
基于 GPU的 M D6算法快速实现
2010-03-20 07:18:14李立新
北京工业大学学报 2010年6期
李立新,叶 剑,余 洋
(信息工程大学电子技术学院,郑州 450004)
基于 GPU的 M D6算法快速实现
李立新,叶 剑,余 洋
(信息工程大学电子技术学院,郑州 450004)
安全散列算法(SHA)已经被广泛地应用于电子商务等信息安全领域.为了满足安全散列算法计算速度的需要,本文通过对SHA-3算法的候选算法——MD 6算法的并行性分析,在 GPU平台上快速实现了 MD 6算法,其最快实现速度是 CPU速度的 5倍,为快速高效的实现安全散列算法提供了有效的途径.
图形处理器;SHA算法;MD6算法;线程构建模块;计算统一设备架构
随着人类进入信息化社会,信息安全已成为人们在信息空间中生存与发展的重要保证.密码学和信息安全技术在最近二十多年来,越来越受到人们的重视,对信息进行认证的现代安全协议:例如数字签名、消息认证等也得到了快速广泛的使用.对安全散列算法应用的需求也越来越大.
2005年 Wang[1]找到对 SHA-1散列函数的差分攻击方法.当前安全性更强的 SHA-2算法的设计与SHA-1相同,所以,潜在危险仍然存在.因此,NIST(美国国家标准与技术研究所)近日宣布[2],将借鉴AES加密算法的模式,通过公开的方式征集新的散列算法,即SHA-3.MD6算法是 SHA-3最佳的中间候选算法之一.
GPU(graphic processing unit,记为 GPU)即图形化处理器,是现代显卡中重要的一个部分,其地位与CPU在主板上的地位一致,主要任务是加速图形处理速度,随着 GPU计算能力的飞速提高(高端 GPU计算性能已经达到 Teraflops级别,相当于一个高性能计算集群系统,远大于主流 CPU的计算能力),GPU的应用已经不仅仅局限于图形化处理,在科学计算、地质、生物、物理模拟等计算密集型领域也得到了广泛应用[3-5].当前,在 GPU上实现密码算法已经成为一个新的研究热点[6-8].本文研究了如何利用 GPU高效、廉价地实现 MD6算法.
1 MD6算法介绍[1]
MD6是 SHA-3的候选算法之一.它是由 Ronald L.Rivest提出的.在这一节中,将叙述 MD6密码算法的工作原理,并且找出它所具有的并行性.MD6算法的安全性在文献[1]有相应的证明.
1.1 基本原理
MD6算法将长度小于 264比特的消息作为输入参量.输出结果为 d(0<d≤512)比特的摘要值.d的默认值为 256,但它可以变化.此外,MD6算法的很多参量都有默认值,但也可以变化.
密钥 K 默认值为空(长度为 0).它作为哈希函数的输入密钥.
层次 L MD6算法实质上是 4个子结点一组的 Merkle树.树的高度指定为 L,其默认值为 64(此时Merkle树是一棵完整的树).如果 L值为 0,将按顺序压缩数据.如果 L值小于 64,MD6将使用混合模式:首先基于 Merkle树,从层次 0到层次 L,随后,在每个层次内按顺序压缩数据.
其他参数 压缩函数中使用的常量(像 Q或 ti)也可以改变.
1.2 运算模式
MD6算法的运算模式基于 4个子结点一组的Merkle树.从图1可以看出MD6Merkle树具有并行性,实际上,Merkle树每个结点都可以并行计算.每个结构体的计量单位是“字”,在本文中表示 8字节(64位).

图1 MD 6Merk le树Fig.1 MD 6Merkle tree
将待做哈希文件的数据表示成树的叶子,如果输入文件不能满足每片叶子 16个“字”(相当于 128个字节或者 1 024位),可以用 0填补.此外,每个结点有 4个子结点,如果必要的话,将用 0填充结点,以此来创建虚构结点.每个模块由 4个结点组成,被压缩后将得到 16个“字”的结点.
在算法中,首先创建 Merkle哈希树,当只剩下一个根结点时,将停止做哈希运算.摘要值为树根的截断值(即最后的 d位值,也就是最后的 256位值).
1.3 压缩函数
压缩函数的每个输入为 89个“字”的向量,其具体表示如图 2所示.

图2 压缩函数的输入数据Fig.2 The input data of compression function
K为 8个“字”的密钥(如没有使用密钥,K值为 0).
U为结点 ID号,其大小为 1个“字”,压缩函数的辅助输入,指示分块的位置,由表示结点所在的层次的一个字节以及表示结点所在层内具体位置的 7个字节组成.具体结构如图 3所示.

图3 结点 ID U的结构Fig.3 The structure of node ID U
V为控制字,其大小为 1个“字”,压缩函数的辅助输入,其中,r为圈数,L为树的最大高度,对于最后一次压缩而言 z等于 1(这时所有的结点均被压缩到根结点),另外,p为填充的 0的个数,keylen为密钥的长度,d为摘要的大小.具体细节如图 4所示.B为 64个“字”的数据块,与 4个 16个“字”的结点相匹配.
在 MD6算法中,压缩函数将完成 r圈运算(默认值为 104),每圈运算有 16个独立的循环组成(可能具有并行性).这 16个独立循环由大约 15个逻辑运算或移位组成.每圈从上一圈计算的 89个字输出结果计算出 16个字输出结果(这 89个字的初始值如图 2所示(压缩函数的输入)).最后一圈计算的 64个字的输出结果作为压缩函数的输出结果.

图4 控制字V的结构Fig.4 The structure of control word V
1.4 参考实现
基于基数列表的 MD6算法实现中存储器的消耗为 log4n.树的每层由 4个模块组成,当树的该层填满时,将通过压缩这 4个模块来去除这一层,并将结果填充到下层次.
这一版本并没有直接的并行性,实现的 MD6算法采用的是逐层压缩数据.开始阶段存储了整个消息,算法中的存储器使用代价为 O(n).使用了 2个数组:一个用于工作层,另一个用于工作层的下一层(由模块压缩结果填充),大小是前一数组的 4倍.
当下层次填满时,它将变为工作层,将分配一个新的数组(大小是前一数组的 4倍)用于新工作层的下一层.为了使本算法具有更好地并行性,需要重复执行运算模式.虽然代码在压缩函数(没有修正)上花费了大量的时间,但我们的代码比 Rivest的版本更高效.在测试机上实现的平均速度为 27.5MB/s.
2 基于 CPU的 MD6算法的并行实现
2.1 Intel TBB简介[8]
在多核的平台上开发并行化程序,必须合理地利用系统的资源,如与内核数目相匹配的线程,内存的合理访问次序,最大化重要缓存.有时候用户使用(系统)低级的应用接口创建、管理线程,很难保证程序处于最佳状态.线程构建模块(TBB)可以很好地解决上述问题.TBB由 Intel提供 C++模板库(主要用于多处理器/多核框架编程),由一套数据结构包装而成.在具体使用过程中,程序员不必关注于线程管理,只需专注于任务本身.而不像使用 POSIX线程或 Boost线程时,必须管理创建,同步以及结束每个线程.在 TBB库内,计算将被看成任务,通过高速缓存器自动分发到所有可利用的资源上.
2.2 基于 TBB的 MD6算法实现
采用广度优先算法从左到右遍历整棵树,对于每层来说,可以并行计算所有模块的字,而 TBB用于管理不同处理器/核上的分布式计算.
在计算机 A上对 850MB文件作哈希运算测试,发现每个核内运行处理器的数目影响哈希的速率.在双核计算机上,本算法的实现速度是计算机 A上实现速度的 2倍.
由图 5可以看出,当每个核内运行的处理器数目达到 8个时,性能不再随着运算处理器数目的增加而线性增加.原因是计算机上存储器的总线带宽已经处于饱和状态.当每个核内运行 16个处理器时,本算法的实现速度只提高了 8倍.

图5 基于TBB的 MD 6算法对不同文件作哈希运算的速率Fig.5 The rate of MD6 base on TBB
3 基于 GPU的 MD6算法
3.1 CUDA
CUDA(computer unified device architecture,简称CUDA)是 NVIDIA公司为其 GPU开发的通用并行计算架构,它不需要借助图形学 API就可以使用类 C语言进行通用计算的开发环境和软件体系.此外,CUDA还包括专门为 NVIDIA公司 GPU进行优化实现的大量基础算法,
如图 6所示,在 CUDA架构下,执行的最小单位是线程.数个线程可以组成一个线程块.一个线程块中的线程能存取同一块共享内存,而且可以快速进行同步的动作.每个线程块所能包含的线程数目是有限的.然而,执行相同程序的线程块,可以组成栅格.不同线程块中的线程无法存取同一个共享的内存,因此,无法直接互通或进行同步.所以,不同线程块中的线程能合作的程度比较低.
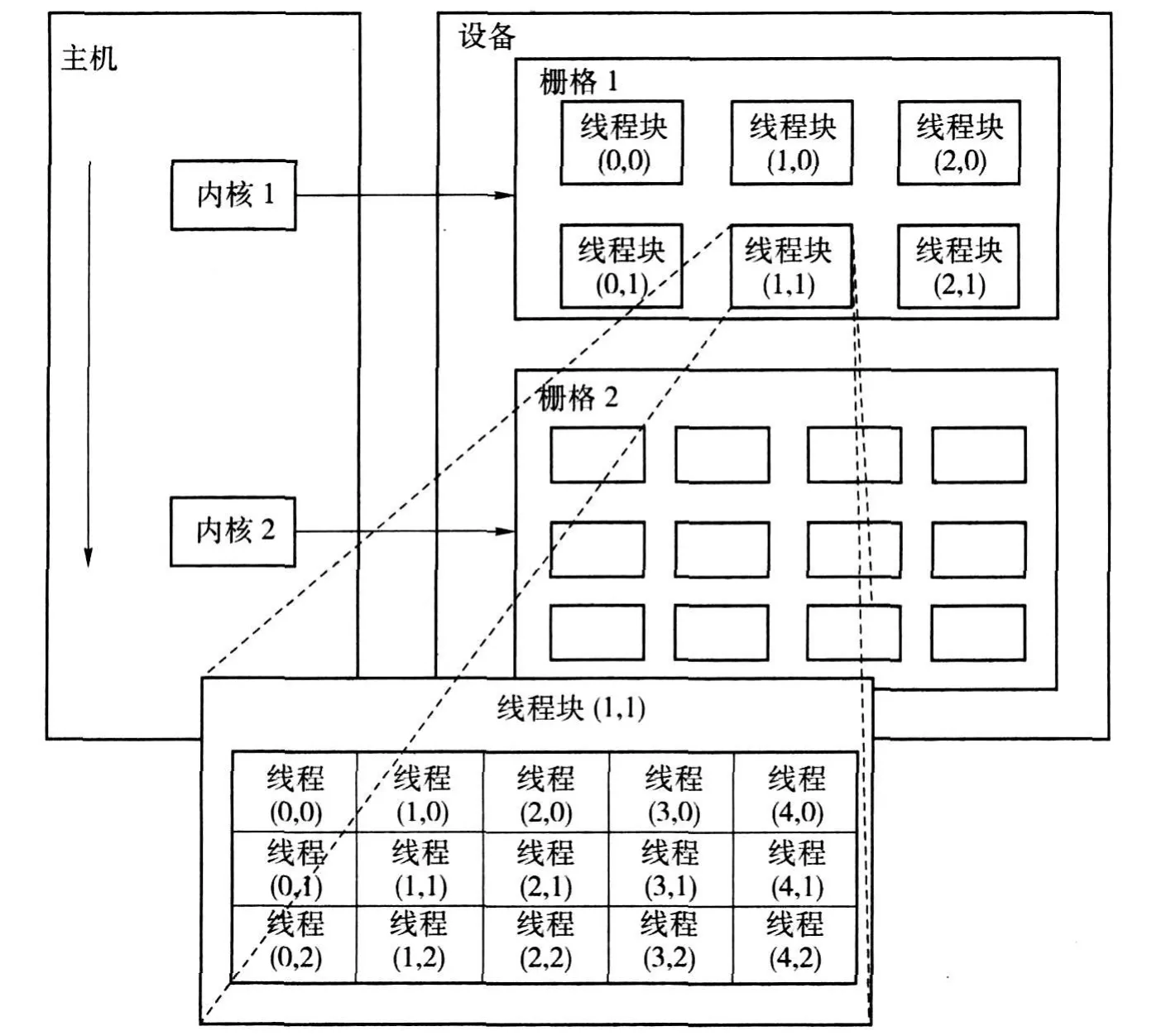
图6 栅格、线程块和线程之间的关系Fig.6 Grid、Block and Thread
如图 7所示,在 CUDA架构下,每个线程都有自身的一块寄存器和本地存储器.同一个线程块中的每个线程则有共享的一块共享存储器.此外,所有的线程都共享一块全局存储器、常量存储器和纹理存储器.不同的栅格则有各自的全局存储器、常量存储器和纹理存储器.
3.2 基于 GPU的 MD6算法实现
3.2.1 模块间的并行性
在第一个 CUDA版本的 MD6算法中,将并行压缩每个模块,每个多处理器必须将 4个结点压缩成一个结点,这和 TBB版本相似.每个线程负责将每个模块压缩成大小为一个“字”的模块.这一版本实现的平均速率约为 3.2MB/s,即它的实现速度比 CPU版本的实现速度慢了 10倍,这很大程度上是由于没有充分利用 MD6算法的并行性.
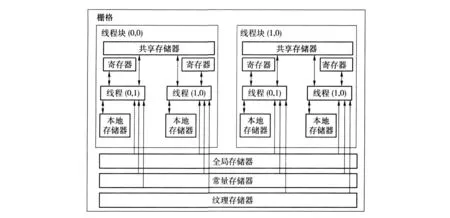
图7 CUDA的内存模型Fig.7 Memory Model of CUDA
3.2.2 压缩函数的并行性
每个模块“字”的压缩由独立的步骤组成,特别是每圈压缩步骤中的 16个循环的实现,这是程序中最耗时的部分.在这一版本的 MD6算法实现中,并行实现压缩步骤中的 16个循环,希望这样能增加程序的性能.同时,为了最大并行化这一版本,也并行算法所有可以并行的步骤,包括数组内的存储器所有复制操作.
这一版本的实现速度为 31MB/s(是前一版本的 10倍).但这一版本并没有比 CPU快.对于小文件,图形化卡上存储器复制时间消耗并没有减轻.这说明,与存储器访问相比,压缩函数要做太多的计算.为了验证这一结论,修改了压缩函数,将压缩函数每圈使用的 16个循环改为每圈使用 160个循环,该版本的GPU实现比 CPU版本的实现快了 10倍.为了进一步提高 MD6算法的实现性能,需要约束存储器的访问以及增加每个模块的计算数目.
3.2.3 改进与提高
为了增加每个模块的线程数目,在每个线程块内并行压缩几个模块“字”.仅需要一个 89个字的数组就可以完成压缩函数.在每个线程块内使用 89×N个数组(其中 N为一个线程块内压缩的模块字的数目),而不是 89+16×r个数组.在本版本的 MD6算法实现中,将使用多个线程压缩多个模块字,同时需要几个工作数组,但共享存储器的存储空间有限,不能在共享存储器存储多个数组(多于一个).同时,由于性能上的原因,也不能在全局存储器上存储工作数组.换句话说,如果将全局存储器存储工作数组,将大幅度地降低 MD6算法实现的性能.因此,对于 N个模块字,使用 N个循环数组作为工作数组.
对该版本的 MD6算法作进一步的优化,即使用循环数组提高 MD6算法性能.以 89为模数计算每个数组的索引.假如使用 128个字的循环数组,就只需要使用逻辑计算(按位掩码)来计算索引,而不是使用耗时的模运算.但 128个字对于高速缓存而言太大,其性能也非常低的.所以,采用 89个字的循环数组.每个模块使用 20×16个线程.实现速度达到了 83MB/s.
对最新版本的 MD6算法的实现作进一步的分析后,可以将模运算的值制成表格,并将其复制到 GPU的常量存储器内.因此,计算循环数组索引的消耗就转化为访问存储器的消耗.常量存储器内的数据可以被高速访问并且线程可以直接访问这些数据,这一优化技术对 MD6算法实现性能的影响非常大.本版本 MD6算法实现的速度达到 105.6MB/s.
4 性能分析
对于每个版本的测试,测试时间都分为 2种情况:包括存储器分配和存储器复制部分的测试时间,以及未包括存储器分配和存储器复制部分的测试时间,这些时间消耗很大程度上依赖于机器自身的性能.在测试环境中计算机的存储器复制速率为2 200MB/s.分别在 CPU和 GPU上测试了不同大小(文件大小从 2字节开始到 70MB结束)的文件作哈希的速率.各种 MD6算法实现版本的测试结果如图8所示.
对于大文件而言,MD6算法的 GPU版本的实现速率比 CPU版本的实现速率快,同时,还发现存储器分配的消耗以及存储器复制的消耗与文件大小的关系不大.MD6算法的 GPU版本做哈希运算的最大速率是 CPU版本的 5倍:即 GPU版本为 153MB/s,而CPU版本为 29MB/s.额外的存储器消耗是由于主机存储器与卡存储器之间复制数据的消耗(与文件的大小关系不大).对于 GeForce 9600GTS而言,图形化卡的存储器大小有限制.对于大文件,将它分离为 4个更小文件,并使用 GPU版本的 MD6算法对这 4个更小的文件作哈希运算.
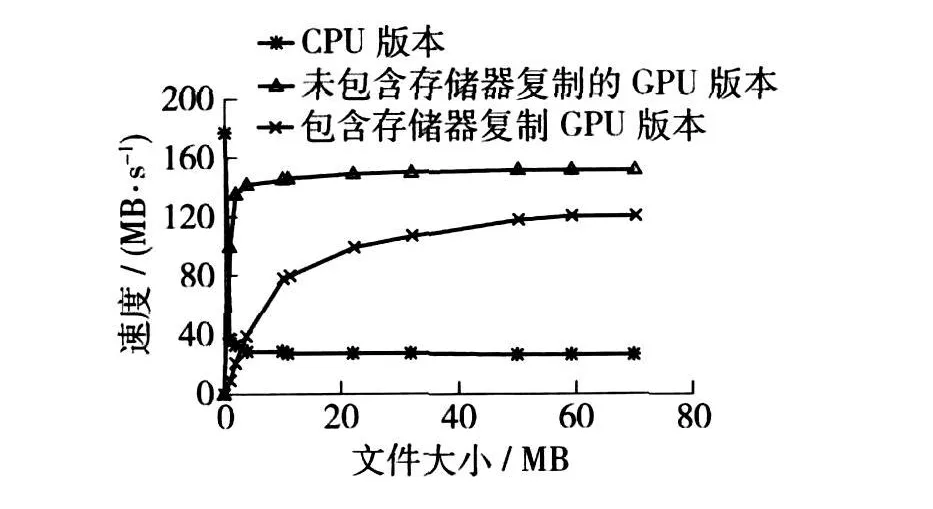
图8 基于 GPU的 MD6算法实现与基于 CPU的MD 6算法实现速度比较Fig.8 The rate of MD6 base on GPU and CPU
5 结论
对 MD6算法的并行性进行了分析,并实现了基于 GPU的 MD6算法.实现参考版本的 MD6算法以及基于 TBB的MD6算法,并对各个版本的实现速度进行了相关测试.结果表明,当文件足够大时,基于GPU的 MD6算法的实现比基于 CPU的 MD6算法的实现更加高效,基于 GPU的 MD6算法做哈希运算的最大速率是 CPU版本的 5倍.
[1]WANG Xiao-yun,YU Hong-bo.Efficient collision search attacks on SHA-0[C]∥Advances in Cryptology-Eurocrypt'05.Berlin:Sp ringer-Verlag,2005:19-35.
[2]RIVEST R L.Themd6 hash function.a p roposal to nist for sha-3[DB/OL].[2008-10-27].http:∥groups.csail.mit.edu/cis/md6/submitted/Supporting Documentation/md6 report.pd f
[3]NVIDIA CORPORATION.NVIDIA.NVIDIA_CUDA_Programming_Guide_2.0[DB/OL].[2009-10-27].http:∥developer.download.nvidia.com/compute/cuda/.
[4]吴恩华,柳有权.基于图形处理器(GPU)的通用计算[J].计算辅助设计与图形学学报,2004,16(5):601-612.WU En-hua,LIU You-quan.General purpose computation on GPU[J].Journal of Computer-aide Design&Computer Graphics,2004,16(5):601-612.(in Chinese)
[5]吴恩华.图形处理器用于通用计算的技术、现状及其挑战[J].软件学报,2004,15(10):1493-1504.WUEn-hua.State of the art and future challenge on general purpose computation by graphics processing unit[J].Journalof Software,2004,15(10):1493-1504.(in Chinese)
[6]COOK D L,IOANNIDIS J,KEROMYTIS A D,et al.CryptoGraphics:Secret Key Cryp tography Using Graphics Cards[C]∥RSA Con ference:Cryptographer's Track(CT-RSA),2005.
[7]OWENSJD,HOUSTON M,LUEBKED,etal.GPU computing[J].Proceeding of the IEEE,2008,96(5):879-899.
[8]INTEL.Threading Building Blocks Reference Manual[DB/OL].[2009-11-05].http:∥www.threadingbuildingblocks.org/up loads/81/91/Latest%20Open%20Source%20Documentation/Reference%20(Open%20Source).pdf.
(责任编辑 张士瑛)
The Fast Implementation of MD6 on GPU
LILi-xin1,YE Jian1,YU Yang1
(Institute of Electronic Technology,Information Engineering University,Zhengzhou 450004,China)
Secure Hash Algorithm(SHA)is an important tool in practice of cryptography such as digital signature,and ithasbeen widely applied in electronic businessetc.the information security fields,etc.MD6 is one of the several candidates for the SHA-3 competition.How to implementMD6 efficiently is an urgent question to be answered.This paper presentsa parallel analysis ofMD6,and a fast realization on GPU platform,so as to provide an easy way to implementing SHA quickly and efficiently.
GPU;SHA algorithm;MD6 algorithm;TBB;CUDA
TP 309
A
0254-0037(2010)05-0640-06
2009-12-10.
国家“八六三”计划基金资助项目(2008AA 01Z404).
李立新(1967—),男,重庆人,副教授.
猜你喜欢
电脑报(2022年13期)2022-04-12 00:32:38
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
电脑报(2020年24期)2020-07-15 06:12:41
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
初中生之友·中旬刊(2015年4期)2015-06-10 09:01:13
环球时报(2014-06-18)2014-06-18 16:40:11
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年23期)2014-02-27 12:02:22
电子设计工程(2014年12期)2014-02-27 11:58:03
