
基于Mesh词表和共词分析的疾病本体半自动构建方法研究
2009-07-15 09:54刘菊红于建荣缪有刚
现代情报 2009年3期
关键词:本体
刘菊红 于建荣 缪有刚
〔摘 要〕分析了利用专业词表和共现分析方法相结合半自动构造领域本体构建的方法。利用专业词表抽取概念和等级关系,利用共现分析方法抽取非等级关系。
〔关键词〕本体;半自动构建;Mesh;共现分析
〔中图分类号〕G254.24 〔文献标识码〕A 〔文章编号〕1008-0821(2009)03-0208-04
本体是用来描述某个领域甚至更广范围内的概念以及概念之间的联系,使得这些概念和联系在共享的范围内有着明确惟一的定义,达成一种共识,这样人机就可以进行交流。N.Guarino提出将本体划分为顶级本体(top—level ontology)、领域本体(domain ontology)、任务本体(task ontology)和应用本体(application ontology)。
1 领域本体概述
1.1 领域本体的概念、特征及其发展态势
领域本体是用于描述指定领域知识的一种专门本体。它给出了领域实体概念及相互关系、领域话动以及该领域所具有的特性和规律的一种形式化描述。目前,领域本体模型的研究已经进入实际应用阶段,许多研究领域都建立了自己标准的本体[1]。领域本体的发展非常迅速,不仅得到了广泛的应用,在实际应用中也取得了积极的作用。国外文献中涉及的领域本体,包括化学领域、生物医学领域、地理学领域和其他领域。领域本体的应用展现出涉及学科领域广、更加专业化、针对性更强、涉及多个学科的领域本体增多等特点[2]。
对数字图书馆而言,领域本体在数字图书馆对其知识进行语义层面的组织中扮演着至关重要的角色,领域本体的构建是语义网络环境下数字图书馆知识组织不可或缺的关键步骤。
1.2 领域本体的构建
目前本体构建主要有手工构建、复用已有本体以及自动构建本体3种方法。手工构建领域本体费时费力、花费巨大,且由于手工构建本体尚缺少一套工程化的科学管理流程作为支撑,使得本体的构建主观性太强,可行性和实用性都受到质疑。自动构建本体目前还处于研究阶段,利用机器学习会产生大量的噪音数据,缺乏必要的语义逻辑基础,抽取的概念关系松散且可信度无法得到很好的保障。尽管机器学习应用于本体自动构建有巨大的潜力,但是距离良好的可理解性尚有很大的距离。半自动构建本体是较为理想的模式,其关键技术在于领域概念的获取和领域概念之间关系的获取[3]。
1.2.1 领域本体构建的主要方法
目前主要的领域本体构建方法有TOVE法、METHONTOLOGY法、骨架法、KACTUS工程法、SENSUS法、IDEF5法和斯坦福大学医学院开发的七步法。TOVE法专用于构建TOVE本体,由多伦多大学企业集成实验室研制;METHONTOLOGY法专用于构建化学本体(有关化学元素周期表的本体);骨架法专门用来构建企业本体;KACTUS工程法的目的是要解决技术系统生命周期过程中的知识复用问题;SENSUS是开发用于自然语言处理的SENSUS语言本体的方法路线。IDEF5法开发用于描述和获取企业本体的方法;斯坦福大学医学院开发的七步法,主要用于领域本体的构建。目前大多数领域本体的构建都采用了七步法。
1.2.2 领域本体构建的流程
根据现有的本体构建方法进行总结,本体构建的一般流程如下:(1)明确研究对象和范畴;(2)对该领域的现有本体进行调查和研究,借鉴已有的研究成果;(3)提取核心概念;(4)对概念词进行分类和合并,定义类和类的语义关系,主要包括等级关系和非等级关系;(5)定义函数和公理;(6)创建实例;(7)构建知识库。
1.3 领域本体构建的关键技术
领域本体构建的关键技术包括领域概念的获取和领域概念之间关系的获取。领域本体领域概念获取主要有以下两个途径:①专业词典;②利用自然语言处理技术,直接从全文或者文摘、关键词字段中抽词。领域概念之间的关系主要分为等级关系和相关关系。等级关系获取的方法主要有:①专业词典;②聚类算法;③字面成族;④模式匹配。相关关系获取的主要算法有:①共现统计算法;②关联规则算法;③隐含语义索引;④Hopfield联想算法等[3]。
2 疾病本体的构建
生物学领域涉及比较广,与医学、化学等多个学科多有交叉,相关本体也多是与其他学科相结合,其应用也比较成熟、广泛。近年来在生物医学领域出现的领域本体有:(1)SGDS(Similar genes discovery system),相似基因发现系统;(2)GOHSE系统,是一个支持浏览生物资源的应用程序;(3)FMA(the Foundational Model of Anatomy)是一个生物医学信息学方面的参考本体。(4)OBO(Open Biomedical Ontologies),开放生物医学本体[3]。
重大疾病通常具有以下2个基本特征:一是“病情严重”,会在较长一段时间内严重影响到患者及其家庭的正常工作与生活;二是“治疗花费巨大”,此类疾病需要进行较为复杂的药物或手术治疗,需要支付昂贵的医疗费用。卫生部2006年统计报告指出,重大疾病导致的全国人口死亡总数占死亡总数的90.4%。因此,探讨重大疾病本体构建的方法具有重大意义。
2.1 疾病本体的顶层构建
由于疾病具有相同的特征,如都可以从表型、病因学、治疗手段等角度进行描述。因此,对疾病的特征进行分析,探讨构建本体的方法是可行的。澳大利亚科庭大学Maja Hadzi等人对疾病本体展开了深入的研究,在第38届国际系统科学会议上,展示了在疾病本体研究领域的研究成果,构建了疾病本体的顶层框架,认为疾病本体可以从疾病类型、表型、病因学、治疗手段4个主要的维度进行描述(见图1)[4]。人类基因组计划后,人类对基因的认识突飞猛进,对现有生物医学相关数据库的调查发现,大部分数据库仅限于基因组学等分子生物学领域。从基因的角度认识基因与疾病的关系尤其具有重要的意义。

2.2 疾病本体概念的获取
由Medline数据库收录的生物医学文献,都由标引人员赋予了12个左右的MeSH主题词来表达该文献的主要内容。正是由于MeSH主题词的存在,才保证了PUBMED海量生物医学文献的有效检索。《医学主题词表》(Medical Subject Headings,简称MeSH),由美国国立医学图书馆(NLM)编辑出版。MeSH词表的以下特点,使MeSH词表满足为疾病本体构建提供概念的要求。
(1)词表主题词是在医学文献标引的基础上编制的,并尽可能吸收反映专业文献领域新出现的专业术语符合医学文献标引的需要。目前,MeSH已收入叙词24 767个,入口词97 000个[5]。
(2)树形结构表划分级别深,列类详尽,远超过一般叙词表的范畴索引,有助于从分类的角度对叙词表进行查找和使用。
(3)使用范围广:MeSH是国外生物医学领域使用最广泛的专业词表,NLM利用MeSH叙词表来标引MEDLINE数据库和pubMED数据库中的4 800种世界顶级生物医学期刊的文章。
(4)更新速度快:MeSH词表1960年出版,从1962年起每年更新1次,网络版每周更新,使词表 能收录最新的词汇,避免了辞典通常不能及时收录新词的缺陷。
2.3 等级关系的获取
MeSH词表从学科分类角度组织叙词。树形结构表从学科分类的角度,按MeSH收录的主题词的学科属性分类编排而成,故又称范畴表。它通过展示主题词在学科体系中的逻辑关系,纵向反映主题词之间的概念等级关系。树形结构表将MeSH所有的主题词分为17大类(见表1)[6]。

在各大类下,再根据情况划分若干基本类目,按照需要按概念的等级关系逐渐展开子类,最多可达9级,用逐级缩格的方式来表达它们的逻辑隶属关系,同一级的主题词按字顺排列,每一个词给一个树形结构号。下面为胰岛抵抗树形结构表的编排格式(见图2):[6]
第1级Diseases疾病C
第2级 Nutritional and Metabolic Diseases营养和代谢疾病C18
第3级 Metabolic Diseases代谢疾病C18.452
第4级 Glucose Metabolism Disorders葡萄糖代谢紊乱C18.452.394
第5级Hyperinsulinism胰岛功能亢进 C18.452.394.968
第6级 Insulin Resistance胰岛素抵抗 C18.452.394.968.500
图2 胰岛抵抗树状结构片段
被Mesh词表收录的每一个概念词,都存在于树状分类结构之中。因此,可以利用Mesh词表的范畴表,提取糖尿病本体概念的等级关系。
2.4 非等级关系的获取
目前,非等级关系的提取主要依赖于人工提取,通过领域专家的阅读来建立概念间的非等级关系,手工构建领域本体不仅费时费力、花费巨大,且其随意性大,可用性受到质疑,并且依赖于领域专家的参与。
2.4.1 共词分析的相关理论
共词分析是共现分析当中的一种,具体指通过分析在同一个文本主体中的款目对(单词或名词短语对)共同出现的形式,以发现科学领域的学科结构的定量分析方法[11]。在自然语言中,所有的概念之间都是直接或者间接相关的。对于全部概念,同一领域内概念之间的联系要比不同领域间概念的联系程度更密切。在这里用概念之间的距离表示概念之间关系的紧密程度,两个概念越相关,那么这两个概念的距离就越短,这种联系的直接表现就是概念在文本中的共现,在一篇文章中,一个主题内容会出现多个概念,而这些概念就是要提取的[7]。
2.4.2 相关研究
Ying Ding在12届国际数据库和专家系统应用会议上提出可利用共现理论来构建本体[8]。Takeshi Morita,Yoshihiro Shigeta,Ying Ding等正在开发的DODDLE-OWL本体构建项目综合利用了共现分析方法和现有词表或本体中的分类学知识为特定知识系统构建本体。DODDLE-OWL项目利用已有本体中的类别信息构建本体中的基础类别关系。同时,通过从该领域文本集中抽取的相关概念进行共现分析以确定概念之间的非分类关系;Ying Ding在构建IR和AI本体时,首先利用共现分析获得具有语义关系的关键词对,随后利用现有的领域词表提供的BT/NT关系丰富词汇间的层次关系[8-9]。张学福利用词共现进行了可视化的概念空间研究[10]。王曰芬等提出共现分析可用于构建本体[11]。
2.4.3 共词分析的基本流程
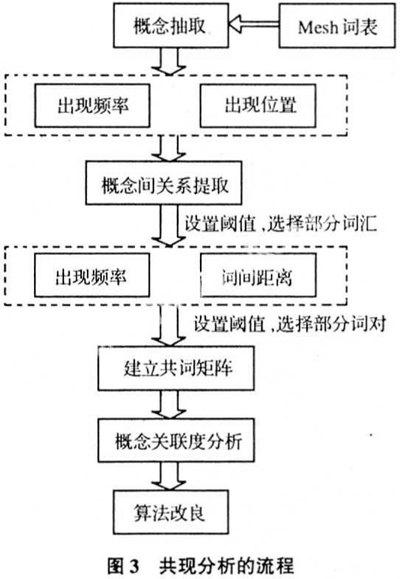
按照共现分析的方法论基础和研究的目的,本文针对疾病本体的构建,设计了如下共现分析流程:
(1)概念词抽取:从题名、文摘、关键词字段,提取出被MeSH词表收录的概念词。从概念出现频次及出现位置两个角度进行加权计算,设置阈值,选择部分与研究领域最相关的概念词。
(2)概念间关系的提取:从概念对之间的共现频率、共现时相隔的词间距离等角度进行加权计算,选择部分语义关联概率最大的词对。
(3)构造共词矩阵:根据第二步提取出来的词汇对,构造共词矩阵。
(4)概念关联度分析:分析两个词汇(或概念)间的关联度的主要测度方法有Dice指数、余弦指数、Jaccard指数和H.Chen提出的共现算法等[11],选择合算法进行概念关联度分析。
(5)算法改良:分析概念间语义关系的提出质量,对算法进行改进。
3 总 结
利用词表和共现分析方法构建本体,已有相关的理论探讨和研究。本文认为,在生物医学领域,可以将这2种方法相结合,实现本体的半自动构建。这相比手工构建本体而言,节省了从量的时间跟人力。如何利用共现分析方法,提高语义关系获取的质量和效率,还有待在实践中进一步改进。
参考文献
[1]王梅.owl领域本体构建方法研究[J].图书情报工作,2004,12(22):12-33.
[2]余倩.近年来领域本体的应用新进展[J].图书馆建设,2008,(8):95-99.
[3]何琳,杜慧平,侯汉清.领域本体的半自动构建方法研究[J].图书馆理论与实践,2007,(5):26-27,38.
[4]Maja Hadzic,Elizabeth Chang.Ontology-based Support for Human Disease Study.Proceedings of the 38th Hawaii International Conference on System Sciences.2005,143a.
[5]http:∥www.nlm.nih.gov/pubs/factsheets/mesh.html[EB].2008-09-06.
[6]http:∥www.nlm.nih.gov/cgi/mesh/2008/MBzcgi[EB].2008-09-07.
[7]耿骞,耿崇.利用词语共现进行Ontology的概念获取[J].现代图书情报技术,2006,(2):43-49.
[8]Ying Ding IR and AI:Using Co-occurrence Theory to Generate Lightweight Ontologies 12th International Workshop on Database and Expert Systems Applications.0961.
[9]TakeshiMorita,Yoshihiro Shigeta,et al.DODDLE-OWL:On-the-fly Ontology Construction with Ontology Quality Management[EB].http:∥iswc2004.semanticweb.org/posters/PID-JURPMVUS-1090083983.pdf,2008-09-07.
[10]张学福.基于词共现的可视化概念空间研究[J].情报学报,2008,(27):2,205-211.
[11]王曰芬,宋爽,苗露.共现分析在知识服务中的应用研究[J].现代图书情报技术,2006,(4).29-34.
猜你喜欢
哲学分析(2023年4期)2023-12-21
装备制造技术(2021年5期)2021-08-14
哈哈画报(2021年10期)2021-02-28
中国音乐学(2020年4期)2020-12-25
山东冶金(2019年3期)2019-07-10
制造业自动化(2017年2期)2017-03-20
现代工业经济和信息化(2016年6期)2016-05-17
文学教育(2016年27期)2016-02-28
电子设计工程(2015年5期)2015-02-27
山西大同大学学报(社会科学版)(2014年5期)2014-01-23
