
基于版块的论坛增量搜集策略
2010-06-04 07:05杜言琦
中文信息学报 2010年3期
杜言琦,马 军
(山东大学 计算机科学与技术学院,山东 济南 250101)
1 引言
随着网络的不断发展,论坛作为Web信息交流共享平台拥有数以百万的用户,论坛数据通常包含大量高价值的知识和信息,已经成为许多Web应用的重要数据源[1]。例如一些商业搜索引擎已经开始利用论坛数据来改善它们的搜集质量[2]。无论何种Web应用,基础的步骤是不断从论坛站点中抓取新增数据,来维持对数据索引的增量更新,以保证检索的实时性。
传统的增量搜集技术是针对普通的静态页面[3],调度的基本单位是单个页面[4-5],对论坛页面进行增量搜集的效率很低,因为论坛站点有一些不同于普通站点的特征:属于同一版块的帖子和属于同一帖子的回复通常都分布在多个页面上;论坛更新速度快,帖子内容增量式更新。传统的增量搜集技术不适合进行论坛数据的增量搜集。因此,寻找新颖的论坛增量搜集算法具有重要的学术和应用价值。
通过观察多个论坛,我们发现帖子一般是按照发布或最新回复时间排列在帖子列表页上。通过对论坛版块变化规律的统计,发现不同的版块更新速度不同并且版块的更新具有时间局部特性,据此我们提出了一种版块权重的计算公式,给予不同版块不同的权重,以此来确定对版块的抓取频率;提出一种确定抓取时间点的算法,根据版块的局部时间规律来确定对版块的抓取时间点。
本文的主要贡献有:(1)以版块为单位进行增量调度而不是像现有大多数爬虫以单个页面为调度单位。(2)提出了基于版块的增量抓取算法,获得很高的准确率和召回率。(3)提出了基于版块的抓取调度算法,大幅减小系统总延迟。
2 相关工作
传统增量搜集技术的核心理论依据是网页的变化规律和以此为基础的最优化调度策略。对网页变化规律的研究目前主要有两种方法:一种是基于试验手段对Web中网页采样,通过搜集和检查样本的变化规律,从而估计整个Web的变化规律[3]。另一种是从理论上直接给网页的变化建立数学模型,然后进行分析和论证,最后试验验证该模型并估计相关参数,以此模型预测页面的下次变化时间[4,12]。在当前的研究中,网页的变化一般被认为是泊松过程[3],即网页两次变化直接的时间间隔服从指数分布,以此来建立基本模型。基于网页变化模型,就要通过搜集来估计其参数[4-5],以获得网页的变化频率并推算下次变化时间。由于通常没有足够的时间和资源去获得互联网上每个页面的变化时刻,因此需要对网页变化频率进行估计。
目前,论坛爬虫的研究还较少。文献[6]研究了论坛抓取问题,它使用一组启发式规则作为抓取策略,而在现实中存在数百种论坛结构,无法为这些论坛制定一个普遍的启发式规则。文献[7]中提出了一种基于结构化驱动的爬虫,通过人工选择目标页面的一个样本,使用该样本页面的DOM树作为目标的描述,但该爬虫仅能找到通往目标页面的路径,并不能找到最优路径。论坛中通常有多条路径通往目标页面,这些路径的大部分是快捷链接方式,不能涵盖所有的目标页面。因此该方法并不适于论坛抓取。文献[1-2]提出了智能化的论坛爬虫IRbot,这种算法首先下载一些目标论坛的样本页面,在样本上构建站点图,在该图上从全局角度考虑找到最优遍历路径。该爬虫与传统爬虫相比取得了较好的效果,但没有能够解决论坛的增量搜集问题。
3 相关定义
文献[8]提出了基于信息生命周期的增量搜集技术,研究的是单个页面中信息的变化规律。而在论坛中信息是跨越页面的,信息的生命周期通过多个页面表现,因而本文以属于同一信息的页面集合作为增量搜集的基本单位。
如图1所示,论坛“软件推荐”版块的信息分布在27个帖子列表页上,而其中第二个帖子的信息分布在5个帖子展示页面上。每组页面集合是一个信息整体,其中版块指的是论坛中一个版块所包含的页面集合,帖子指的是论坛中一个帖子包含的页面集合。

图1 论坛网页类型及版块、帖子实例
最大抓取次数是指系统在现有的计算和带宽资源下,单位时间段内可提供的最大搜集次数。增量搜集需要保证本地数据的时新性,本文使用延迟来表示数据的时新程度,下面给出版块延迟和系统总延迟的定义。
定义1:给定一个版块P,生成新的帖子的时间序列G为g1,g2,…,gk;有新回复帖子的时间序列R为r1,r2,…,rn。增量搜集系统对版块P的增量搜集的时间序列C为c1,c2,…,cm。对于一个在gi时间产生的帖子Gi,它的延迟定义如下:
D(Gi)=cj-gi
(1)
其中cj是C中满足gi≤cj条件的最小值。
同理,对于在ri时间新增的回复Ri,它的延迟定义如下:
D(Ri)=cj-ri
(2)
其中cj是C中满足ri≤cj条件的最小值。
那么版块P的延迟定义如下:
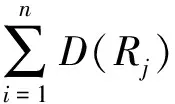
(3)
其中θ是调节参数,通常优先获取新增帖子比获取新回复更加重要。
定义2:增量搜集系统需要抓取多个版块,不同的版块重要度不同,优先减小重要度较大的版块的延迟会获得更好的效果。如果增量系统的目标论坛包含的版块为{P1,P2,…,Pn},并且每个版块Pi拥有一个重要度Wi,那么系统总延迟定义如下:
(4)
4 基于版块的增量搜集策略
基于版块的增量搜集策略建立在大规模数据的基础上,可以使用文献[1-2]中的算法获取数据,利用分页链接将属于同一版块和同一帖子的页面组织在一起。
本策略包含两部分:基于版块的增量抓取算法和增量调度算法。前者负责查找抓取新增和新回复的帖子,后者确定对版块的抓取频率和每次抓取的时间点。
4.1 基于版块的增量抓取算法
观察多个论坛结构,发现如图2所示帖子按照最后回复时间的先后顺序排列。使用MDR/DEPTA[10-11]算法可从版块页面中抽取帖子记录,通过判断记录中URL是否抓取和最后回复时间比较,得到所有新增和新回复的帖子。具体算法如下:

图2 帖子排序特点的例子
算法BIC基于版块的增量抓取算法
输入:版块P={p1,p2,…,pn},pi指P的第i个页面。
步骤:1) 按顺序取出P中的一个页面Pi,进行抓取分析,抽取信息得到一组帖子记录L。其中的每个记录有两个属性:URL以及该帖子对应的最后回复时间。
2) ForL中的每一项li(URL,last_reply_time),判读该帖子的URL是否存在本地索引库LocalDB中。
Ifli.URL不在LocalDB中,那么这是一个新增的帖子。
Then 抓取该帖子存储到本地资料库中。
elseli.URL已经存在于LocalDB中了,那么判断最后回复时间是否更新。
If last_reply_time 已经变化,那么说明该帖子有新回复。
Then 抓取该帖子新回复的部分存储到LocalDB中。
Else 该帖子没有任何变化,不做任何处理。
3) 循环步骤1)、2),直至P中的某一页pj,从中抽取出的帖子列表L中,没有任何新增或新回复的帖子,算法停止。
4.2 基于版块的增量调度算法
本节根据统计出的版块的变化规律,提出了基于版块的增量调度算法。算法分为两部分:(1)根据版块权重分配抓取次数,确定抓取频率。(2)根据版块的局部时间规律,确定针对版块的抓取时间点。经过调度使得系统的总延迟大幅减小。
4.2.1 论坛版块变化规律的研究
启动论坛爬虫,从2007-12-15到2009-03-30抓取了包括百度贴吧、舜网等17个论坛的数据,共有约108万个帖子,定义为数据集Q。在数据集Q中,每个帖子表示为T={board,publish_time,r_time1,r_time2,...,r_timen},board是指该帖子隶属的版块,publish_time是T的发布时间,而r_timei是指该帖子的第i个回复的时间,n是回复数目。版块的变化次数就是其包含所有帖子的变化次数之和。
图3展示的是百度贴吧中20个版块的变化情况。不同版块在一星期内的变化次数分布如图3(a)所示,不同版块的变化次数相差较大。图3(b)纵轴是指每小时内变化次数与总变化次数的比值,各个版块总的变化趋势相同,在不同的时间点变化频率相差很大。这说明版块的变化频率与一天内的局部时间相关,定义为版块的局部时间规律。这种现象与文献[9]中统计的变化频率较大的页面的变化规律相似。
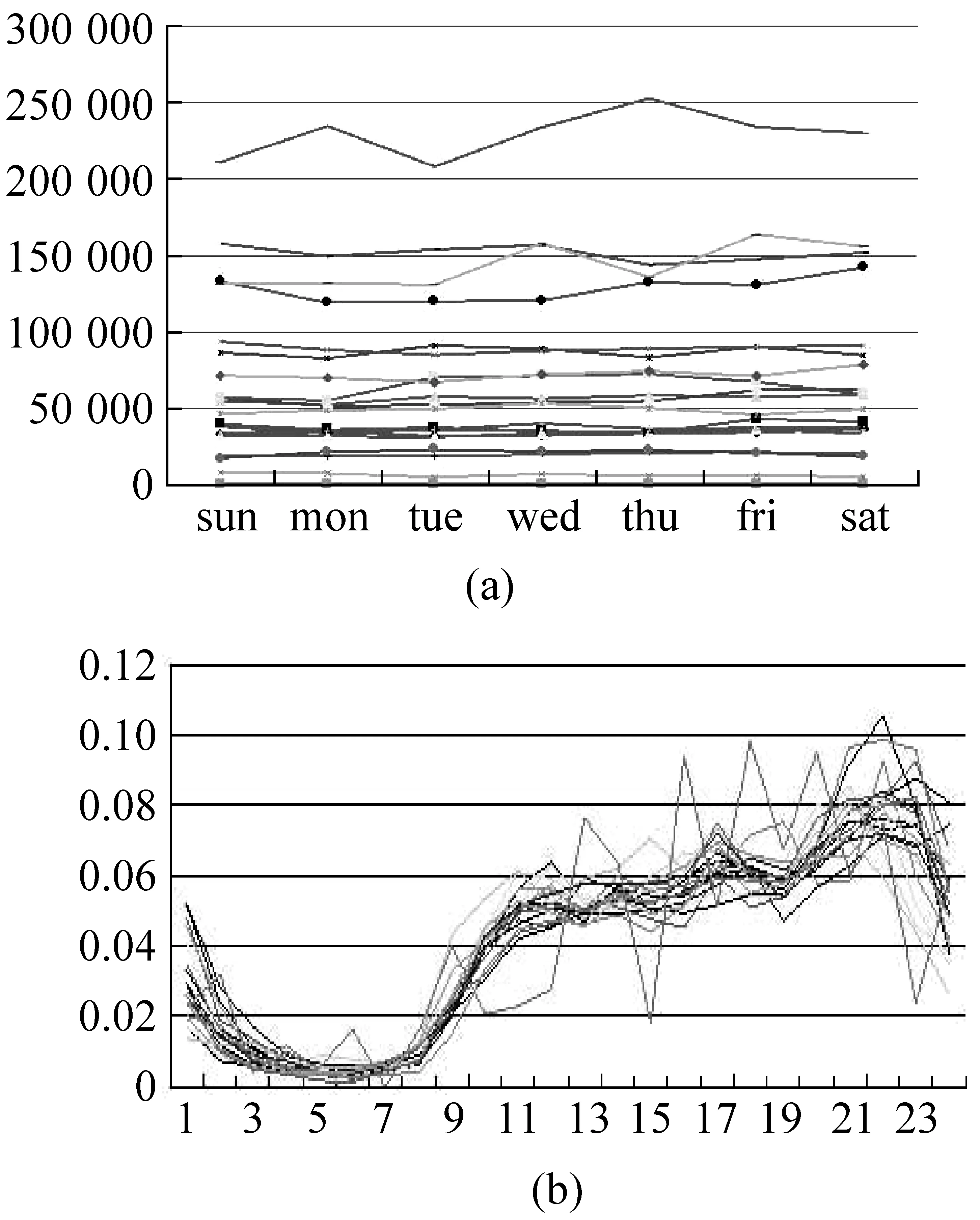
图3 版块在一星期和24小时内的变化次数分布
4.2.2 分配抓取次数
如图3(a)中的统计,不同的版块的更新速度不同,而且不同版块的重要度也不相同。版块的权重与版块的更新速度、版块重要度以及论坛重要度有关,需要根据版块权重确定对版块的抓取频率。版块的权重定义如下:
WP=Ws×Wp×(Ng+θ×Nr),
(5)
(0<θ≤1)
Ws是网站的重要性,Wp是版块的重要性,Ng和Nr分别是该版块中某段时间每天新增和新回复帖子数目的平均值,θ是调节参数。在本文中,暂不考虑论坛和版块的重要度,Ws和Wp都设置为1。
假设有n个版块,每个版块Pi的权重为WPi,可使用的最大抓取次数为M,则分配给该版块Pi的抓取次数定义如下:
×M
(6)
4.2.3 确定抓取时间点
图3(b)反映出版块的更新频率具有局部时间规律,在8点到24点这个阶段更新频率较大,而从0点到8点的阶段更新频率大幅减小。因此需要根据版块的局部时间规律以及分配给它的抓取次数m,确定m个抓取时间点,使得该版块的延迟最小。
我们使用版块P最近一段时间S中的数据,将帖子创建时间和回复时间按照时间粒度K分布在从0点到23点的范围内,这样得到一组区间{T1,T2,…,Tk},每个区间Ti都有一个分值SCi:
(7)
其中g_numi和r_numi分别是落在区间Ti中的帖子创建数目和回复数目。如下图,K为1h。
如果分配给版块P的抓取次数为m,根据版块更新频率的时间局部性规律来确定抓取时间点,有两种方式:
(1) 假设采集时间点分别为c1,c2,…,cm,且函数f(t)表示为时间点为t时的SC值。那么版块P的延迟D(P)为:
,
(8)
其中c0=0,cm+1=24。


图4 版块局部时间规律图
等于零,得到如下公式:

(9)
由公式(9)可以看到ci+1采集点可以直接根据公式由ci和ci-1点确定。但在这种方式中,c1点的确定需要由人工指定,而c1点的选取直接确定了其他采集点的选取。
(2) 在上面的方式中c1无法确定且计算复杂,可以使用如下的近似算法:将图4中矩形块组成的区域等分为m+1块,每个分割点就是确定的抓取时间点。这样在更新频率较高的时间段,分配的抓取点也较多。这种方式是近似最小延迟,但简单易于计算。
算法BRA基于版块的增量调度算法
输入:所有版块对应的权重集合为WP={wp1,wp2,…,wpn},局部时间规律集合SC={sc1,sc2,…,scn},其中sci是一个24维的数组。单位时间的最大抓取次数为M。
输出:每个版块Pi的抓取时间点集合Ci{c1,c2,…,cmi}。
步骤:1) 任取WP中未处理的wpi,根据公式(6)计算分配给版块Pi的抓取次数mi。
2) 计算等分块的面积A=1/(mi+1),累计面积SA=0;并取出Pi对应的数组sci。
Forjfrom 1 to 24
If SA>=A时
计算抓取时间点ci
并将ci加入到集合Ci中;A+=1/(mi+1);
Else SA+=sci[j];
3) 输出所有的抓取时间点集合C1,C2,…Cn。
5 实验和结果
5.1 实验准备
从表1中展示的八个网站中选取的110多个版块,选择发布或回复时间在2009年1月初到2009年6月底期间的帖子进行抓取,共得到138 258个帖子。定义为数据集S。

表1 实验中抓取的论坛
在确定版块抓取频率和抓取时间点时都需要利用版块的统计信息,需要确定统计的时间范围。经过实验发现统计范围从20天开始估算出的权重和局部时间规律趋于稳定。
5.2 评测基于版块的增量搜集策略
5.2.1 评测增量抓取算法
为了评估增量搜集算法的质量,我们使用两个评测标准召回率和准确率:


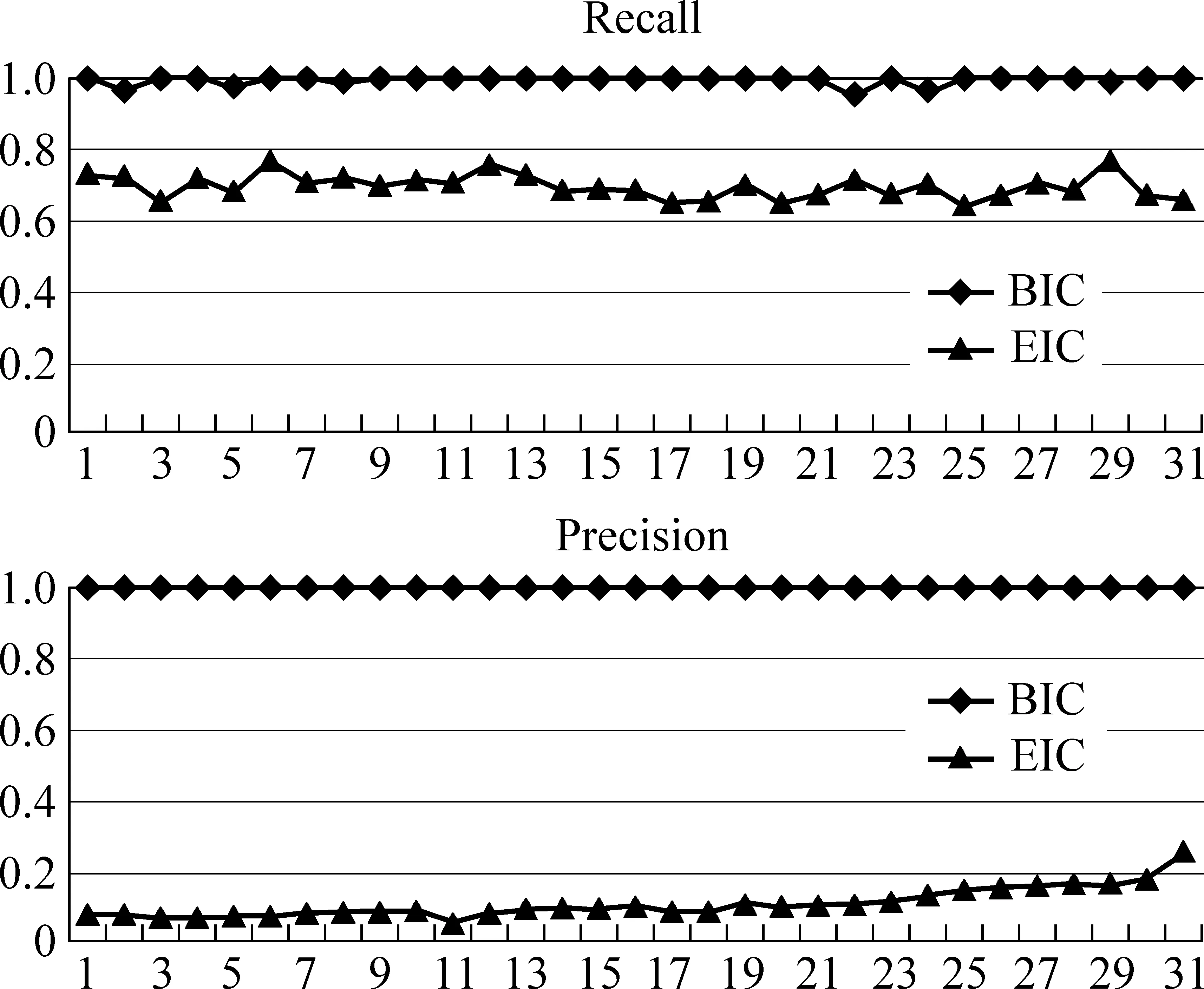
图5 召回率和准确率
本文提出的基于版块的增量抓取算法BIC。算法EIC以帖子和版块的平均变化间隔计算帖子的下次变化时间和新增帖子的出现时间。在数据集S上进行模拟抓取实验,6小时为一个抓取周期,持续时间从5月25日到6月25日共31天。计算每天两个评测标准的平均值,两种算法的比较结果如图5所示。从结果看,BIC算法在召回率和准确率上均优于算法EIC。EIC使用历史平均变化频率来估计变化时间,而帖子不同于普通页面,变化频率不能简单的由历史平均变化频率来估计,因而EIC算法的准确率很低。BIC算法通过判断帖子的URL是否抓取以及最后回复时间是否变化,能保证所有抓取的帖子都是新增或发生变化的。准确率高则可以避免重新抓取未变化的帖子,从而节省大量带宽资源。
5.2.2 评测增量调度算法
以总延迟做为评测标准,我们在数据集S上进行模拟抓取:从数据集S中可以得一组gij,rij序列,分别代表第i个版块第j次发布帖子的时间和第j次回复的时间。根据计算出的权重和局部时间规律,确定了抓取时间序列cij。根据公式(4),就可以算出总延迟。
为了说明调度算法具备普遍性,分别选取了4月5日—4月15日、5月10日—5月20日、6月15日—6月25日,三段周期为10天的区间,每天采集次数m={4,5,…,11}次,根据该日期前20天的数据来计算版块权重和局部时间规律,计算权重时θ设置为0.5且区间粒度设置为1小时。分别采用下面四种调度方式:
ERA.按照版块平均分配抓取次数和按照时间平均确定采集时间点的方式。
WRA.只按照统计出的版块权重权重进行调度。
LRA.只按照局部时间规律确定抓取时间点。
BRA.按照统计的权重和局部时间规律进行调度和确定抓取时间点。
计算出的总延迟的结果如图6所示。

图6 三个不同时间段的总延迟结果
图6纵轴是总延迟的日平均值,其中ERA的延迟并非单调递减的,增加抓取次数,延迟反而增大,这是没有考虑版块局部时间规律的缘故,这种进一步说明了局部时间规律的重要性。从图6可以看出,在总资源耗费相同的情况下,在三个时间区间内,我们提出的基于版块的增量调度算法BRA的总延迟最低。
将三个时间段中算法ERA和算法BRA求出的总延迟求平均值,计算算法BRA在总延迟上减小的比例,如表2所示。

表2 与基准方法比较
根据表2中的数据,相对基准ERA方法,本文提出的BRA算法最高减小了42%的延迟。
6 结论及将来的工作
本文通过分析多个论坛的结构和变化规律,发现新增和新回复帖子通常按时间顺序排列,不同的版块更新速度不同并且版块的更新频率与当天的局部时间相关。据此提出了一种新的基于版块的论坛增量搜集策略,以同一信息包含的页面集合为调度单位。策略包括增量抓取算法和调度算法,实验结果显示,本策略能在保证很高的覆盖率和准确率的同时,大幅减小系统的总延迟。存在一些BBS式的论坛,其版块页面不展示帖子的最后回复时间等信息,无法判断帖子是否发生变化。针对这种情况,下一步的工作是研究帖子的变化规律,预测下次回复的时间,解决及时获取新回复的问题。
[1] Cai R, Yang JM, Lai W., et al. iRobot: An Intelligent Crawler for Web Forums[C]//Proc. of the 17th World Wide Web Conf.Beijing,2008:447-456.
[2] Wang Y, Yang JM, Lai W,et al. Exploring Traversal Strategy for Web Forum Crawling[C]//ACM SIGIR. Singapore,2008: 459-466.
[3] Cho J, Garcia-Molina H. The evolution of the Web and implications for an incremental crawler[C]//Proc. of the 26th Int’l Conf. on Very Large Databases. San Francisco: Morgan Kaufmann Publishers, 2000: 200-209.
[4] 孟涛,王继民, 闫宏飞.网页变化与增量搜集技术[J].软件学报, 2006,17(5):1051-1067
[5] Cho J, Garcia-Molina H. Effective page refresh policies for Web crawlers[J]. ACM Trans. on Database Systems, 2003,28(4): 390-426.
[6] Guo Y, Li K, Zhang K, et al. Board forum crawling: a Web crawling method for Web forum[C]//Proc. 2006 IEEE/WIC/ACM Int.Conf.Web Intelligence, Hong Kong, 2006:745-748.
[7] M. L. A. Vidal, A. S. Silva, E. S. Moura, and J. M. B. Caval-canti. Structure-driven crawler generation by example[C]//Proc. of the 29th SIGIR Conf,Seattle,2006:292-299.
[8] Olston, C. and Pandey, S. Recrawl scheduling based on information longevity[C]//Proc. of the 17th World Wide Web Conf. New York,2008:437-446.
[9] S. O’Brien and C.Grimes.Microscale evolution of web pages[C]//Proceedings of the 17th International World Wide Web Conf, New York,2008:1149-1150.
[10] Liu B, Grossman, R and Zhai, Y. Mining data records from Web pages[C]//Proc. of the 9th ACM SIGKDD Int’l Conf. on Knowledge discovery and data mining,Washington, 2003:601-606.
[11] Zhai Y , Liu B. Structured data extraction from the Web based on partial tree alignment[J]. IEEE Trans. Knowl. Data Eng. 2006,18(12):1614-1628.
[12] Cho J, Ntoulas A. Effective change detection using sampling[C]//Proc. of the 28th Int’l Conf. on Very Large Databases. San Francisco: Morgan Kaufmann Publishers, 2002:514-525.
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
科学与社会(2020年4期)2020-03-07
当代水产(2019年11期)2019-12-23
中学生数理化·中考版(2019年9期)2019-11-25
小雪花·成长指南(2016年11期)2016-12-07
小品文选刊(2009年7期)2009-05-25
杂文选刊(2006年20期)2006-05-14
