
电信客户流失预测模型研究
2010-04-16 09:15路美秀李锋向仍涛
电脑与电信 2010年6期
路美秀李锋向仍涛
(1.广东外语外贸大学信息学院,广东广州510006;2.广东工业大学应用数学学院,广东广州510006;3.广东电信,广东广州510000)
1.引言
目前在全球电信业发展处于低迷的情况下,我国不断深化改革电信行业,对电信运营企业进行重组。各电信企业一方面投入大量时间、人力、财力去发展新客户,另一方面因客户流失管理的不完善导致现有客户流失。如何保留住既有客户,及如何从这些客户获得最大的收益,将成为国内电信企业重要的课题。本文结合电信业务规则,对基于数据挖掘的流失预测模型进行了合理的分析和应用,使企业对流失客户能够采取更有效的营销策略。
2.客户流失预测模型
二十世纪末,一些软件供应商和用户成立了行业协会,包括NCR Systems Engineering Copenhagen(丹麦)、Daimler-Benz AG(德国)、SPSS/Internal Solutions Ltd(英国)和OHRA Verzekeringen en Bank Grep B.V(荷兰),这个组织建立了数据挖掘的过程模型CRISP–DM(Cross-Industry Standard Process-Data Mining)[1],CRISP-DM方法把数据挖掘看作一个商业过程,将一个数据挖掘项目的生存周期定义为六个过程,分别为:商业理解(Business Understanding)、数据理解(Data Understanding)、数据准备(Data Preparation)、建立模型(Modeling)、模型评估(Evaluation)、结果发布(Deployment)。
本文以此模型为参考,选择SPSS公司的Clementine工具进行数据预测模型的建立,数据处理采用了Sybase公司的IQ数据仓库。
3.数据挖掘模型应用
3.1 商业理解和环境评估
电信行业的客户流失可分为两种:客户被动流失与客户主动流失。客户被动流失表现为电信运营商由于客户欺诈或恶意欠费等行为而主动终止客户使用网络和业务。而客户主动流失分为如下几种情况:客户不再使用任何一家电信运营商的电信业务;客户选择了另一家运营商;客户转移至本电信运营商的不同网络、不同业务或不同品牌等。为了减少客户流失,需整合用户信息,对用户进行合理的分类和识别。本次客户流失预测主要是针对电信行业的流失客户。
3.2 数据理解和准备
为了建立客户流失模型,必须收集所有的原始数据,并将其转换成数据模型所需的格式——数据挖掘目标表,此阶段称为数据预处理阶段或数据准备阶段。此项目采用某地市电信企业6个月的数据作为训练数据。
针对被动流失客户(即欠费销户)建立模型,对一般客户而言,若因欠费停机,并且在3个月内没有还款,最后会被欠费销户。对于这类欠费销户的客户,为了能考察到他们的行为变化,选定了在欠费销户月份之前的倒数第4~9个月这6个月作为观察的时间窗口。
3.2.1 变量选择和设计
根据电信客户流失的业务特征,电信客户流失的数据挖掘目标表通常需要如下变量:客户流失的状态变量Y;个体鉴别变量X1;人口统计变量X2;客户行为变量X3。将这些行为变量加以整理可归纳为以下几类来描述[2](本地通话的行为变量;省内、国内漫游通话的行为变量;港澳台、其它国家漫游通话及国际、港澳台长途的行为变量;呼转及呼叫。反映客户呼转到不同电信运营商的情况,客户呼叫不同电信运营商的情况;数据业务的使用情况;通话号码数;客户的总体主被叫行为等);进一步的衍生变量X4。建模的目的就是要分析、确定这些向量变量与客户流失状态变量Y的关系,即:Y=F(X1,X2,X3,X4)。
3.2.2 数据挖掘过程
进行知识挖掘时[3],先从原始数据集合(这里指数据挖掘目标表)中取出一个与探索的问题相关的样本数据集,经过数据抽样后,把样本数据分成训练数据集(Train Data Set)和校验数据集(Validation Data Set)。训练数据集实现初步的模型适应,可以由此找出较好的模型权重。校验数据集用于评估模型是否适当。数据探索阶段的任务包括:数据质量检查、数据的必要整理、通过图形化呈现工具和其它的统计方法理解数据、分析候选自变量和目标变量之间的关系、数据转换以辅助数据的分析、数据派生为建立模型做准备、整理和呈现数据探索的发现。通过数据抽样、数据探索两个步骤对数据的状态有了进一步的了解后可以按照问题的具体要求对数据进行修正,如增删、组合或者生成一些新的变量等。例如由于客户没有使用某一业务而造成该变量值的缺失,可直接对缺失值进行补零处理。根据对变量的观察和实际的业务需求,去掉与变量均值相差大于或等于若干个标准偏差的观测记录,避免极端值影响后面的分类、预测模型的精度。
4.数据建模
根据数据集的特征和要实现的目标,本文采用因子分析与回归、决策树等方法结合的建模策略。通过两次因子分析(Factor Analysis),研究客户变量的相关矩阵或协方差矩阵,将多个客户变量综合为少数几个因子,进而获得代表主要因子的原始变量,利用这些原始变量建模,获得最终的流失模型结果。在最后的流失建模中,对由因子分析筛选出来的原始变量再用决策树模型挑选一次,然后把结果放到Logistic对数回归模型里得到最终结果。这个过程是通过反复尝试得到的。决策树(Decision Tree)中的每个内部节点(internal node)表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点(leaf)代表类(class)或类分布(classdistribution)。用决策树表示客户是否流失,而叶节点用椭圆表示,用它可以预测某条记录(某个客户)的流失意向。在确定输入变量之后,运行模型建立流失预测模型(见图1)。

图1 模型结果
下面对模型的规则研究,试图从中总结规则与实际业务的关系,决策树流失模型的决策树(见图2):

图2 决策树

图3 产生规则
我们发现在产生的规则中(见图3),接入时长趋势、竣工月份数(入网时间)、品牌等都是出现频率高的字段,这些字段在预测模型中应为重要变量。另外,品牌和欠费次数也是影响流失的重要因素。
5.模型评估
此模型是对目标问题多个侧面的描述,但要形成最终的决策支持信息,还需要对这些结果和模型进行综合的解释。如可以扩大样本的范围,检验模型是否仍然满足。如果通过检验发现第一次构建的样本数据不具有充分的代表性,或模型本身不够完善,就需要重新进行数据挖掘,因此,数据挖掘是反复进行的过程。
建模后要对各个模型进行比较评估,得出最佳的模型。这里我们把客户按照预测的流失概率P由高到低进行排序,顺序等数量分成N组客户,对三种评价指标:提升率、查全率、命中率计算相应的累计指标,我们主要使用累计提升率(Cumulative Lift)(即累计流失数量与每百分段值累计平均流失数量的比值)进行模型评估。对决策树模型、神经网络模型和没有进行建模的数据进行评估比较,累计提升率的计算比较结果(见图4、图5):
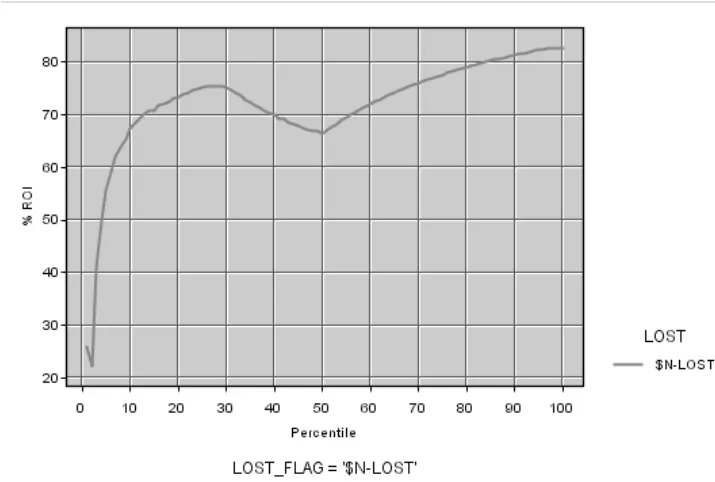
图4 神经网络模型

图5 决策树模型
在按照预测的流失概率由高到低进行排序的全体客户的前10%,20%,30%,40%,50%中,神经网络建模的累计提升率比决策树建模要稍好。将客户按照回归模型预测的流失概率P由高到低进行排序,等数量分成10组客户,其前几个百分段分组的客户流失预测精度较高,由此可以选取此段的目标用户清单来进行处理,当然辅助决策人员和业务人员还需要根据业务处理能力以及工作成本来选定客户范围进行客户挽留工作。
由模型评估中也发现,该客户流失模型对未流失客户的预测比较好,但对流失客户的预测还不够理想。这与客户数据中流失客户比较少以及现在取得的客户数据资料还不够完备有关。建议将来进一步优化客户流失模型时,能够获得更多客户的相关数据资料,并且可以把最近几个月(例如:3个月)内的所有流失客户一块进行分析,这样可以更好得到流失客户的数字特征,改善模型的效果。在建模过程中,还可利用已经得到的模型去预测下个月的主动流失的客户,以便进一步检测模型的稳定性。
6.模型发布与应用
这个阶段主要任务是将模型的结果交付于管理者,为决策提供支持。一般情况下需要将模型结果可视化,而模型的业务分析需要由业务专家结合自己的经验完成,以提供更为可行的决策计划。为了针对模型选定的客户流失关键因素,有针对性地设计挽留营销方案,可采用如下方式:将由客户流失模型预测的流失倾向较高的客户分为n-1个组,一个组是无行动组,只占总客户的10%,这部分客户不采用任何的挽留措施,纯粹为了观察流失模型的效果:将剩下的90%的客户分为n个组,可对这n组客户分别采用不同的挽留措施,保持一段时间之后观察挽留效果。最后根据不同挽留措施的效果,进一步完善营销策略。在具体挽留工作中,可综合考虑客户的流失风险和客户价值两个因素,优先对高价值且高流失风险的客户进行挽留。
在模型应用过程中,可以先选择一个试点,试点应用期间随时注意模型应用的收益情况,一旦发生异常偏差则立即停止应用并对模型进行修正。试点结束后,若模型被证明应用良好,可以考虑大范围推广。在模型应用一段时期或经济环境发生重大变化后,模型的偏差可能会增大,这时应该考虑重建适用性更强的模型。
7.结论
数据挖掘工具作用的发挥依赖于商业数据采集的准确性,本文主要以某地市电信企业的客户为目标用户群,由于企业级的数据仓库还在建设中,一些相关的原始数据还没有采集到,此模型最后产生的数据作用还不是很准确和全面。另在客户流失模型的建立中,还需要考虑各个变量的交互作用对模型的影响,可使用逻辑回归等其它算法进行尝试。
[1]郭亮.用CRISP-DM模型来规范企业数据中心建设[J].华北科技学院学报,2008,(10):69-72.
[2]耿庆鹏,卢子芳.利用数据挖掘技术实现对电信行业用户欺诈行为的预测[J].电信快报,2003,(10):40-42.
[3]李丙春,耿国华.数据仓库与数据挖掘在电信业中的应用[J].新疆大学学报(自然科学版),2002,(8):46-47.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年17期)2018-09-28
电子制作(2018年16期)2018-09-26
通信电源技术(2018年5期)2018-08-23
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
