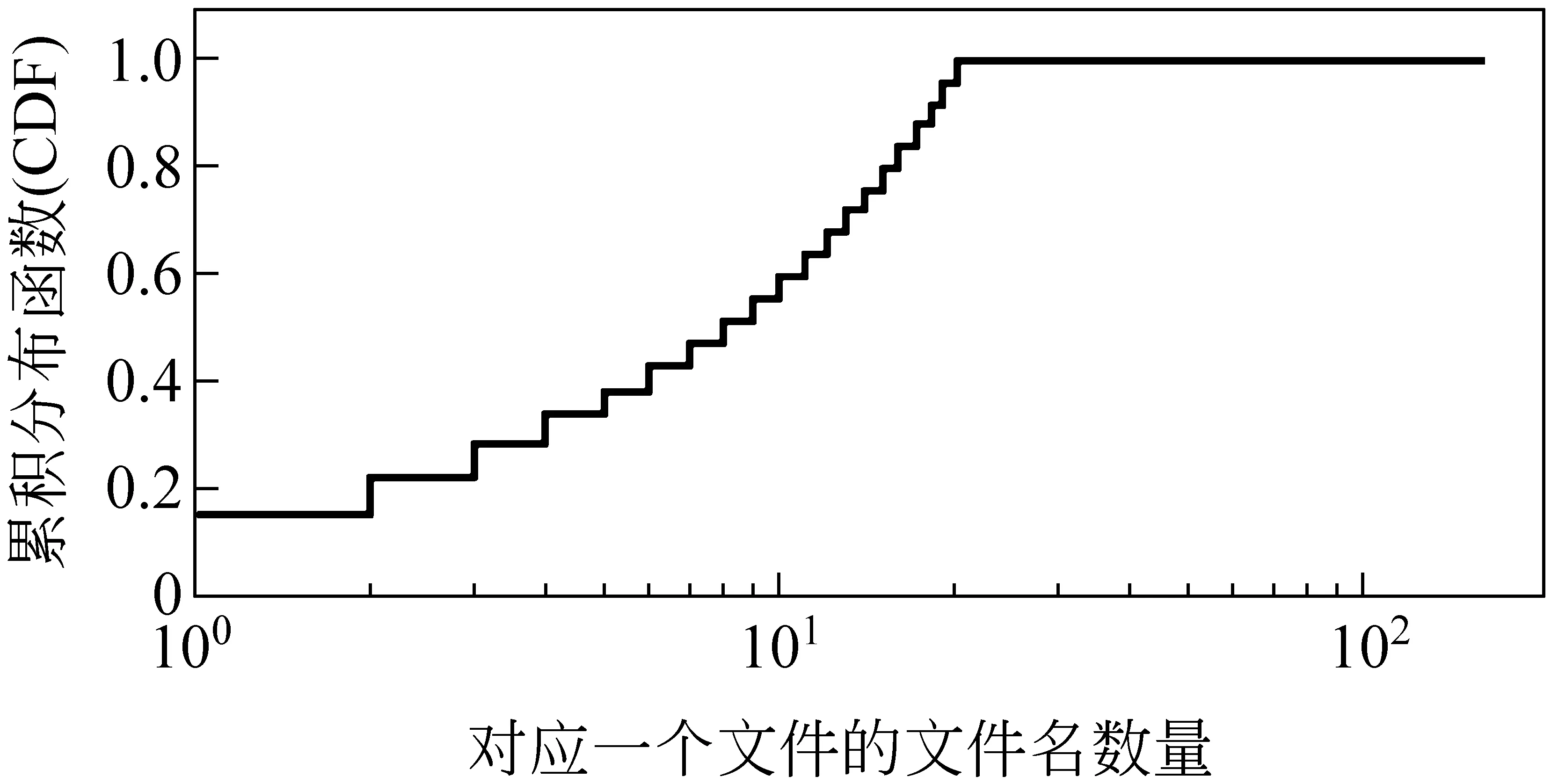
图3 FCH1N现象(log-线性坐标)
图4表示总体的文件名数量排名分布,其中横轴表示文件,纵轴表示每个文件对应的文件名数量,越接近原点的文件对应的文件名数量越多,横纵轴为log-log坐标。可见文件名数量排名近似服从Zipf分布,可求得α约为0.003 117,lgC约为2.281 033。

图4 文件名数量排名分布(log-log坐标)
同时,观察文件名规律得出如下规律:根据同一个file-content-hash对应的多个文件名的共现词或同义词,基本可以进行正确敏感判别。例如:file-content-hash ="DA61E48B2B9611DB4E628808C0E41474"的文件名有103个,其中“Share Accelerator”共出现了102次,根据这个特征(表示这个文件是个共享的加速器软件),可以将之标注为非敏感文件。又例如:见表4,file-content-hash=“6049E44451B7F262ACF094418EBA461C”的文件名有45个,其中lesbian和他的同根词lesbo等和同义词“女同”共出现19次。根据这个特征,可以将之人工标注为敏感文件。

表4 共现词共现次数统计
为充分利用这个特征来准确进行资源敏感判别,我们将同一个file-content-hash对应的文件名放到一起,利用共现词/同义词来进行人工标注。如果仍然无法利用共现词进行人工标注,通过在搜索引擎上查找共现词来获得更多信息以进行人工标注。
4.4.3 敏感资源统计
采用抽样方式3,对6 261个文件名进行了敏感判别,其中C1类有397个,占6.34%;C2类有2 226个,占35.55%;C3类有3 638个,占58.11%,由判别结果可见,虽然敏感文件所占的总体比例不高(6.34%),但由于eMule网络存在的文件数量极大,故敏感文件的绝对数量不容小视*据我们观察,55 238个节点即共享了7 172 189个文件,而eMule用户数量以百万计[11],因而eMule应用中的文件数量应该上亿,导致其中敏感文件的绝对数量应该数以百万计。。
敏感文件与正常文件在很多方面具有各自的特点,图5分别从文件长度(见图5(a)),共享用户数量(见图5(b))和文件类型(见图5(c)(d))等方面对敏感文件与正常文件进行了比较。从图5(a)可见,敏感文件比正常文件的平均大小大。具体而言,我们观察到敏感文件和正常文件的平均大小分别为353.54MB和134.67MB。从图5(b)可见,敏感文件比正常文件的共享用户数量多。具体而言,我们观察到敏感文件和正常文件的平均共享用户数量大小分别为5.06和2.82。由此可见,敏感文件更受eMule用户的欢迎。从图5(c)、(d)可见,虽然绝大部分敏感文件和正常文件的文件类型都是影音文件(即video和audio类型的文件),但是,敏感文件的主要类型为video文件(占74.8%),而正常文件的主要类型为audio文件(占38.6%)。由此可见,eMule用户倾向于共享影音文件,其中尤以较大的敏感video文件受到eMule用户的喜爱。

图5 敏感文件与正常文件在文件长度、共享用户数量和文件类型等方面的比较(图(a)、(b)为log-线性坐标)
5 结论
本文为了解Kad网络中资源分布规律,首先利用我们设计实现的节点信息爬虫Rainbow,对节点所拥有的文件资源在2009年5月29日到2009年6月9日期间进行了探测,获得了7 172 189条文件信息;然后对节点资源就如下方面进行了总体统计:节点资源情况、文件长度、文件流行度等;最后从采集数据总体中抽取较大样本进行敏感判别,并从文件长度、共享用户数量、文件类型等方面对敏感文件和正常文件进行了比较。实验分析结果表明,虽然敏感资源占共享资源的相对比率不大,但其绝对数量不容小视,故对敏感资源尤其是敏感视频文件的判别和监管是很有必要的。进一步的工作有:利用随机样本的敏感判别结果,形成训练集,采用机器学习方法对节点资源进行自动敏感判别。
[1] eMule. http://www.eMule-project.net, 2009.
[2] P.Maymounkov and D.Mazieres, Kademlia:A Peer-to-peer Information System Based on the XOR Metric[C]//International Workshop on Peer-to-Peer Systems, 2002.
[3] Ipoque,http://torrentfreak.com/bittorrent-still-king-of-p2p-traffic-090218/, 2009.
[4] Thomas Karagiannis, Andre Broido, Nevil Brownlee, Kc Claffy and Michalis Faloutsos, Is P2P dying or just hiding[C]//GlobeCom, 2004.
[5] Thomas Karagiannis, Andre Broido, Michalis Faloutsos and Kc Claffy, Transport Layer Identification of P2P Traffic[C]//Proc. Internet Measurement Conference(IMC), 2004.
[6] Saroiu S, Gummadi PK, Gribble SD., A measurement study of peer-to-peer file sharing systems[C]//Proc. of the Multimedia Computing and Networking(MMCN), 2002:156-170.
[7] D. Stutzbach, R. Rejaie and Sen S., Characterizing unstructured overlay Topologies in modern P2P file-sharing systems[C]//Proc. of the 5th ACM SIGCOMM Conf. on Internet Measurement, 2005.
[8] D. Stutzbach and R. Rejaie, Improving lookup performance over a widely-deployed DHT[C]//Proc. INFOCOM, 2006.
[9] D. Stutzbach and R. Rejaie, Understanding churn in peer-to-peer networks[C]//Proc. Internet Measurement Conference(IMC), 2006.
[10] 王勇, 云晓春, 李奕飞.对等网络拓扑测量与特性分析[J]. 软件学报, 2008,19(4):981-992.
[11] M. Steiner, T. En-Najjary, and E. W. Biersack, Long term study of peer behavior in the KAD DHT[J]. IEEE/ACM Transaction on Networking, 2009, 17(5): 1371-1384.
[12] M. Steiner, T. En-Najjary, and E. W. Biersack, A Global View of Kad[C]//Proc. Internet Measurement Conference(IMC), 2007.
[13] M. Steiner, E. W. Biersack, and T. Ennajjary, Actively monitoring peers in Kad[C]//Proceedings of the 6th International Workshop on Peer-to-Peer Systems(IPTPS), 2007.
[14] Jarret Falkner, Michael Piatek, John P. John, Arvind Krishnamurthy and Thomas Anderson, Profiling a million user DHT[C]//Proc. Internet Measurement Conference(IMC), 2007.
[15] D. Jia, W. G. Yee, O. Frieder, Spam Characterization and Detection in Peer-to-Peer File-Sharing Systems[C]//Proc. ACM Conf. on Inf. and Knowl. Mgt. (CIKM), 2008.
[16] J. Liang, R. Kumar, Y. Xi and K. Ross, Pollution in P2P File Sharing Systems[C]//Proc. of INFOCOM, May 2005.
[17] D. Dutta, A. Goel, R. Govindan, H. Zhang, The Design of A Distributed Rating Scheme for Peer-to-peer Systems[C]//Proc. of Workshop on the Economics of Peer-to-Peer Systems, 2003.
[18] ChrisTopher D. Manning and Hinrich Schütze, Foundations of Statistical Natural Language Processing[M]. MIT Press, ISBN 978-0262133609, 1999.
猜你喜欢
计算机时代(2021年11期)2021-11-20 01:08:08
电脑爱好者(2019年9期)2019-10-30 03:43:29
电脑爱好者(2019年13期)2019-10-30 03:36:29
摄影之友(2019年8期)2019-03-31 03:06:19
课程教育研究(2018年30期)2018-12-14 07:24:06
计算机时代(2016年9期)2016-10-28 09:30:33
电脑迷(2014年8期)2014-04-29 07:37:40
环球时报(2014-01-18)2014-01-18 08:07:27
卫星与网络(2012年4期)2012-02-27 06:41:26
计算机应用文摘(2010年18期)2010-04-29 00:44:03
