
一种基于集成学习与类指示器的文本分类方法
2010-03-20 07:18蒋宗礼徐学可
北京工业大学学报 2010年4期
蒋宗礼,徐学可
(北京工业大学计算机学院,北京 100124)
一种基于集成学习与类指示器的文本分类方法
蒋宗礼,徐学可
(北京工业大学计算机学院,北京 100124)
提出了一种基于集成学习机制与类指示器的文本分类方法.该方法利用 AdaBoost.MH算法框架,在每一轮次中,自适应地计算类指示度,通过加权组合所有成员类指示度,获得对理想类指示度的一种逼近.利用最终的类指示度所得到的分类器不仅简单、易于更新,而且泛化能力强.在标准语料集TanCorp-12上的实验表明,该方法适用于对分类效率要求较高的实时应用,同时可以利用集成学习进行某些知识的精确学习,并将这些知识用于弱分类器,从而实现简单高效的分类.
机器学习;集成学习;AdaBoost.MH;文本分类;类指示器
大规模在线文本分类、文本信息检索、过滤等实时性要求强的应用往往需要泛化能力很强,简单、快速、高效、易于更新的文本分类方法,目前很少有符合要求的.支持向量机(supportvectormachine,SVM)虽然具备较高的泛化能力,但训练与分类的过程过于复杂,而基于向量空间模型(vector space model,VSM)[3]相似度的分类器虽然简单,但分类性能往往达不到实际需求.虽然集成学习技术可以将弱分类器提升为泛化能力很强的强分类器,但大大提高了计算复杂性.作者首先将文本特征视为类指示器,相应定义了类指示度函数并提出一种基于类指示器的文本分类方法,然后利用集成学习的方法,获取更精确的类指示度函数,在此基础上构造等价于集成分类器的分类系统,使其既具备集成分类器泛化能力高的特点,又保持简单、快速易于更新的优点.
1 集成学习相关介绍
集成分类器可分为使用同类型单分类器的集成分类器和使用不同类型单分类器的集成分类器.使用同类型单分类器的集成分类器根据成员分类器生成方式的不同,大致分为 2类.一类以 AdaBoost[4]为代表,在这一类算法中,成员分类器顺序生成和执行,一个分类器的结果对下一个分类器产生影响.另一类以 Bagging[5]为代表,成员分类器可以并行生成和执行,算法用可重复取样技术(bootstrap samp ling)生成与原来样本集中的样本个数相同的新样本集.
Boosting、AdaBoost与 AdaBoost.MH是一类集成学习器.Boosting包括了一系列算法,其基本策略是将一个比随机猜测略好的弱学习算法提升为强学习算法,不必直接去找通常情况下很难获得的强学习算法.Adaboost[4]是其中最具代表性的一种,AdaBoost将样本集{(x1,y1),…,(xm,ym)}作为训练数据,其中 xi是问题空间 X中的实例,yi∈{-1,+1}是 xi的类别标签.AdaBoost在训练实例空间 X上维护一个权重分布,在初始化时对每个样本赋相等的权重 1/m,然后用样本集对成员分类器进行训练,每次训练后,对训练失败的样本赋以较大的权重,以便在后面对比较难的样本集中学习,从而得到一个预测函数序列 h1,…,hT,其中 hj也有一定的权重.预测效果好的预测函数权重较大,反之较小.最终的预测函数 h采用有权重的投票方式对新实例进行类属判别.
AdaBoost.MH[2]将成员分类器定义成 h∶X×Y→R形式,并在 X×Y上维持一个 |X|×|Y|的权重分布.推广 AdaBoost使它能处理多类多标签分类问题,实际上是将 X×Y的成员作为推广的实例形式,在推广实例(xi,yi)上,成员分类器的输出是对训练实例 xi属于 yi类的支持度的判断.若输出值大于 0,表示支持xi属于 yi类;若输出值小于 0表示支持 xi不属于 yi类.输出值的绝对值越大则可信度越高.它在推广实例集上维护权重分布,这样就将多类多标签化为二类单标签问题.AdaBoost.MH在 AdaBoost框架下运行,可以看成 AdaBoost的推广形式,AdaBoost中的一些结论也适用于 AdaBoost.MH.
Schapire等[2]将基于决策树桩 (decision stump)的 AdaBoost.MH集成算法用于文本分类系统BoosTexte.它的成员分类器根据某个单词出现与否给当前文本赋予一实数值,用于进行文本的类别可信度预测.文献[6]对此做了改进,将词频分类器集成应用于文本分类.
2 基于类指示器的文本分类方法
进行文本分类往往需要抽取一系列特征来表示文本.这些特征往往跟类别存在一定关联,起着类指示器作用.设文档集 D,特征集 F,类别标签集 C,定义类指示度函数 I∶F×C→(-1,1)用于度量这种关联,I(f,c)>0时表示特征 f与类 c正关联,即表示特征 f在文档 d中的出现对 d为 c类起支持作用;反之特征 f与类 c负关联,表示特征 f在文档 d中的出现对 d为 c类起反对作用.分类器 h∶D×C→R,h(d,c)为文档 d包含的所有特征的关于类 c的指示度的加权和,表示 d为 c类的可信度,取可信度最高的 c作为d的类标签.定义权重函数,其值由特征在文档中的重要程度及特征本身的类区分度决定 w∶D×F→[0,1],w(d,f)表示文本 d关于特征 f的权重.值得说明的是本文采用词作为其特征,实际上,特征可以是关键短语、n-gram、词组、领域词典中的领域关联词等,他们具备一定类指示作用.
算法 1 基于类指示器的分类方法(category indicator based method,CIM)
假设∀〈f,c〉∈F×C,I(f,c)已经事先计算
初始化:h(d,c)=0
输入:d∈D
显然这是一种相当简单、快速、高效的分类方法,同时也易于更新,只要提取对新特征的类指示度,并添加到特征库中,便可完成对分类模型的更新,这在网络时代中新词不断出现的情况下尤其重要.但该方法中类指示度的学习过于依赖训练集的规模与质量,可能难以有效处理新例,泛化性能低.本文期望利用集成学习的方法,获取更精确的类指示度,在此基础上构造等价于集成分类器的分类系统,使其既具备集成分类器泛化能力高的特点,又能保持简单、快速易于更新的优点.
3 算法框架
本文的工作以 AdaBoost.MH作为集成学习的框架,不同于 Schapire,这里的成员分类器采用综合考虑文本所有特征的基于类指示器的方法,来获得更精确的类指示度函数,并以此构造最终的分类器,与一般集成分类器相比,它不需要在执行过程中对各成员分类器的加权融合.基于 AdaBoost.MH框架,随着权重分布的自适应更新,每一轮的类指示度函数的学习重点考虑那些权重较大的文档,相应的分类器更多体现这些样本的特性,各轮的类指示度函数及相应分类器侧重不同训练空间的特性,具备一定的差异性,将各轮的类指示度函数加权融合,得到的分类器具有较高的稳定性与泛化能力.
3.1 主要思路
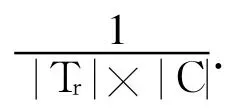
3.2 算法
算法 2 基于集成学习的 CIM
for t=1,…,T;T为事先确定的迭代次数
1)基于权重分布 Wt(di,cj)(i=1,…,g,j=1,…,m)学习类指示度函数,It∶F×C→(-1,1)
2)基于类指示度函数,得到成员分类器 ht∶D×C→R

3)评估成员分类器 ht
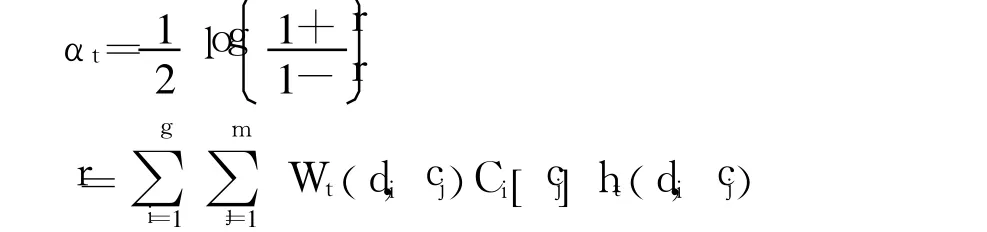
若 cj∈ Ci返回 Ci[cj]=1否则 Ci[cj]=-1
4)更新权重分布
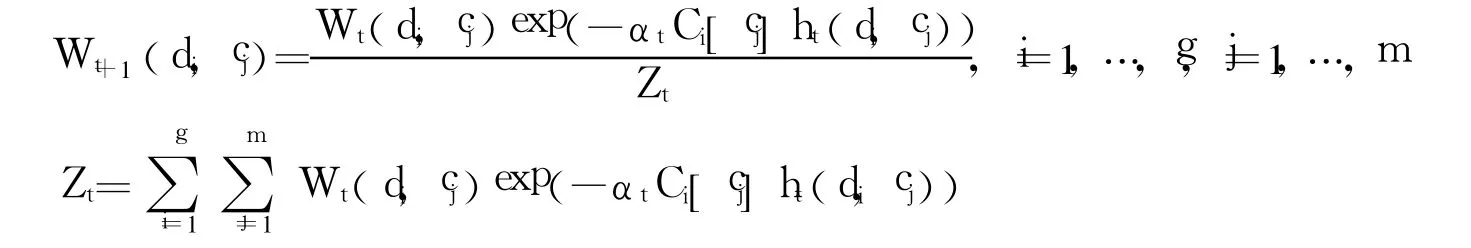
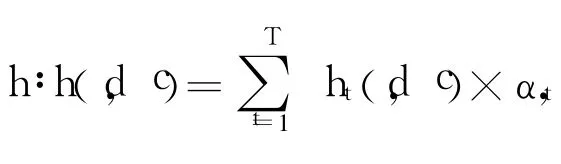

因此,这 2种分类器是等价的,而利用 h分类时需要存储 T个分类模型,分类时需用每个成员分类器进行分类并对其结果加权融合,时间与空间开销大,利用 h′分类时,只需存储一个分类模型(特征的类指示度可以事先计算并存储),进行一次分类过程,时间与空间开销大为减少,同时具备集成分类器泛化性能高的优点.
3.3 权重函数及类指示度函数
3.3.1 权重函数
在向量空间模型(vector space model,VSM)[3]中,用向量表示文档,它的每一维对应于文档的一个特征项,特征项的权重一般与特征项在文档中的重要程度以及特征项的类区分能力有关,一般采用 TF-IDF方法计算,该方法简单地认为文本频数少的特征项重要显然过于武断.如果以特征选择中的评估函数代替 IDF函数,对特征项进行权值调整,就有希望得到高质量的向量空间法[7],本文采用互信息(mutual information,MI),以文档 d改进的 VSM中表示特征 f的权重作为 w(f,d)的值

式中,tf(fi,d)定义为 fi在 d中出现频率;m(fi)为 fi的互信息评估函数值;f1,…,fn为 d包含的特征.另外,本文的特征选择也采用互信息.
3.3.2 类指示度函数
方法1
该方法受特征选择中的互信息方法启发,设

式中,Pr(f)表示特征 f在训练文本集合中出现的概率;Pr(f|c)表示在 c类的文本中 f出现的条件概率,当Pr(f|c)>Pr(f)时 Pr(f|c)>0,表示特征 f与类别 c正关联,反之表示负关联.采用比值的方式可以比较纯粹的学习特征的类关联性,而与特征的频度无关.
类指示度函数为

式(4)将 m(f,c)映射到(-1,1),避免 m(f,c)值之间的过大差异,防止个别特征对分类结果影响过大,保证分类器的稳定性.
在 AdaBoost.MH每一轮次中,都要根据新的权重分布,重新计算 Pf(f|c)与 Pr(f),从而实现类指示度的自适应调整.

式中,Wt表示第 t轮次的权重分布;n(d,f)为 f在文档 d中出现次数.
方法2
文献[2]中的决策树桩分类器按一定标准选择某个词,分类器以该词的出现与否给当前文本赋予实数值,实现文本的判别,受其赋值公式启发,设计了类指示度函数
设 Df={d|d∈ D,f∈ d},令

式中,Cd表示文档 d的类标签集;(f)表示子集 Df中标记为 c类的文档权重之和(f)表示子集 Df中不被标记为 c类的文档权重之和;Wc为在权重分布 W基础上调整所得,满足,其中表明 c类文档的权重和与其他文档相同.可以对 c类文档进行如下调整


3.4 分类的时间复杂度
该方法利用特征类指示度构造最终的分类器,与集成分类器相比,它不需要在分类过程中对各成员分类器的加权融合.
总的分类过程步骤为:1)检索到每个文档特征相应的类指示度;2)对每个类别把所有特征关于该类的指示度加权和作为文档为该类的可信度;3)取可信度的类作为文档的类标签.利用 Trie树等高效的检索数据结构,可以在常数时间找到某特征的指示度,因此步骤 1)时间复杂度为 O(|Fd|)(Fd为文档 d的特征集),总时间复杂度为 O(|Fd|×|C|).考虑类别数固定,总时间复杂度可为 O(|Fd|),表明这是一种线性分类器,适用于在线分类.
3.5 算法的进一步改进
值得注意的是,Boosting和 Bagging的迭代轮次数并非越多越好,学习系统性能的改善主要发生在最初的若干轮次中.Schapire和 Singer指出,迭代次数过多,AdaBoost.MH有可能发生过适应[8].实验过程中也发现文本的方法迭代次数较少时,性能提升明显,随着迭代次数进一步增加,性能反而下降.通常可以构建验证数据集,取验证数据集性能最优的迭代次数作为最终参数.
这是由于 AdaBoost算法存在类权重分布扭曲的现象,导致对个别类的过度重视以及对其他若干类的偏见,生成的预测规则在测试集上的分类错误急剧增加,发生退化现象[9].本文的训练过程中也出现了该现象,作者对 AdaBoost.MH进行改进,在一定程度上缓解了该问题,方法是经过若干轮次迭代后调整权重分布,然后对分布进行归一化.调整公式为

4 实验和讨论
实验采用 TanCorp-12语料集[10-11].该语料包含 12类,共有 14 150篇文档.12类分别为财经、地域、电脑 、房产 、教育 、科技 、汽车 、人才 、体育 、卫生 、艺术与娱乐 .
作者利用经典集成学习技术,目标是获取既有较高分类性能又有较高分类效率的文本分类方法.首先,将本文的方法跟目前主流分类方法做性能比较.作者用精度(precision)考查分类器在各个类别上的性能,并用微 F1值(Micro-F1)考查综合性能[12].将本文方法与常见的中心法(centroid)[13],Rocchio法[14],K-最近邻法 (k-nearest neighbors,KNN)[15],朴素贝叶斯法 (naïve bayes,NB)[16],支持向量机法(supportvector machine,SVM)[17],决策树法(decision tree,DT)(具体采用 SPRINT决策树算法[18])等进行比较.其中 KNN方法参数 K的取值为 15,SVM方法采用开源工具 LibSVM[19],核函数采用 linear kernel,其他参数取默认值.将采用方法 1作为类指示度计算方法的分类方法记为 CIM1,采用方法 2的记为CIM2,把整个语料随机分成 5份,然后取其中的 2份进行训练,剩余取1份作测试.采用 MI方法进行特征选择,具体的评估函数为
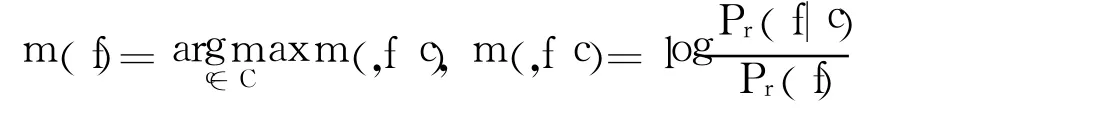
式中,Pr(f)表示特征 f在训练文本集合中出现的概率;Pf(f|c)表示在 c类的文本中 f出现的条件概率,取词频超过 15的前 5 000个词作为候选特征.CIM 1与 CIM 2的迭代次数为 100.
从结果看出 CIM1,CIM 2都表现出较高的性能,其中 CIM1的 Micro-F1指标仅次于 SVM和 Rocchio,而CIM2甚至接近目前公认文本分类性能较好的 SVM,见表 1.此外 CIM2方法性能好于 CIM 1,是本文推荐的方法.

表 1 本文方法与经典文本分类方法性能比较Table 1 The com parison of the p roposed methods and traditionalmethods
CIM2方法性能略低于 SVM,但该方法的最大优势在于分类效率,是一种线性分类器,适用于在线分类.3.4节给出其算法时间复杂度分析,此外还记录了 CIM 2与 SVM算法测试时间(这里时间开销为分类过程开销,不包括算法无关的文本预处理时间,实验机器配置为 Pentium-4,2.3GHz CPU及 1 024M内存的机器上,开发环境为 Java JDK1.6)分别为 78和 116032ms,可以明显看出 CIM2时间开销远小于 SVM.此外,本文的方法仅是一种框架性方法,其中类指示度函数的计算方法是开放,选取更合理的类指示度函数及权重函数还可以进一步提升分类性能.
基于改进的 AdaBoost.MH的 CIM2,记为 CIM2-Adv,与 CIM2方法相比,CIM2-Adv每经过 40轮次迭代后用式(8)调整权重分布.图 1给出了 CIM2-Adv与 CIM2方法取不同迭代次数 T时 Micro-F1指标变化情况.
从图 1可以发现:1)迭代次数较少时,CIM2-Adv性能不如 CIM2,表明原有的权重自适应更新机制更加有效,式(8)在一定程度上破坏了原有的Boosting机制,导致性能不理想;2)随着迭代次数增加,CIM2出现性能退化现象,而 CIM2-Adv性能依然保持上升趋势,最终 CIM 2-Adv的性能超过 CIM2最佳性能,表明本文提出的方法在一定程度上缓解了经典方法权重扭曲问题.
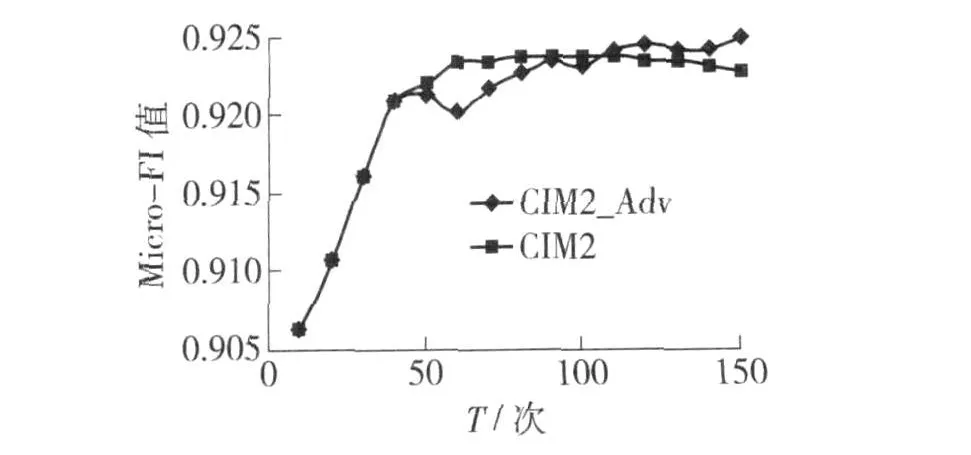
图1 CIM 2-Adv与 CIM 2方法 Micro-F1指标依迭代次数 T变化Fig.1 The Micro-F1 values of CIM 2.Adv and CIM 2 with different iteration count T
5 结束语
集成学习的动机就是将弱分类器提升为高泛化性能的强分类器,但大大增加了计算复杂性.为了解决该矛盾,本文提出基于集成学习机制与类指示器的文本分类方法.该方法利用 AdaBoost.MH算法框架,在每一轮次中,自适应地计算类指示度.通过加权组合所有成员类指示度,获得对理想类指示度的一种逼近.基于最终的类指示度,得到的分类器不仅简单易于更新,同时也获得了集成分类器泛化能力强的优点.考虑到它的简单性,适用于对分类效率要求较高的实时应用.针对 AdaBoost权重分布扭曲现象本文对 AdaBoost.MH进行改进,取得初步效果.结果也表明,利用集成学习进行某些知识的精确学习,并将这些知识应用于弱分类器,可以获得简单高效的分类模型.本文的方法是仅仅一种框架性方法,类指示度函数的定义是开放,如何定义更加合理的类指示度函数是进一步研究的内容.
[1]DIETTERICHL TG.Machine learning research:four current directions[J].AIMagazine,1997,18(4):97-136.
[2]SCHAPIRE R,SINGER Y.BoosTexter:a boosting based system for text categorization[J].Machine Learning,2000,39(203):135-168.
[3]SALTON G,WONG A,YANG C.A vector spacemodel for automatic indexing[J].Commu of ACM,1995,18:613-620.
[4]FREUND Y,SCHAPIRE R E.A decision-theoretic generalization of on-line learning and an app lication to boosting[J].Journalof Computer and System Sciences,1997,55(1):119-139.
[5]BREIMAN L.Bagging p redictors[J].Machine Learning,1996,24(2):123-140.
[6]姜远,周志华.基于词频分类器集成的文本分类方法[J].计算机研究与发展,2006,43(10):1681-1687.JIANG Yuan,ZHOU Zhi-hua.A text classification method based on term frequency classifier ensemb le[J].Journal of Computer Research and Development,2006,43(10):1681-1687.(in Chinese)
[7]FRANCA D,FABRIZIO S.Supervised term weighting for automated text categorization[C]∥Proceedings of the 2003 ACM Symposium on Applied Computing.Melbourne,Florida:ACM Press,2003:784-788.
[8]SCHAPIRE RE,SINGER Y.Improved boosting algorithms using confidence-rated predictions[J].Machine Learning,1999,38:297-336.
[9]GUINLAN J R.Bagging,boosting,and C4.5[C]∥Proceedings of the Thirteenth National Conference on Artificial Intelligence.Portland,Oregon:AAAI Press and the MIT Press,1996:725-730.
[10]谭松波,王月粉.中文文本分类语料库-TanCorpV 1.0[DB/OL].http:∥www.searchforum.org.cn/tansongbo/corpus1.php TANSong-bo,WANGYue-fen.A corpus for Chinese text categorization-TanCorpV1.0[DB/OL].http:∥www.searchforum.org.cn/tansongbo/corpus1.php(in Chinese)
[11]TAN Song-bo.A novel refinement approach for text categorization[C]∥ACM CIKM 2005.Bremen,Germany:ACM Press,2005:469-476.
[12]SEBASTIAN F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[13]HAN E,KARYPISG.Centroid-based document classification analysis& experimental result[C]∥PKDD 2000.Lyon,France:Springer Berlin/Heidelberg,2000:116-123.
[14]JOACHIMS T.A probabilistic analysis of the rocchio algorithm with TFIDF for text categorization[C]∥Proceedings of International Conference on Machine Learning(ICML).Nashville,Tennessee,USA:Morgan Kau fmann Publishers Inc,1997:143-151.
[15]YANG Y,LIU X.A re-examination of text categorizationmethods[C]∥Proceedings of ACM SIGIR Conference on Research and Development in In formation Retrieval(SIGIR'99).Berkley,USA:ACM Press,1999:42-49.
[16]MLADENICD,GROBELNIK M.Word sequences as features in text-learning[. C]∥Proceedings of ERK-98,the Seventh Electrotechnical and Computer Science Con ference.Ljubljana,Slovenia:IEEE Press,1998:145-148.
[17]JOACHIMST.Text categorization with support vector machines:learning with any relevant features[C]∥Proceedings of CML-98,10th European Conference on Machine Learning.Chemnitz,Germany:Springer Berlin/Heidelberg,1998:137-142.
[18]SHAFER JC,AGRAWAL R,MEHTAM.SPRINT:a scalab le parallel classifier for datamining[C]∥Proc of the 1996 Int Conf Very Large Data Bases.Bombay,India:ACM Press,1996:544-555.
[19]CHANG C,LIN C.LIBSVM:a library for support vector machines[CP/OL].2001.http:∥www.csie.ntu.edu.tw/~cjlin/libsvm/.
(责任编辑 郑筱梅)
An Ensemble Learning and Category Indicator Based Text Categorizing Method
JIANG Zong-li,XU Xue-ke
(College of Computer Science,Beijing University of Technology,Beijing 100124,China)
As it is well known that the motivation of ensemble learning is to boost a strong classifier with high generalization ability from aweak classifier.However,the achievement of generalization ability isoften at great cost of complexity and intense computation.In this paper an ensemble learning and category indicator based categorizing method is proposed and Adaboost.MH based mechanism is developed to adaptively compute the category indicating function at every step.Then all individual category indicating functions are combined with weightand an approximation to the expected category indicating function is obtained.Based on the combined category indicating function,a classifier,which has low computational cost,flexibility in updating with new features and suitable for real-time applications has been obtained.Furthermore it is proved that the proposed method is equivalence to ensemble classifier and thereby it has high generalization ability.Experiments on the corpus of Tan Corp-12 show that the proposed method can achieve good performance in text categorizing tasks and outperform many text categorizing methods.
machine learning;ensemble learning;Ada Boost.MH;text categorization;category indicator
TP 181
A
0254-0037(2010)04-0546-08
2008-05-08.
蒋宗礼(1956—),男,河南南阳人,教授.
文本分类是在给定分类体系下,根据内容对未知类别文本进行归类.文本分类是处理和组织大规模文本信息的关键,能使信息资源得以合理有效组织,是信息处理领域最重要的研究方向之一.文本分类技术也是主题搜索、个性化信息检索、搜索引擎目录导航、信息过滤等的核心技术,对于解决有效获取有效网络信息,研究新一代搜索引擎有着重要意义.
集成学习为解决同一个问题训练出多个分类器,在对新的数据进行处理时,将各个分类器的结论以某种方式进行综合.这种方法能克服各个分类器对训练集的过拟合问题,提高泛化能力,从而尽可能好地处理新数据,因此集成学习受到国际机器学习界的广泛重视,被机器学习权威专家 Dietterich认为是当前机器学习的四大研究方向之首[1],在包括文本分类的多个领域得到广泛应用[2].
猜你喜欢
客联(2022年3期)2022-05-31
心理学报(2022年5期)2022-05-16
电子产品世界(2022年4期)2022-04-21
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
计算机系统应用(2021年2期)2021-02-23
当代陕西(2020年17期)2020-10-28
计算机测量与控制(2019年4期)2019-05-08
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
