
利用上下文信息的统计机器翻译领域自适应
2010-06-05 07:07:08吕雅娟苏劲松
中文信息学报 2010年6期
曹 杰,吕雅娟,苏劲松,刘 群
(中国科学院 计算技术研究所,中国科学院 智能信息处理重点实验室,北京 100190)
1 引言
近年来,统计机器翻译研究得到了迅猛的发展,提出了很多新的模型和方法并取得了很好的效果[1-3]。一些先进的统计机器翻译系统已经得到了实际应用,如Google的在线翻译和跨语言信息检索系统。统计机器翻译的实用价值逐渐得到体现。
当前主流的统计机器翻译系统都需要在大规模的双语语料库上进行训练得到翻译模型和语言模型。训练得到的模型在翻译同一领域的文本时通常会得到质量较高的译文,但翻译其他领域文本时,翻译质量明显下降。对于某些领域而言,获取大规模的平行语料是非常困难的。研究有效的领域自适应策略是一个可行办法。
一般说来,获取某个领域的单语语料库比双语平行的语料库要容易很多,而不同领域的单语上下文中包含着与领域相关的信息,有效利用这些领域信息会对统计机器翻译自适应研究有所帮助。
本文提出了一种领域特征计算方法,领域特征的计算中引入了单语上下文信息。相比于基于短语的模型而言,能够利用词性信息、长距离上下文等更丰富的上下文信息。
2 相关工作介绍
领域自适应问题在语音识别领域已有较多研究,但由于机器翻译问题的复杂性,在机器翻译模型尚不完善的阶段,领域自适应的研究较少。随着近几年统计机器翻译模型的不断完善,越来越多的学者注意到领域自适应问题在机器翻译中的重要性,相关研究也开始增多。
目前在机器翻译领域,自适应的研究按照自适应对象模型的不同可以分为翻译模型自适应和语言模型自适应。
对语言模型自适应的研究思路基本上都是采取构建信息检索模型,从单语语料库中检索与待翻译领域相似的句子,用这些句子构建自适应的语言模型以提高翻译效果。语言模型自适应先是被应用于语音识别领域,并取得了一定的效果,Eck et al.和Zhao et al.等人将这一思想引入统计机器翻译领域[4-5],将首次翻译的得到的候选翻译结果视为信息检索模型中的查询,在海量的单语语料库中检索出相似的数据,根据检索数据训练得到自适应的语言模型,可以明显的提高统计机器翻译的质量。
翻译模型的自适应研究中,Hildebrand et al.提出一种方法,从双语平行语料库中检索与测试集相似的句子,在检索返回的句子上训练自适应的翻译模型,将自适应的翻译模型与原翻译模型联合使用将会提高翻译质量[6]。Ueffing et al.提出一种在机器翻译中使用半监督学习的算法[7]:首先利用双语语料库训练一个初始的翻译系统,然后对in-domain的源语言单语进行翻译并对翻译结果进行打分,选择分数较高的译文与源语言单语构成人工构造的双语语料库,将构造出的双语语料库与原平行语料库合并进行训练,重复该过程,直到到达一定的轮数。这时候得到的增强的模型翻译效果比初始翻译系统要好。Yajuan Lü et al.[8]提出通过离线的数据选择和在线的模型优化的策略进行翻译模型的自适应。本质上看,模型优化是对多个短语表的插值使用,插值的系数由检索到的隶属子模型的句子在整个检索结果集中的比例决定。
综上所述,当前统计机器翻译领域自适应的研究主要集中在利用信息检索工具或者半监督等学习方法扩大训练集规模上,而对单语信息的利用并不充分。目前对单语的使用方式主要有以下两种:一是作为查询条件从双语语料库中检索相似句子作为自适应训练集,另外一种是用于半监督学习,通过初始系统对源语言翻译,然后选择较好的译文得到人工构造的双语,与原有的训练数据一起训练新的模型。
我们认为以上两种使用单语的方法没有充分挖掘单语内部包含的领域信息,本文提出一种有效利用单语上下文信息引入领域相关(Domain-specific)特征的方法。主要包括两步:一是从领域混杂的语料库中检索出与待翻译文本领域上接近的平行句对以扩大训练集规模,一是挖掘该领域的单语上下文信息,作为新特征引入对数模型框架内,使得与该领域相关的短语译文更有可能在机器翻译解码过程中被选择到。
3 利用上下文信息的领域自适应
3.1 基本思想介绍
领域自适应问题研究中,领域的表示是一个重要问题。我们认为,领域单语中包含着领域信息,上下文信息可以认为是表示领域的一个重要特征。如果能有效的融合领域信息和翻译模型,那么对领域自适应的研究将是很有帮助的。下面的例子显示了单语上下文信息对机器翻译的帮助。
我们要翻译关于功夫电影的文本,但我们只有经济领域的双语语料来训练翻译系统,此外,我们还有大量关于功夫电影领域的单语文本。假设语料如表1所示,词对齐后,中国分别对齐到China和Chinese。

表1 包含“中国”一词的平行句对和单语句子
在经济领域语料中,不考虑短语扩展的情况下,“中国”一词的翻译概率如表2所示。
我们要翻译来自功夫电影领域的汉语句子“我 喜欢 中国 功夫”, 由经济领域的平行语料训练的翻译系统,将“中国”翻译为China的概率要大于Chinese,翻译结果可能是“I love China Gongfu”。
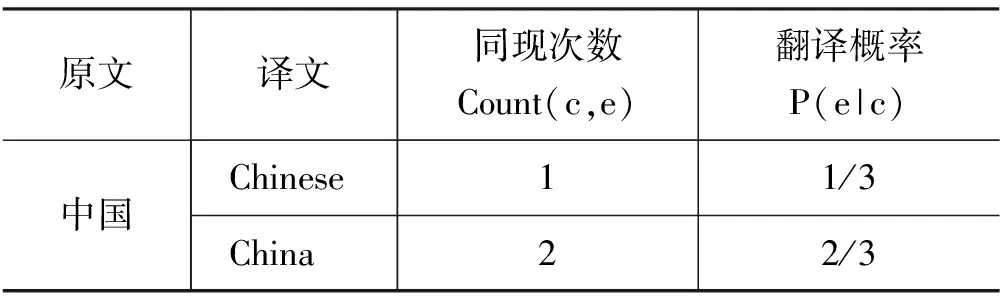
表2 “中国”一词的翻译概率
在功夫电影领域的源语言单语中,“中国”一词出现时,后面经常接“人”这个词,这就提供了有用的领域信息:在功夫的电影领域,“中国”后面经常接“人”这个词。本文提出的方法可以将上下文信息转化为领域特征引入翻译模型中,提高“中国”翻译为Chinese的概率,在翻译“我 喜欢 中国 功夫”一句时,可以翻译得到“I love Chinese Gongfu”。翻译效果要好于直接使用经济领域双语训练出的模型。
3.2 领域特征介绍
统计机器翻译的对数线性模型中,翻译的过程被建模为寻找最大概率译文ebest的过程:
(1)
其中,h1(e,f)…hm(e,f)是建立在源语言f和目标语言e上的m个特征函数,λ1...λm是其对应的特征值。对数线性模型中可以方便的扩充新的特征,在此,我们引入带上下文信息的领域翻译概率PD(e|f),其计算公式为:
(2)
在PD(e|f)的计算过程中,我们引入了隐变量context,代表上下文特征。其中,PD(context|f)可以从领域D的单语计算得到,代表了一定的领域信息。对于PD(e|f,context),缺乏D的双语语料,无法准确计算,我们采用信息检索的办法从大规模的混合领域双语中检索出与领域D接近的语料作为双语训练语料。检索得到的双语语料在领域上与D接近,从近似语料中计算的概率分布PD-similar(e|f,context)与领域D上的概率分布PD(e|f,context)比较接近。在此,我们用PD-similar(e|f,context)代替PD(e|f,context),得公式(3):
PD(e|f)
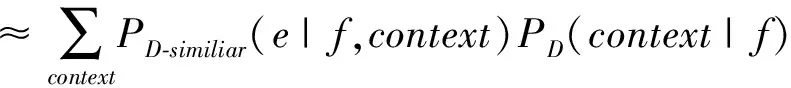
(3)
总结起来,领域特征的计算过程可分为以下四步:1) 从领域单语中抽取领域相关的单语上下文信息。2) 检索出一批领域接近的双语语料作为新的训练语料 3) 从训练语料的双语词对齐结果中抽取带上下文信息的短语翻译对。4) 用1)和3)的结果计算领域特征。
下面以3.1节的例子为例,说明本方法起作用的原因。这里,我们取Context为下文第一个词,下面以3.1节中的“中国”一词为例,分别计算PD-similar(e|f,context)和PD(context|f)。在经济领域中,带有Context的翻译概率如表3所示。

表3 经济领域双语中“中国”下文词的统计信息
在功夫电影领域单语中,“中国”的下文词统计信息如表4所示。
取Context为下文第一个词时,根据表3,4的统计信息,使用功夫电影领域单语进行自适应后的领域特征的计算如表5所示。

表4 功夫电影领域“中国”下文词的统计信息
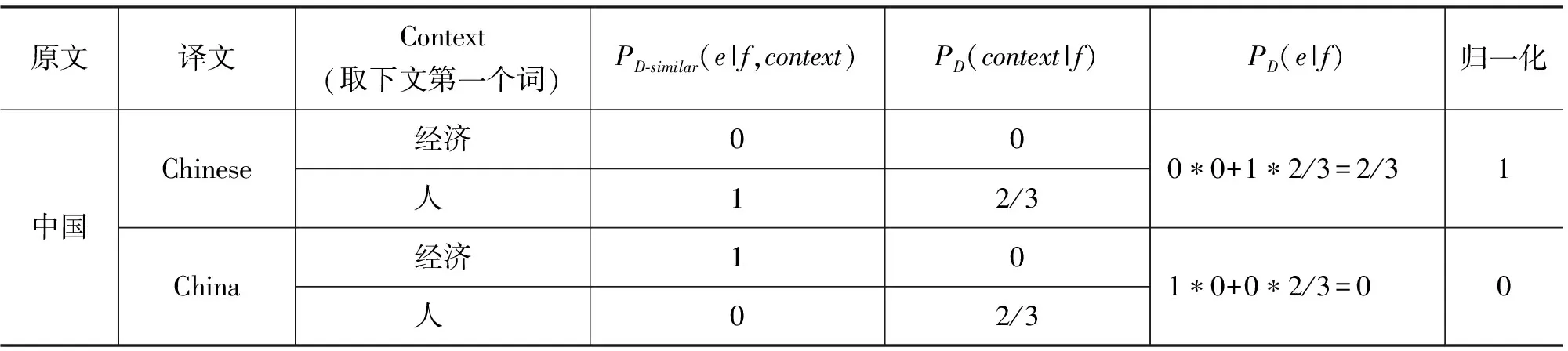
表5 领域特征的计算
表5中,“中国”翻译为Chinese领域特征值大于翻译为China。加入新特征后的模型将“我 喜欢 中国 功夫”翻译为“I love Chinese Gongfu”,与正确译文更加接近。
上述推导过程可以看出本方法充分利用了单语体现出的“中国”后面经常接“人”这个词的特征。本例子用到的特征是源语言单语的下文第一个词,同理,其他上下文特征也能起类似作用。
基于短语的翻译模型本身具备一定的上下文翻译能力,但对于词性等上下文信息没有处理能力,本文的方法可以应用词、词性、长距离上下文等多种上下文信息,比短语内部包含的上下文要丰富很多。而且,这里的上下文来源于领域单语,这也是与短语模型上下文的区别。
理论上,任何能有效表示该领域上下文的特征都可以转化为领域特征融入对数线性模型,本文提出的模型在上下文特征的选择上具有很强的扩展性。
4 实验
4.1 实验设置
我们采用著名的开源工具Moses*http://www.statmt.org/moses/作基线系统,所使用的特征如表6所示。

表6 对数线性模型的特征
语言模型训练工具采用SRILM Toolkit[9],评测工具使用mteval-v11b.pl*http://www.nist.gov/speech/tests/mt/resources/scoring.htm,评测指标采用BLEU4[10],大小写不敏感。另外,使用了Lemur作为检索语料的工具。
在IWSLT*http://www.is.cs.cmu.edu/iwslt2005/评测的汉英翻译任务上进行实验,IWSLT评测语料主要由面向旅游领域的口语对话组成,领域特征比较明显,适合进行领域自适应的研究。实验语料详见表7。
4.2 实验结果
实验中,我们设置了三组baseline:以FBIS做训练集的Baseline1、以混合语料做训练集的Baseline2、FBIS与混合语料合并后的Baseline3。采用本文第3节提出方法利用上下文信息进行领域自适应,具体做法分如下步骤:
1. 合并FBIS语料和领域混杂语料,记为T,用信息检索工具Lemur在T上建索引。
2. 计算T中的每个句子与开发测试集合每个句子的相似度分数,并按照相似度分数对T进行排序。这一步耗时较长,尤其当训练数据规模较大时。数据选择的策略还有很多,不是本文研究的重点,这里我们采用了这种比较简单的方式。
3. 从T(共700k)中选取topN(N=100k,200k,300k,…)平行句对作为新的训练集,进行词对齐,并抽取带上下文特征的短语表,即公式(3)中的PD-similar(e|f,context)。
4. 根据领域单语语料,计算PD(context|f)。
5. 根据公式(3),计算的得到领域特征PD(e|f),重新训练并记录翻译BLEU值。
采用本文提出的方法进行领域自适应的实验结果如表8所示。
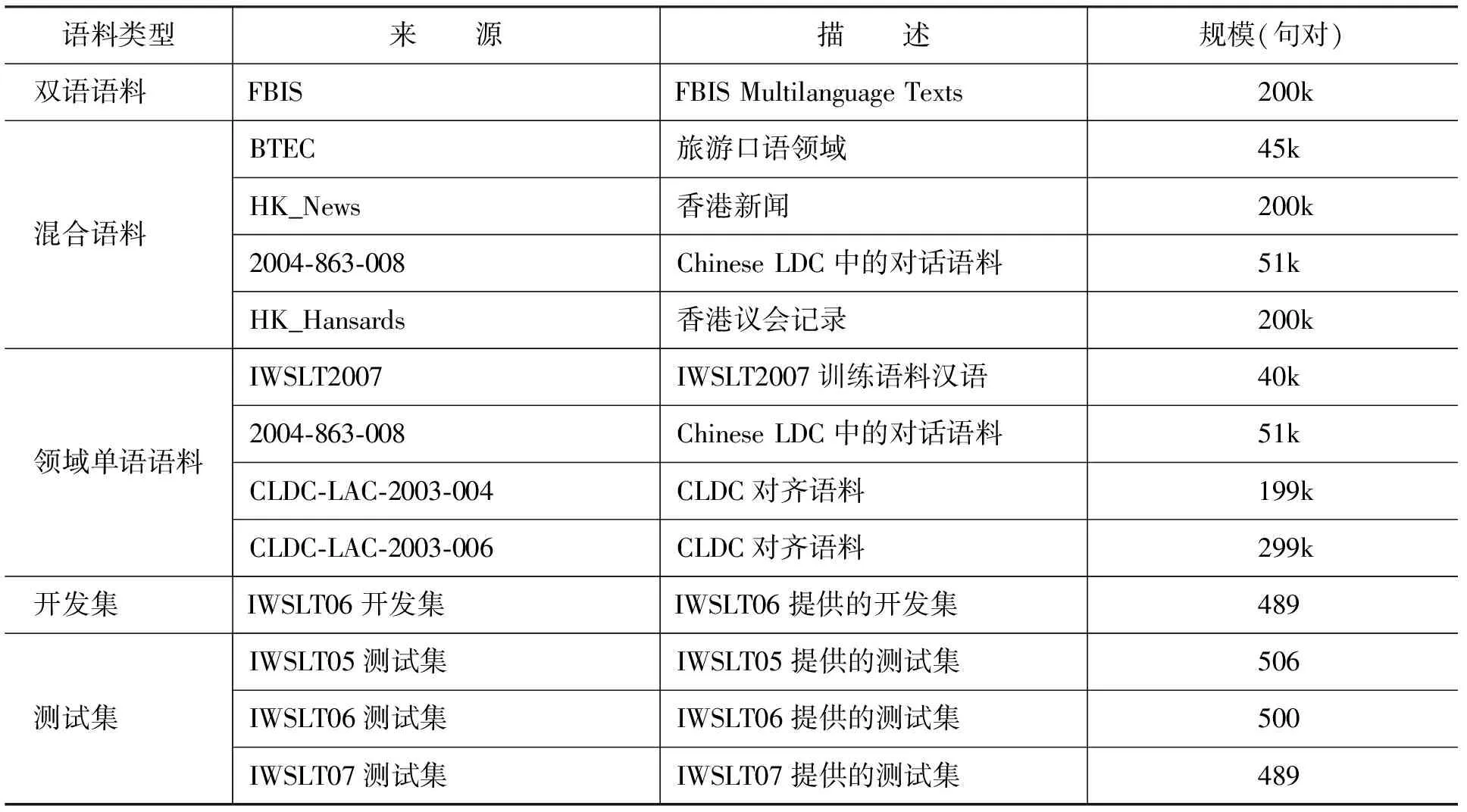
表7 实验语料情况

表8 IWSLT上的实验结果
表8说明以下问题:
1. Baseline1的训练语集是FBIS语料,属于新闻领域,而开发测试集属于旅游领域,领域差别较大,所以翻译效果较差。这也说明了进行领域自适应研究的必要性。
2. Baseline2的训练集是各领域混杂的语料,其中也包括了旅游领域的语料。语料规模较大,所以开发测试集的许多短语能在混合语料中找到正确的译文,BLEU值比Baseline1要高很多。将两者混合后的Baseline3因为语料规模的增大比Baseline1、Baseline2都要好。
3. 自适应模型的BLEU值随着选取语料规模N的变化而变化。基本的变化规律是:当N较小时,随着N的增大,BLEU一直增大,增大到一定程度后,再继续增大N,BLEU值不稳定,且有下降的趋势。
我们分析其原因是:当N较小时,有许多短语没有学习过,解码器找不到对应的译文,增大语料规模,可以使得更多的本领域短语被学习到。增大到一定程度以后,继续增大N,排名靠后的语料与开发测试集合的领域差别较大,对译文选择起到干扰作用。
N=500k时,在开发集上BLEU值最高(0.195 362),在测试集IWSLT07上面BLEU值也是最高的。我们以N=500k作为实验结果。自适应模型相比Baseline2在三个测试集合都有不同程度的提高:IWSLT05上提高0.84个点,IWSLT06上提高0.73个点,IWSLT07上提高0.42个点。相比Baseline1,自适应模型提高效果更加显著。
4.3 词特征与词性特征的比较
为了进一步分析领域特征带来的影响,我们在topN=500k的基础上分别对词特征、词性特征进行实验对比。
当不使用单语领域信息时,自适应模型退化为标准的基于短语的翻译模型,我们以此为Baseline。加入不同特征时的翻译BLEU对比见表9。其中W-1代表下文第一个词、W+1代表上文第一个词、POS-1代表下文第一个词的词性、POS+1代表上文第一个词的词性。

表9 采用不同上下文特征对自适应效果的影响
表9中第二行是不使用任何上下文的Baseline值,第三到第六行代表分别加入不同的上下文特征进行自适应,第七行是加入所有特征的结果。从表9可以看出:
1. 使用多个上下文特征要好于使用单个特征。
使用多个上下文特征可以产生多个领域特征,短语译文选择时候可以利用更多的信息源,从而做出更加正确的判断。
2. 词性特征作为上下文要明显好于词特征。
从BLEU值看,在三个测试集上,使用上下文词性特征普遍比使用上下文词特征效果要好。我们分析原因是使用词特征时,数据稀疏问题影响要比使用词性特征严重。我们使用的判别式词性标记工具采用了北大语料库加工规范标准,词性集有40多个[11]。
为了比较词特征与词性特征的作用,我们统计了短语表中分别被词特征和词性特征赋予领域概率的短语对数目,如表10所示。

表10 使用词和词性特征被赋予领域特征的短语对数目比较
从表10可以看出,被词性特征赋予领域概率的短语对数目要大于被词特征赋予领域概率的短语对数目。以词性作为上下文信息,数据稀疏问题远没有以词为特征时严重。
4.4 单语规模的影响
图1是在topN=500k的自适应实验中只改变单语数量,保持其他因素不变的情况下比较翻译结果。可以看出,随着单语规模的增大,自适应效果会越来越好,各个测试集的BLEU值一直处于上升趋势。
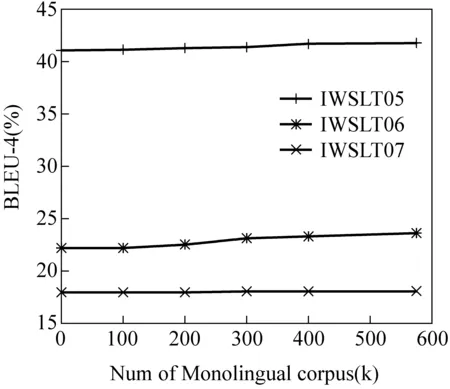
图1 单语规模与BLEU值关系
领域特征的计算受单语规模影响较大。当单语规模较小时,数据稀疏问题会变得非常严重,这时只能对较少的部分短语对赋予领域翻译概率,翻译质量的改善将很不明显。如果单语数量变为0,则所有短语对的领域概率将变为0,领域特征将不起作用,自适应模型变退化为标准的基于短语的翻译模型。
对某个领域来说,单语的获取要比双语获取容易得多,数量也大得多,本文提出的利用单语进行自适应的方法有应用价值。利用单语进行自适应研究的方法可以充分挖掘单语内部的领域信息,随着单语规模的增大,我们相信该方法会起到更大的作用。
5 总结与下一步的工作
本文提出了一种基于单语上下文信息的自适应方法,在对数线性模型框架内引入领域特征。领域特征的计算中,一方面利用检索模型从混合语料中检索领域类似语料以更准确的估计本领域的翻译概率,另一方面从领域单语中挖掘单语的上下文信息并用来计算领域特征。
从实验结果与分析可以看出,利用单语上下文信息能够对统计机器翻译领域自适应有所帮助的。从理论上,该方法既可以使用上下文词、词性等局部上下文信息,也可以使用长距离的上下文信息。如果不考虑任何上下文信息,所有短语对的领域特征值变为0,便退化为标准的基于短语的翻译模型。
当单语规模较小时,新模型会存在数据稀疏的问题。这时用单语上下文信息的方法只能对较少的短语对赋予领域特征。随着单语规模的增大,自适应的短语会越来越多,新模型的效果会越来越好。一般而言,单语的获取要比双语容易得多,本文的方法是有应用价值的。
下一步工作我们将寻找解决数据稀疏问题的办法,并尝试引入更多的上下文特征,还将考虑多元的上下文特征。
[1] Peter. F. Brown, Stephen A. Della Pietra, Vincent J. Della Pietra,Vincent J. Della Pietra, Robert L. Mercer, The Mathematics of Statistical Machine Translation:Parameter Estimation[J]. Computational Linguisitics, 1993,19(2):263-312.
[2] Philipp Koehn, Franz Josef Och, and Daniel Marcu.2003. Statistical phrase-based translateion[C]//Proceedings of HLT-NAACL 2003: 127-133.
[3] Franz Josef Och and Hermann Ney. Discrimitive training and maximum entropy models for statistical machine translation[C]//Proceedings of ACL 2002, 2002: 295-302.
[4] Matthias Eck, Stephan Vogel, Alex Waibel. Language model adaptation for statistical machine translation based on information retrieval[C]//International Conference on Language Resources and Evaluation,2004.
[5] Bing Zhao, Matthias Eck, Stephan Vogel. Language Model Adaptation for Statistical Machine Translation ria structured query modes[C]//Proc. of COLING, 2004: 411-417.
[6] Almut Silja Hildebrand et al, Adaptation of the Translation Model for Statistical Machine Translation based on Information Retrieval [C]//Proc. of EAMT 2005, 2005: 133-142.
[7] Nicola Ueffing, Gholamreza Haffari and Anoop Sarkar. Semi-superivesed Model Adaptation for Statistical Machine Translation[J]. Machine Translation, 2008, 21(2):77-94.
[8] Yajuan Lü, Jin Huang. Improving Statistical Machine Translation Performance by Training Data Selection and Optimization[C]//International Conference on Empirical Methods in Natural Language Processing (EMNLP), 2007: 343-350.
[9] A.Stolcke. 2002. SRILM-an extensible language modeling toolkit[C]//Proc. of ICSLP, 2002:901-904.
[10] Papinensi, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU:A Method for Automatic Evaluation of Machine Translation[C]//Proc. of the 40th Annual Meeting of the Association of Computational Linguistics, 2002: 311-318.
[11] 俞士汶,段慧明,朱学锋,孙斌,常宝宝. 北大语料库加工规范:分词 词性标注 注音[J]. Journal of Chinese Language and Computing, 2002, 13(2):121-158.
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
语言与翻译(2015年4期)2015-07-18 11:07:45
民族古籍研究(2014年0期)2014-10-27 08:24:34
新晨(2013年7期)2014-09-29 06:19:50
新晨(2013年5期)2014-09-29 06:19:50
新晨(2013年10期)2014-09-29 02:50:54
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
