
基于霍夫曼树的内容寻址网络失效区域恢复机制*
2010-04-17 01:51:58张伟哲张宏莉吴太康
电信科学 2010年1期
张伟哲,张宏莉,吴太康,许 笑
(哈尔滨工业大学大学计算机科学与技术学院 哈尔滨 150001)
基于霍夫曼树的内容寻址网络失效区域恢复机制*
张伟哲,张宏莉,吴太康,许 笑
(哈尔滨工业大学大学计算机科学与技术学院 哈尔滨 150001)
针对内容寻址网络多区域失效导致的覆盖网结构破坏与子网割裂问题,提出了基于霍夫曼树的内容寻址网络失效恢复机制。采用霍夫曼树对覆盖网逻辑空间重新进行组织与优化,在失效结点检测机制的基础上,提出了单个区域与多个区域失效恢复机制。实验证明,该机制可以确保完整地恢复整个逻辑空间,解决内容寻址网络中结点和网络不稳定的问题,能很好地适用于动态自组织网络的管理,并可作为目前复杂多变的网络环境的管理模型。
对等网络;内容寻址网络;失效恢复;霍夫曼树
* 国家自然科学基金资助项目(No.60703014),国家重点基础研究发展规划资助项目(No.G2005CB321806),高等学校博士学科点专项科研基金资助项目(No.20070213044),中国博士后科学基金经费资助项目(No.20070410263),黑龙江省博士后资助经费资助项目(No.LBH-Z07108)
1 引言
内容寻址网络(content addressable network,CAN)是基于多维空间结构的P2P网络[1],利用分布式哈希表将数据和结点映射为键值,完成多维笛卡尔空间中数据存储与查询。与基于带弦环结构Chord网络[2]、基于异或距离度量的Kademlia[3]和机遇跳表的 SkipNet[4]等结构相比较,基于多维空间的CAN可以结合网络测量信息和地域信息,有助于解决P2P覆盖网络的拓扑不匹配问题[5]。
内容寻址网络严格的拓扑结构导致其成员结点不正常行为的容忍度相对较低。覆盖网通常可以采用数据冗余[6,7]、缓存和分片的方式来进行容错[8,9],但当前的研究多基于chord协议实现。Sylvia Ratnasamy在其论文[10]中提及了内容寻址网络对于结点失效的处理方法:当结点发现邻居失效的时候,结点就启动TakeOver机制,并同时启动一个计时器。当某一结点启动的计时器超时的时候,该结点将发送包含自己区域大小信息的TAKEOVER消息到网络中,消息将到达失效结点的所有邻居结点。失效结点的邻居结点接收到TAKEOVER消息后,如果自己负责的区域大于发送消息的结点,那么该结点就取消掉计时器和TakeOver机制。反之,回复一个TAKEOVER消息,负责的区域最小的结点将接管失效区域。然而这种协议在恶劣的情况下并不可靠。如果多个结点同时失效,很有可能不能完全恢复失效的区域;另外,如果TAKEOVER消息不能按照设想的情况发送到失效区域的邻居,会发生区域重复被接管的情况,而研究者们并没有针对这种情况提出处理方法。在更为特殊的情况下,如果内容寻址网络由于大面积失效而被撕裂,当前协议难以恢复。本文拟设计一种新的失效恢复机制对这些不足之处加以改进。
本文首先利用霍夫曼树重新组织内容寻址网络的逻辑空间结构,为新的失效恢复机制建立了基础。而后,提出了失效结点的探测机制,保障失效结点实时发现。针对单点失效和多点失效情况,提出了内容寻址网络的失效恢复机制。最后通过实验验证了不同失效比例下,内容寻址网络整体结构均可成功恢复。
2 基于霍夫曼树的内容寻址网络组织方式
内容寻址采用多维空间拓扑结构,多维空间被动态地分配给网络中的结点,每个结点拥有一个属于自己的区域并负责该区域中所有的点。每个节点维护一个路由表,记录多维空间上的邻居信息。内容寻址网络的构建过程是新结点加入和旧结点退出的过程。本节分别针对结点加入过程中的空间划分和结点退出过程中的空间合并进行优化,采用基于霍夫曼编码的组织方式重新组织内容寻址空间,为失效区域恢复机制奠定基础。
空间划分规则中划分维度i是一个小于逻辑空间参数d的正整数,其作用是:对该区域进行划分时,该区域第i维的坐标区间一分为二,分别作为划分后生成的两个子区域的第i维坐标区间。划分过程按照空间区域的维度由低维到高维划分。例如,对空间区域Z进行划分时首先从0维度划分,第二次划分时从1维划分,当达到d-1维度划分后,再次划分又恢复到0维度划分,即划分维度为(i++)%d。标识初始空间编号“#”为根。假设有空间 Z,编号为str。当空间Z在第i维度上被划分后,生成空间z1、z2。并且,z1在第i维上的坐标值小于z2在第i维上的坐标值。那么设其编号为 z1:str+0;z2:str+1。;假设 Z的编号 str为“#101”,则 z1的编号为“#1010”,而 z2的编号为“#1011”。因此如图1所示,在划分逻辑空间的过程中形成一颗霍夫曼树,而树的叶结点代表着每一块空间区域。
空间合并是空间划分的逆过程,指霍夫曼树上两个叶结点取消,其父亲结点变为叶结点的过程。合并规则1:两个区域可以合并当且仅当这两个区域的编号在最后一位不相同 (即为霍夫曼树中的两个兄弟叶结点)。合并规则2:当两个区域合并后,新产生区域的编号为两个区域编号的共同前缀 (即两个兄弟叶结点的父亲结点的编号)。例如:区域 6:“#0110”与区域 7:“#0111”合并后的新区域其编号为:“#011”。需要注意的是,如果区域被合并后,该区域的划分维度也需要改变。假如z1和z2空间区域的划分维度为i,那么合并后的区域的划分维度设置为(i-1)%d。
根据上述的逻辑空间划分、合并方式,按照空间区域的编码可以准确找出两个可以合并的空间。这样对于结点退出后寻找接管结点提供了极为便利的机制,也是失效区域能得以快速恢复的前提条件。
基于霍夫曼的空间组织方法,定义了如下概念。
·区域编号长度G(a):编号字符串的字符串长度。例如区域a的编号为“#1010”,则G(a)=5。
·区域编号公共前缀P(a,b):编号a和编号b的公共前缀,就是指两个区域编号的字符串的公共前缀。例如:区域 a编号为 “#1010”,区域 b编号为“#111”,则 P(a,b)=2。P 具有特性 P(a,b)=P(b,a)。
· 区域编号距离 L(a,b):定义 L(a,b)=G(a)-P(a,b)。a对b的编号距离是a的编号长度减去a和b的编号公共前缀长度所得的值。例如:L(a,b)=G(a)-P(a,b)=5-2=3 ;L(b,a)=G(b)-P(b,a)=4-2=2。L(a,b)与L(b,a)不一定相等。
·区域编号路径:一个逻辑区域的编码路径是指在树形结构上,由树根按照编码编号走向代表该区域的叶结点的路径。
3 内容寻址网络失效结点探测机制
结点正常退出时通知自己的邻居结点,意外失效不会通知邻居结点,而是需要靠邻居结点来发现失效情况。本节设计了结点间相互探测的方法,方便内容寻址网络中的各个结点能够探测到自己邻居的存活情况和邻居结点状态[10]。每一个结点都主动地周期性向邻居发送探测(poke)消息并等待邻居回复响应。探测过程主要分为以下步骤。

第一步:A发送poke请求消息给B,消息中包含自己的结点标识、自己负责的区域信息等。
第二步:B结点接收到消息后,检测A的空间区域与自己的空间区域关系。如果A的区域包含在自己的区域中,则合并A的索引数据,回复消息给A要求A重新加入系统。如果A的区域和自己负责的区域一样,判断两个结点和该区域中点的距离。如果自己的距离近,回复消息,要求A重新加入;否则恢复普通响应消息。如果A的区域不在自己的区域内而是邻居,则回复包含自己的结点标识、负责的区域空间等信息的消息给A。如果A不是自己的邻居,那么回复消息后,删除邻居表中关于A的记录项。
第三步:A接收到响应消息后,如果发现消息让自己重新加入,那么通过区域编号判断标识是否合理(B的区域编号是A的区域编号的前缀)。如果判断结果证明重新加入合理,结点A通知自己的邻居取消邻居表中关于自己的记录项,并重新执行加入过程。如果消息没有提示重新加入或判断结果不合理,则结点A在邻居表中标示B存活。更新B的记录项。
另外,如果超时还没接收到邻居的回复消息,则检测到结点暂时失效。针对该结点启动计数器并继续周期性探测,当对该结点的探测失败次数达到指定阈值时,则认定为邻居失效启动恢复机制。当结点发送消息时,如果发现邻居表中没有存活的邻居(即邻居表内容为空),则将自己负责的区域扩大一倍 (模拟合并兄弟的过程),然后向Bootstrap(或超级结点)发送 Recovery Refresh(恢复更新)消息,再由Bootstrap(或超级结点)转发到网络中,通知其他网络中存活的结点关于自己区域的变化情况。结点间的探测机制处理的算法如下。



探测机制的主要目的是为了探测邻居结点的存活,但同时也承担了系统行为的触发器角色。探测机制的过程中,通过探测结果来触发不同的结点行为可以更新路由表、邻居表,可以消除区域重复等。另外,对于负责区域出现冲突的结点,通过触发重新加入机制让不太合理的结点重新加入网络,对覆盖网的整体性能起到了调优的作用。
4 内容寻址网络单个区域失效恢复机制
单个区域失效是指仅有某个区域失效而与其相邻区域均未失效,其恢复机制如下。
假定结点a意外退出,结点b为a的邻居结点。当b探测到a意外退出后,首先计算a所负责区域的编号与自己所负责区域的编号的距离L(a,b),并根据这个编号距离启动一个倒计时(倒计时的时间长短与L(a,b)值成正比)。如果在倒计时期间接收到了关于失效区域的Recovery Refresh消息,那么取消倒计时。当倒计时超时,启动恢复机制。
恢复机制启动后,结点b首先判断失效结点a所负责的区域是否可以和自己的区域进行合并(根据区域编号判断)。如果两个区域可以合并,则启动合并机制合并失效区域。然后通知自己的邻居这个合并事件,要求更新邻居表和路由表。但是由于不知道失效结点a的邻居,所以设置一个有TTL限制的Recovery Refresh消息向网络中广播,失效区域周围的结点在接收到Recovery Refresh消息后,会检查恢复区域与自己负责区域的关系。如果区域相邻,就将结点b添加到邻居表中,并且更新路由表。图2中的粗实线箭头标示了哪些结点能够探测到区域4的失效情况,如图中所示结点2、3、6、8都可以探测到失效区域。但是由于区域2、3、6、8的编号都不相同,和区域4编号的编号距离L(a,b)也不相同,因此启动的倒计时时间不同。其中,由于结点3和结点4的编号距离最近,因此最先由结点3发起恢复机制。
如图2所示,结点3启动恢复机制后,将合并失效区域4,然后发送合并通知消息到自己的邻居结点1和结点8(虚线箭头所示),并向网络中广播了一条TTL为4的Recovery Refresh消息,以此来通知相应的结点该恢复事件。图中的细实线箭头表示了Recovery Refresh消息广播经过的路径。当结点2、6、8接收到Recovery Refresh消息后,将取消自己关于恢复区域4的倒计时器,并且更新自己的邻居表和路由表。消息到达5、9、10、11的时候,将被这些结点所忽略。
如果检测结点负责区域和失效区域这两个区域不可以合并,则在正常情况下,检测结点所负责的区域比失效区域小,那么检测结点在霍夫曼树上体现为失效结点兄弟子树中的某一个叶节点。这种情况下,检测结点需要查看自己的兄弟结点是否是叶节点(即查看邻居表中有没有结点所负责区域可以和自己的区域合并)。如果有可以合并的邻居结点,那么情况如图3(a)所示:结点10失效,检测到并首先响应的结点是8和9。当结点8和9启动恢复机制后,发现自己不能和结点10负责的区域合并,而同时发现与自己可以进行区域合并的结点在邻居表中,那么结点将会计算逻辑空间的欧几里得距离。如果结点8和结点10所负责区域中的距离比结点9和结点10所负责区域中的的距离要长,那么结点9将接管失效结点10所负责的区域,并且,结点9将自己的空间区域信息等内容发送给结点8,要求结点8合并。最终将形成结点9接管失效区域,结点8负责自己和结点9以前所负责的区域。

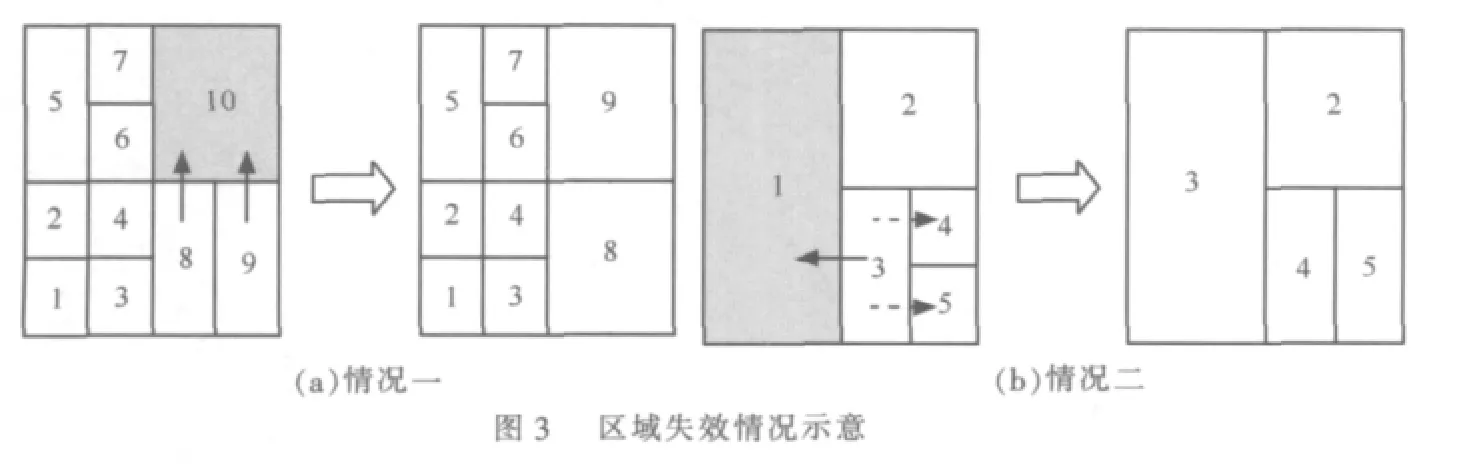
如果自己的邻居表中没有可以和自己所负责区域合并的结点,那么是图3(b)所示的情况:如果结点1失效,那么探测到失效区域并首先启动恢复机制的是结点3(图中粗实线箭头表示探测和启动恢复机制)。但是结点3的邻居表中却没有结点的负责区域可以和结点3的区域合并。因此,设计这样的处理方法:结点3直接接管失效区域,并向自己的兄弟子树中发送leave Request消息。结点4或结点5接收到这种消息后,后续的操作就和结点退出系统时接收到退出请求后的处理方法一样。在上述的图例中,最终的结果是结点3接管了失效区域,结点4接管了结点3的区域,而结点5合并了原来结点4的区域。这些改变都将通过合并通知和恢复通知消息通告给逻辑空间中的结点,以便调整邻居表和路由表。
5 内容寻址网络多个区域失效恢复机制
本节将阐述多个结点失效的情况下,如何进行失效恢复。根据图4的划分情况来分析多个结点失效的复杂情况下恢复机制的运行过程,并最终证明恢复机制是可行的。
第一种情况:兄弟结点同时失效。假设两个兄弟区域7、8均失效,那么根据恢复机制,检测到失效并最早启动恢复机制的结点是结点9和结点10。根据上述的恢复区域选择来说,无论是结点9还是结点10,要恢复的区域是区域7和区域8的合并区域。因此,这个问题就归结到某一区域失效,其处理过程归结为§4单节点失效问题处理机制。
第二种情况:多个非兄弟结点失效。假设区域4、6都失效。那么能检测到失效区域的结点为1、5、11。而且,它们设计的倒计时长度分别为2T、1T和3T。因此,结点5在第一个倒计时周期内就可以先恢复区域6,然后恢复区域4。并且在恢复了区域6以后,结点11接收到关于区域6的Recovery Refresh消息后会取消自己的倒计时。而结点1在接收到关于区域6的Recovery Refresh消息后,就能知道在节点 4、5、6所在子树中有存活结点,则结点 1也可以取消掉自己的倒计时。最终,将由结点5接管4、5、6区域。
第三种情况:有多个结点同时针对一个失效区域启动恢复机制。例如区域11失效时,能检测到区域失效的结点是 5、6、8、10。所设置的等待时间分别为 2T、2T、1T、1T。那么有可能结点8和结点10同时启动对区域11的恢复。而且,按照前面所述,这种情况下,结点8和结点10都将直接接管区域11并且把自己的区域交给兄弟结点7和9合并。这时候,区域11的空间被结点8和结点10所接管,结点8和结点10分别能够接收到对方发送出来的关于区域11的Refresh Recovery消息。
一个结点接收到Recovery Refresh消息后,首先检测自己负责区域和恢复区域的关系。①如果自己负责的区域在恢复区域的内部,那么自己重新加入系统。②如果自己负责的区域和恢复区域相同,判断自己结点坐标与区域中点距离和恢复结点坐标和区域中点的距离。如果自己远,则重新加入系统;如果自己距离更近,则要求对方重新加入系统。③如果自己的负责区域和恢复区域邻接,则取消自己关于该失效区域的恢复倒计时(如果有的话),更新自己的邻居表和路由表。④如果自己负责的区域和恢复区域不相临,则转发该消息。
第四种情况:一个结点的所有邻居都失效。例如区域2、3、5、7、8、10 和区域 11 都失效,那么结点 9 将成为一个孤立的结点。虽然按照恢复机制,结点9会恢复区域10。但是恢复之后仍然是一个孤立的结点,因此邻居表不能够正常地建立,从而不能再通过Poke机制自动触发区域自扩展机制来恢复其他的失效区域。针对这种情况,设计了区域自扩展机制。即当一个结点发现自己的区域成为孤立区域后,将等待一段时间后自动地将自己的区域扩展一倍。扩展之后,再通过广播机制广播自己的区域。如果扩展后能够和其他的存活结点负责的区域邻接,那么区域将不再孤立。如果扩展后还处于孤立的情况,那么将重复上述的区域自扩展过程,直到不再孤立为止。
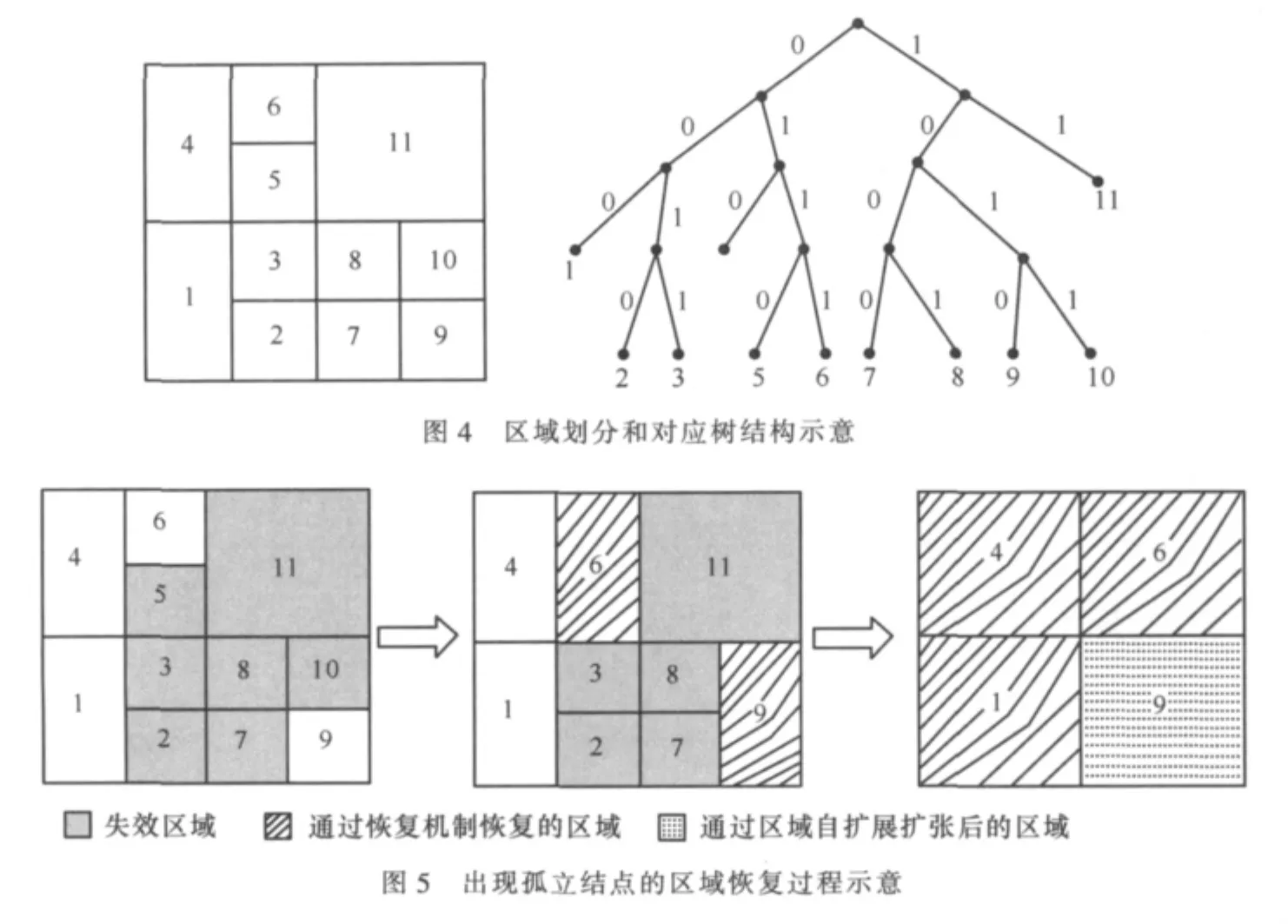
然而,当结点处于孤立的情况下,邻居表为空,那么它的更新消息如何发送到内容寻址网络中的其他结点呢?为了解决这个问题,在系统中保留了一个(或多个)周知结点(或超级结点[11])。每个结点都知道这个周知结点,并且周知结点也知道逻辑空间中存活的所有结点。那么当结点被孤立的时候,它所发送的所有更新通知消息都将通过周知结点转发到网络中。这样一来,孤立区域最后将恢复所有的失效区域,并再次融入到整个逻辑空间中。
区域恢复过程的情况如图5所示。每一幅图是一个处理周期后的情况。由图5可知,当第一个周期过后,结点9恢复了兄弟结点的区域10,结点6恢复了兄弟结点区域5。恢复之后,区域9仍然是鼓励结点,因此,它会采取区域自扩展的方式扩张自己负责的区域。而同时,结点6关于失效区域11的倒计时结束,结点1关于失效区域2、3的倒计时也结束,于是都启动了恢复机制。最后在第三个操作周期之后,形成了上述的区域划分关系,整个逻辑空间得到了完整的恢复。
6 实验与结果分析
本节以PlanetSim[12]作为仿真实验平台,加入系统的结点数为100结点,向系统中添加的数据资源对象为2 000个资源,内容寻址网络逻辑空间设置为2维,逻辑空间的区域范围为0~220。
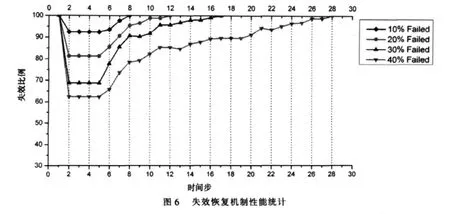
为了测试失效恢复机制,在内容寻址网络中,随机地选取一定量的结点,并让其意外退出,以此来模拟网络中结点突然失效的情况。接下来,周期性地检测网络的覆盖状况,以此来判断内容寻址网络中剩余的结点对网络失效区域的恢复情况。本文把实验过程中的每一次检测周期称为一个时间步(time step)。实验中分别尝试了失效比例为10%、20%、30%和40%的情况,检测的数据情况如图6所示。
图6中,第一时间步骤为结点集体失效,导致逻辑空间覆盖区域比例下降,所以统计曲线急速下降。在第2~5这4个时间步骤内,失效结点周围的邻居结点正在探测和判断结点的失效情况是否是实情。当邻居结点确定区域失效的时候,将启动恢复机制。因此在该区域,覆盖网被覆盖的比例保持失效后的情况不变。从第6个时间步骤开始,失效恢复机制开始体现作用,并随着时间的推移,逐渐地将失效的区域分配给内容寻址网络中存活结点接管,最终恢复内容寻址网络的整体结构。
通过统计图可以看出,失效结点越多,恢复其所接管区域耗费的时间就越长。但是无论如何,本文提出的恢复机制最终都能够恢复覆盖网的整体结构,实验结果证明该恢复机制是有效可行的。在传统的失效恢复方法下,在大量结点失效的情况下会出现覆盖网结构破坏甚至撕裂而形成数个子网[13],而本文所设计的失效恢复机制突破了传统方法这一缺陷,解决了参考文献[13]所提及的覆盖网组织缺陷问题。
7 结束语
本文设计的基于霍夫曼编码的内容寻址空间组织方式可以便捷准确地确定结点和邻居的关系,并根据该编码,指导恢复机制的运行,确保能够完整地恢复整个逻辑空间,避免出现逻辑空间缺失区域的出现。本文所设计的恢复机制可以解决大量结点失效时出现的内容寻址网络崩溃或覆盖网断裂的问题,保障其应用于互联网环境之中的稳定性。
1 RathasamyS,FrancisP,HandleyM.A scalablecontentaddressable network.In:Proceedings of the ACM SIGCOMM’01,Washington,2001
2 Stoica I,Morris R,Karger D,et al.Chord:a scalable peer-topeer lookup service for Internet applications.Technical Report,TR-819,New York:MIT,2001
3 Maymounkov P, Mazieres D. Kademlia: a peer-to-peer information system based on the XOR metric.In:Proceedings of the 1st Int'l Workshop on Peer-to-Peer Systems (IPTPS 2002),New York,2002
4 Harvey N,Dunagan J,Jones M B,et al.SkipNet:a scalable overlay network with practical locality properties.In:Proceedings of the USENIX Symp on Internet Technologies and Systems(USITS),Seattle,2003
5 Ren S S,Guo L,Jiang S,et al.SAT-Match:a self-adaptive topology matching method to achieve low lookup latency in structured P2P overlay networks.In:Proceedings of the 18th Int’l Parallel and Distributed Processing Symp (IPDPS 2004),Santa Fe,New Mexico New York,2004
6 Cohen S S.Replication strategies in unstructured peer-to-peer networks.Edith Sigcomm,2002
7 Qin Lv,Pei Cao,Edith C,et al.Search and replication in unstructured peer-to-peer networks.In:Proceedings of the 16th ACM International Conference on Supercomputing (ICS),New York USA,June 2002
8 Boris M,Peter V R.A relaxed-ring for self-organising and fault-tolerant peer-to-peer networks.IEEE ComputerSociety,2007
9 Zhuang S Q,Zhao B Y,Joseph A D,et al.Bayeux:an architecture for scalable and fault-tolerantwide-area data dissemination.In:Proceedings of the NOSSDAV 2001,2001
10 Rathasamy S.A scalable content-addressable network.A dissertation submitted in partial satisfaction of the requirements.The Degree of Doctor of Philosophy in Computer Science in the Graduate Division of the University of California at Berkeley,Fall 2002
11 Beverly Y,Hector G M.Designing a super-peer network.In:19th InternationalConference on Data Engineering,IEEE computer society,Bangalore India,2003
12 Jordi P A,Marc S A,Pedro G L.PlanetSim user and developer tutorial,http://ants.etse.urv.es/planetsim,2008
13 Stefan S,Gummadi P K,Gribble S D.Measuring and analyzing the characteristics of napster and gnutella hosts.Multimedia Systems,2003,9(2):156~170
张伟哲,副教授,博士,主要研究方向为网络计算、并行与分布式系统;张宏莉,哈尔滨工业大学大学博士生导师,主要研究方向为网络安全、网络计算;吴太康,硕士,主要研究方向为对等网络;许笑,哈尔滨工业大学大学博士生,主要研究方向为对等网络。
2010-06-30)
猜你喜欢
少儿美术(2019年5期)2019-12-14 08:04:52
深圳职业技术学院学报(2018年2期)2018-09-08 05:57:26
数学物理学报(2018年1期)2018-03-26 08:16:42
小学教学研究·新小读者(2015年6期)2015-06-16 19:40:54
电子设计工程(2014年12期)2014-02-27 11:58:23
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
科技经济市场(2006年6期)2003-03-17 01:51:26
