
基于GPU加速的光线跟踪体绘制算法研究
2010-03-16 07:43:40陈占芳张国玉师为礼任涛
长春理工大学学报(自然科学版) 2010年1期
陈占芳,张国玉,师为礼,任涛
(长春理工大学,长春 130022)
光线跟踪体绘制算法是体绘制技术中的一种经典算法,传统算法中所有的计算都在CPU上进行,重建速度较慢,无法达到实时效果。本文使用GPU编程技术,将原先在CPU中进行的场景求交和光线遍历采样等步骤,移入GPU中进行,利用GPU的高速浮点运算能力,来实现三维图像的实时绘制。与在 CPU上实现光线跟踪体绘制算法相比,速度大大提高。
1 GPU原理与光线跟踪技术分析
GPU(Graphic Processing Unit),即图形处理器,是显示卡的核心。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,特别在三维图像处理时,更能体现 GPU的浮点运算能力。但GPU的指令执行方式和CPU不一样,无法直接实现递归,所以不能直接执行在 CPU中实现的算法。依据 GPU特性,本文把光线跟踪表示成一种流计算模式,把可编程的 GPU抽象成通用的流处理器,充分利用了 GPU并行处理体系结构的性能优势来实现算法。
实现基于流的光线跟踪最大的难度是如何把光线跟踪映射到设计的流计算模型中。GPU有很强的流处理能力,但实现递归非常困难。把光线跟踪细分成多个内核,内核通过数据流联系在一起。不管是静态场景还是动态场景绘制,首先要确定光线跟踪能够处理的几何体片元的类型和系统实现中所使用的加速结构的类型。光线跟踪能够渲染由不同几何体片元组成的场景,其中最适合的是三角形。同时图形硬件仅支持三角形渲染,其它表面形状虽能使用,但在渲染之前它们都要被转换成三角形。所以使用三角形来表示场景中几何体。其次,建模程序和扫描软件产生的模型都是由三角形网格组成的,当在场景中只有一种简单图形单元时,光线跟踪会显得更加简单有效。对于流计算来说,场景中所有绘制可以被相同的内核集来处理,这种方式使系统的数据流得到简化。
2 算法实现
光线跟踪算法可以分解为两大部分。一部分由CPU端来完成,主要负责整体计算的控制和平衡。另一部分则在GPU中,主要负责光线跟踪的计算,这部分主要由四个类型的计算内核来完成。
2.1 CPU端控制
CPU用来进行算法的整体控制和计算平衡。
在 GPU上进行光线衍生技术时,会获得一组反射和一组折射光线,整个计算过程是一个多路径的复杂计算,在多个路径之间进行切换需要CPU的控制。GPU无法对这些光线同时进行计算,这需要CPU对计算资源进行控制分配,即当光线生成或光线衍生产生光线时,将生成的光线压入栈,由CPU来分配GPU计算资源。
另外,由于访问存储空间的限制,光线的遍历和求交成为了算法实现最难解决的问题。为此,必须设计合适的遍历加速结构来组织场景中的几何基元数据。在经典的加速结构中,主要有两种组织方式。一种以场景的几何基元为中心,一种以场景的空间为中心。本文使用后一种,构建类 BSP的算法,同时为了提高效率,采取一组光线并行入栈的方式。
2.2 GPU端算法实现
在 GPU端进行光线跟踪计算,使用一种基于流的光线跟踪算法。整个框架由四个功能内核组成:光线生成、场景遍历、模型求交、渲染和光线衍生。每一种对应于GPU中一个路径的计算。
(1)光线生成:生成初始光线的起点和方向。
(2)场景遍历:使用类二叉树结构来组织场景,利用光线信息在整体场景的空间剖分结构中寻找可能需要进行光线求交的模型表面基元。
(3)模型求交:主要完成交点的探测及光线与表面基元的求交计算。
(4)渲染和光线衍生:利用 phone光照模型来进行光照计算,并将获得值累加到帧缓存相关象素中。如果光线有交,就利用交点信息生成相应的反射或折射光线。必要时,也会生成阴影测试光线。
如图1所示,每个功能内核的输入显示在盒子的左边,内核之间传输的流数据的类型由虚线所指的内容表示。这种细分的方式在流编程模型中并不是强制性的。
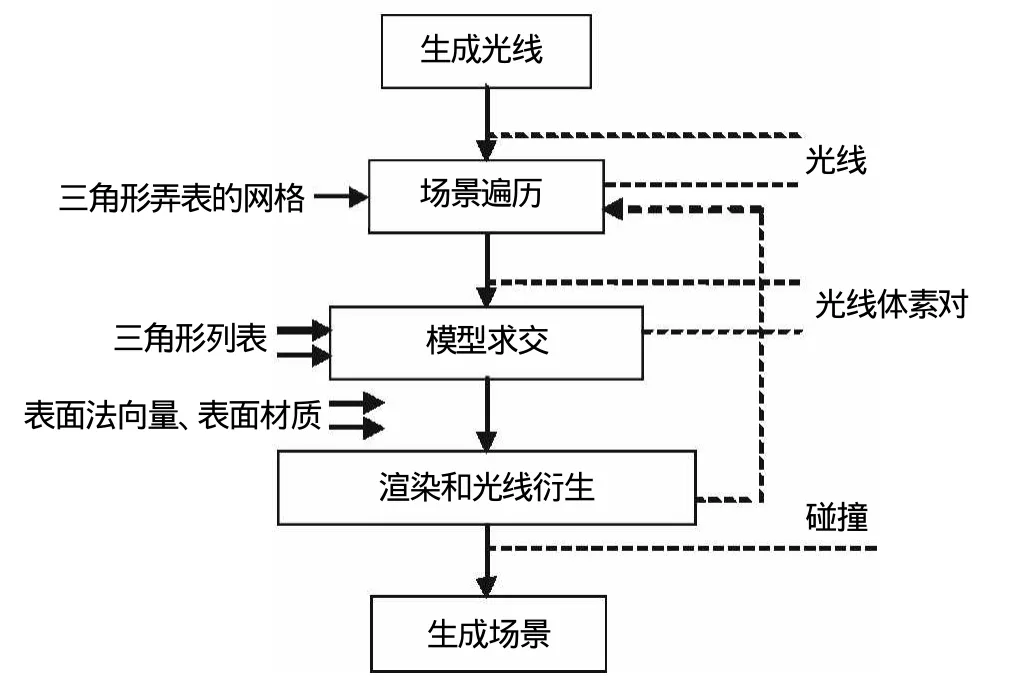
图1 基于流的光线跟踪算法流程Fig.1 the ray tracing based on flow
光线产生器内核产生一束光线流,每根光线都和图像中的某个像素相关联,以此形成光线向量集。网格遍历内核读取由光线产生器产生的光线流,然后作用光线,使光线一步一步地遍历网格直到碰到一个包含三角形面片的体素,光线和体素对被输出并传递到光线与三角形面片求交测试内核里。
场景遍历中,改进的遍历算法描述如下:
第一步,建立2维KD_Tree结构来存储场景信息,该树中的每个节点代表一个轴向包围盒;每一个内部节点表示分离平面,该平面将场景划分为两个子区域。划分包围盒的方法是沿轴循环分割,首先从根节点沿x轴对盒子进行分割,然后再沿y轴分割子盒子,最后再沿 z轴分割孙子盒子,以此循环。
第二步,在求交和遍历之前将该树中序线索化为线索二叉树;
第三步,如果光线的跨度区间横跨分离轴的两侧,说明该光线同时穿过两个子包围盒,则先和第一个子节点求交,只要先遍历第一个节点,不将第二个节点压入堆栈;否则,和相交的子节点求交;
第四步,如果该节点是叶子节点,且射线和该子节点有交,则返回成功,否则,直接搜索该节点的后继节点。
本算法可避免堆栈操作带来的开销。虽然建立线索二叉树本身也会有一定的开销,但该操作在初始化时一次完成,后面的每次操作都将加快遍历速度。在实际应用中,通过限制中间节点的深度,并保证KD_Tree的平衡性,平均的算法时间复杂度为O(log2n)。
模型求交内核主要负责测试该光线是否和体素中包含的三角形面片有交点。光线跟踪实际上就是复杂场景和一个光线树的遍历求交过程,每次重新生成的光线都是原来光线的子光线,这样将动态生成一个光线树。每个像素点的最终颜色都是沿着光线树向下迭代求交所得,由于 GPU体系结构的限制,无法动态生成光线树,可以利用光线栈来管理每次求交生成的子光线。对于反射光线,为了提高效率,可以利用循环迭代来代替原来的递归调用。N次迭代的公式可以表示如下:

其中 表示模j,ri表示i物体的反射系数, 为像素的最终颜色,N为反射深度。
渲染和光线衍生的功能主要是计算颜色值。如果一根光线终止在相交点上,那么把这个相交点的颜色值写进累加的图像上。此外,绘制内核可能产生阴影或次光线,这种情况下,将这些新产生的光线返回到遍历阶段,开始新的跟踪。
3 结果与分析
基于 GPU加速的光线跟踪绘制速度的测试不包含加速结构构建时间,因为实验的目的是测试GPU加速对场景绘制速度的影响。对于静态场景绘制,加速结构构建可在预处理阶段完成。上述算法中,GPU实现部分使用NVIDIA推出的通用并行计算架构 CUDA(Compute Unified Device Architecture)完成,根据 GPU中独立 ALU(算术逻辑部件)数量将光线投射运算拆分,所有 ALU并行运算,提高光线投射处理速度。两种实现方式在分辨率为256×256、512×512情况下,绘制速度如表1所示。

表1 光线跟踪算法在CPU和GPU上实现时的速度比较Tab.1 speed of the ray tracing on CPU and GPU
4 结论
主要讨论了一种改进的光线跟踪算法,它是一种基于GPU的快速光线跟踪绘制算法,在普通PC机上(Pentium4 3.0G,ATI9500),根据3个不同复杂度的场景,在分辨率分别为256*256、512*512时,实现了GPU和CPU实现光线跟踪绘制,并进行结果比较分析。从实验结果可得到基于GPU加速的光线跟踪的优势,随着场景复杂度的增加,基于GPU加速的光线跟踪算法将明显优于CPU上的算法。
[1]杨俊华,符红光,郭惠.基于GPU快速光线跟踪算法的设计与实现[J].计算机应用,2007,27(8):2033-2035.
[2]储璟骏.基于GPU的直接体绘制技术[D].上海交通大学硕士论文,2007.
[3]章圣洁,王国荣,王小平.基于GPU加速的光线跟踪技术研究[J].计算机时代,2007(6):3638.
[4]王碧薇.基于GPU的光线跟踪算法的分析[J].科技资讯,2007,23(6):64-.
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
疯狂英语·新悦读(2023年9期)2023-12-02 17:36:34
现代装饰(2022年4期)2022-08-31 01:41:24
今日农业(2021年9期)2021-07-28 07:08:36
中外文摘(2019年8期)2019-04-30 06:47:36
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
信息安全研究(2018年12期)2018-12-29 11:01:56
童话世界(2018年17期)2018-07-30 01:52:02
创新作文(小学版)(2016年28期)2016-02-28 18:24:50
故事作文·高年级(2015年5期)2015-09-08 08:27:33
