
基于VSM的潜在语义索引
2010-02-25 07:35王瑛
陕西科技大学学报 2010年5期
王 瑛
(闽江学院教务处, 福建 福州 350108)
0 前 言
现在主流搜索引擎,如Google、百度等采用的都是存典型的搜索引擎排序技术,主要采用超链分析排序技术.Web检索采用的是基于布尔模型(Boolean Model)的关键词的检索技术,采用“and ”、“or”、“ not”等布尔关系来组合各个关键词进行检索,然后对检索结果文档进行倒排序.这样很容易产生由于关键词的机械字符匹配和一词多义问题很容易造成漏检和错检,检索的查全率和查准率比较低,造成的后果是检索结果往往不是检索者的本意.
例如:在多义词检索时,输入检索内容为“苹果”,输出的检索结果可能是“苹果”牌的电脑,也可能是“苹果”这种水果的介绍,甚至可能是“苹果”这部电影的宣传资料.再例如在同义词检索时,输入内容为“微机”,输入检索内容有“微机原理”这门课程的介绍,有“微机”考试的介绍,搜索引擎是不理解检索者对“微机”、“计算机”、“个人电脑”、“个人计算机”等词汇是同一个潜在含义的不同表示方式,而检索者个人的习惯输入方式是各不相同的,这也就造成了检索结果的多样性和不确定性.同时关键词的语义蕴涵扩展性也十分机械,不能达到检索词的相关语义扩展,如查询“研究生”这个关键词时,“硕士研究生”、“博士研究生”、甚至“Graduate”这个外文词汇都应该是这个关键词的蕴涵检索内容.
由于布尔模型的不足,现在发展出向量空间模型(Vector Space Model,VSM)[1]、概率模型(Probabilistic Model)[2]、 潜在语义索引(LSI) (Latent Semantic Indexing)[3]等.其中潜在语义索引(LSI) 是近年来比较有效的一种智能型的信息检索模式,它可以解决基于关键词检索中遇到的同义词和多义词的问题.
1 信息检索方法
1.1 潜在语义索引
潜在语义索引最初是一种知识的自动提取和表示的方法,近年来广泛地应用到文本检索中,LSI模型的优点是克服了VSM模型不考虑词间依赖关系的缺点,一定程度上解决了一词多义的问题,将原始的向量空间转化为体现特征项之间潜在语义关系的语义空间,查询内容在语义空间上进行表示和比较,使得孤立的关键词包含了一定的语义关系,从而达到自然语言层面的检索.但LSI模型也有不足,它需要通过奇异值分解(Singular Valued Decomposition,SVD)来模拟关键词与文献之间的关系,其算法比较耗时,特别是当原始的文本-特征矩阵维数比较大时,计算量和存储空间更大,另外由于该方法的本质只是数据在几何空间上的变换,只是自然语句单词的汇总,和自然语言的整句语义所表达的信息还有一定的差别,并没有包含整个自然语句中更深层次的语义关联信息.针对这些问题,本文提出了一种基于向量空间模型的潜在语义索引的改进算法.
1.2 向量空间模型
基于向量空间模型的检索基本工作原理如下:
将Web页面文档所具有的各个特征项作为文档表示的坐标,以向量形式把文档表示为多维空间中的一个点,向量空间由一组线性无关的基本向量组成,并以特定的方式为每个特征项赋予不同的权重系数,向量维数与向量空间维数一致,并可以通过向量空间进行描述,这样就将Web页面文档用空间中的一个特征向量来进行描述.
数学模型描述如下[4,5]:
定义1 文档D(Document)为Web 页面上的一个文档或一个文档的片段,或者为一个数据库中的全部字段信息.
定义2 特征t(Term)为文档中能够代表文档属性的信息的基本评议单位,可以是字、词等,也就是检索中的关键词,文档D可以表示成为D(t1,t2,…,tn),其中n为检索关键词的数量,t为特征项.在Web页面进行检索时,每一个向量对应一个URL.
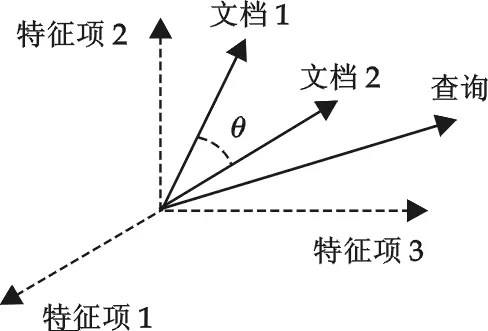
图1 文档向量空间及相似度计算
定义3 特征项权重W(Weight)为特征项tn能够代表文档D能力的大小,体现了特征项t在文档D中的重要程度.在检索查询过程中,用户输入检索的关键词表达式,对输入表达式进行特征项分析,赋予每一个特征项不同的权重W,当检索查询内容匹配时,给予D对应的特征项t的权重W值为1,否则给予权重W值为0.
定义4 相似度S(Similarity)为文档D与其它文档内容相关程度的多少,使用特征向量来表示时,可以使用向量文档D之间的距离来衡量,用内积或夹角θ的余弦值来衡量.夹角θ越小说明相似度S越高,否则相似度S越小,通过计算每个文档向量与查询向量的相似度,将排序结果与设立的阈值进行比较,取大于阈值的Web页面进行倒排序,即可输出最终的Web页面检索结果,如图1所示.
2 改进的算法
2.1 算法描述
基于向量空间模型在潜在语义索引,其主要思想是对文档向量空间进行降维,即使用一个超平面将两类文档的数据点正确分开,且两类数据点与分类面距离最远[6].
其算法描述如下:
任意一个的检索关键词的语句表达式集合:
(xk,yk)k=1, 2, …,N,xk∈Rn,yk∈R
其中xk为输入值,yk为映射点.利用高维特征空间中的线性函数可以将特征空间表示为:
y(x)=wTφ(x)+b
其中非线性映射φ(x)将输入向量映射成一个高维特征空间,b为其偏离值,w为特征空间同一方向的加权向量.
(ak,S为拉格朗日函数的乘数,顶点可以通过设偏导数为零求得)
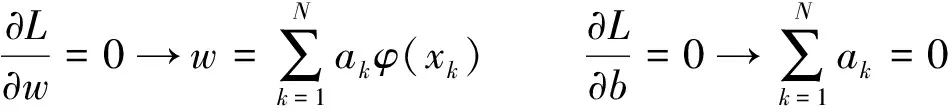
根据Karush-Kuhn-Tucker(KKT)必要性条件可以消除ek和ω得到以下线性方程组:
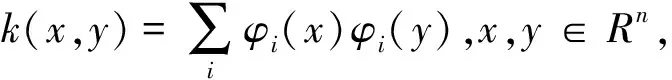
在这里因为使用了核函数,高斯核函数变换为K(x′)=exp(-‖x-x′‖2/2σ2).
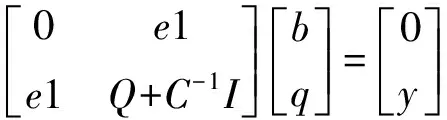
2.2 算法验证
当使用N个向量数据来建立模型时,首先令:
则根据KKT条件消除ek和ω后得到的线性方程组:
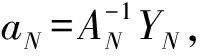
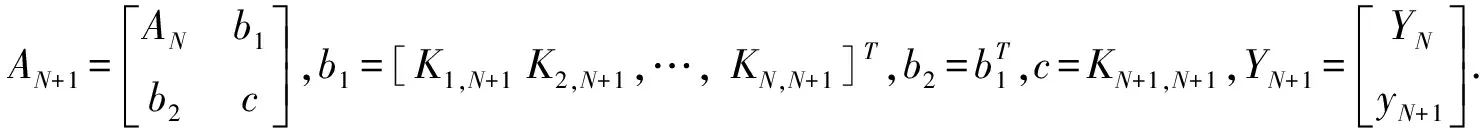
可以得到如下推论:
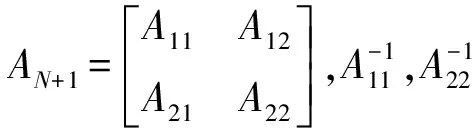
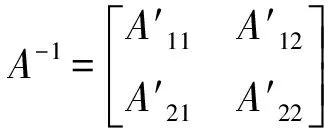
2.3 检索步骤
基于向量空间模型的潜在语义索引主要步骤如下:
步骤1 建立文档关键词的向量矩阵,并对其进行归一化,利用高维特征空间中的线性函数可以将特征空间进行表示;
步骤2 对文档关键词向量矩阵进行奇异值分解,并将用户查询向量投影到变换后的文档向量矩阵空间中;使用低维的关键词文档向量替代原有的关键词的文档向量,以处理大规模文档集,提高信息检索的精确度和效率.
步骤3 根据某种向量间的相似性度S量(向量距离公式或向量夹角θ的余弦公式),查找和用户查询最相似的文档集合,即夹角θ值最小的文档集,并按相似度取大于阈值的Web页面进行倒排序[7].
步骤4 根据用户对查询结果的关注程度,挑选出用户所关注的关键词集,并根据该关键词集的内容进行语义扩展,找出用户潜在的语义信息集,重新构造查询,查找和新查询最相似的文档,这一过程可以循环进行下去,直到用户满意为止.
3 实验结果
使用MATLAB进行验证计算,对一个有10 000篇文档的小规模网络数据库进行测试,数据库容量约为10 MB,系统运行硬件环境为Pentium(R)4 CPU 3.00 GHz,内存为1 G;软件环境为Microsoft Windows XP(Service Pack 3).经过检索实验,产生的查询文件约2 MB,整个计算过程耗时5 min左右.
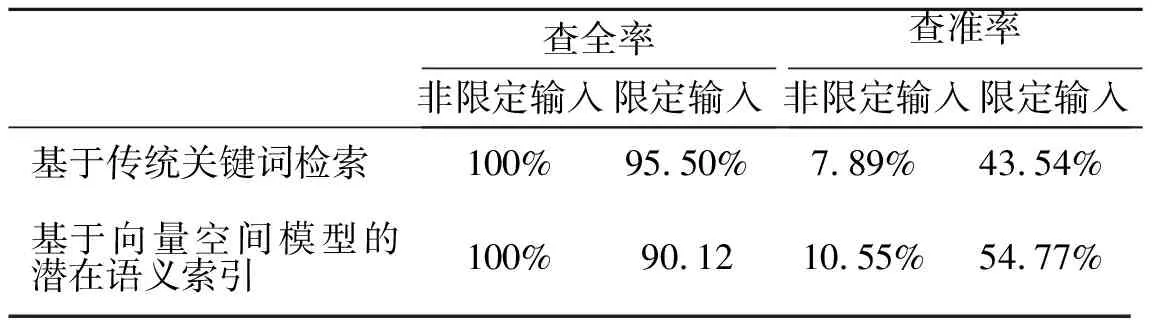
表1 对比实验结果
对比传统的关键词查询,该算法查准率在不限定输入的情况下,检索结果只有10%左右,在限定输入的情况下也只能达到目的55%左右;查全率在两种情况下都可以达到90%以上.该实验结果比传统的关键词查询的查准率有所提高,查全率基本相当.
4 结束语
基于向量空间模型的潜在语义索引技术与传统的检索技术相比,在实际应用中具有一定的优越性,它反映的不再是词的简单出现频度和分布关系,而是强化的语义关系,本文提出了该技术的一种算法关键技术,但由于在查询语句的自然语言语句包括有一些虚词(不包括内容含义的词),或者在分割单词时出现的错误,部分影响了检索的查准率,还不能完全解决潜在语义的检索问题,因此今后应在如何提高查准率上进行更深入的研究,以解决潜在语义索引的实际效果问题.
参考文献
[1] Salton G, Wang A, Yang C S A. Vector space model for information retrieve[J]. Journal of the American Society for Information Science, 1975,18(11):613-620.
[2] 陶 蕾.一种智能型的信息检索方法:隐含语义索引法[J].情报理论与实践,2004,27(3):308-309.
[3] 盖 杰.基于潜在语义分析的信息检索[J].计算机工程,2004,30(1):58-60.
[4] 朱华宇,孙正兴,孙福炎.一个基于向量空间模型的中文文本自动分类系统[J].计算机工程,2001,27(2):15-17.
[5] 张元馨,赵仲孟,沈钧毅.一种基于空间模型的个性化搜索引擎研究[J].微电子学与计算机,2003,(11):52-55.
[6] 戚 涌,徐永红,刘凤玉.基于潜在语义标引的 WEB 文档自动分类[J].计算机工程与应用,2004,40(22):28-31.
[7] 周 文,龚礼明,蒋 岚.隐含语义检索及中文样本分析实例[J].计算机应用,2004,24(1):273-276.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
开放教育研究(2020年2期)2020-03-31
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
专利代理(2016年1期)2016-05-17
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
质量与标准化(2010年5期)2010-05-03
