
OA期刊共享集成方案及其关键技术研究
2009-02-25 09:59邵晶周奇李威
大学图书馆学报 2009年1期
邵 晶 周 奇 李 威
摘要对来源不同、遵循不同协议的OA期刊的共享集成的关键技术问题进行研究,提出解决问题的思路和方案,以实现OA期刊的共享集成,解决OA期刊源的跟踪维护问题。
关键词OA期刊共享集成关键技术
1研究背景
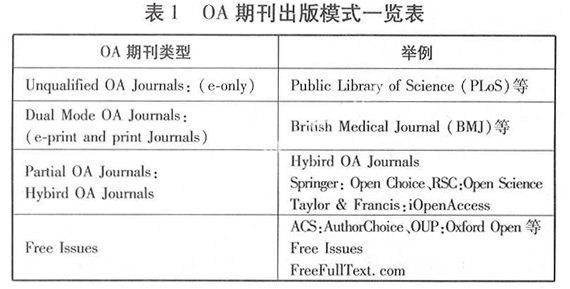
OA(Open Access,以下简称OA)期刊的出版模式已经多样化。大体上可以分为三大类:Unquali—fied OA Journals(e-only模式)、Dual Mode OA Jour—nals(both e-print and p-print模式)和Partial OA Jour-nals(Hybird OA Journal,Free issues)。其中,前两类期刊中所有文章都是OA的,而第三类期刊中只有部分文章是OA的。从OA期刊的延迟性分,又可以分为:NO Embargoed(无延迟)、Embargoed(有延迟)、Reverse embargo(出版后只OA前1-6个月,然后需要订阅)、Free issues(某一期或某几期是OA的)。OA期刊出版模式详见表1。
迄今为止,全球OA期刊究竟目前有多少种,尚未有准确数,据DOAJ(http://www.doaj.org/)不完全收录统计,截至2008年3月18日,该网站收录OA期刊(no embargo)种数达到了3275种,而西安交通大学图书馆搜集到的OA期刊已经突破1.2万种 。
由于这些OA期刊分散在全球不同的网站上,各自所在的数据库结构各异,遵循的协议标准不一致,使得OA期刊的跟踪收集与利用受到很大制约。为了能充分利用OA期刊,我们以OA期刊资源共享集成为研究目标,以期通过研究,探索,采用技术手段,跟踪、收割、整合全球著名的OA期刊的元数据,并提供OA期刊共享集成发布平台,为科研人员和教学人员提供一站式检索、浏览和全文链接服务。这项研究不仅对及时缓解我国外文资源由于经费不足所造成的资源获取困难的问题具有现实意义,而且对我国科研人员便捷地获取全球OA期刊,及时了解、掌握国际先进的科学技术水平和科技创新、快捷地引进先进的科学知识和国际学术科研成果都具有深远的现实意义。

2共享集成问题分析
西安交大于2006年初开始收集OA期刊,到目前为止,已经收集到No Embargoed(无延迟)、Embar-goed(有延迟)和PartialOA期刊1.2万种,这些期刊来自于:DOAJ、BMC、PMC、Freefnlltext、Freemedi—caliuomal、Open J-Gate、J—STAGE、Hi Wire Press、PLoS等不同的网站。尽管我们对这些期刊做了整合,提供了一个统一发布平台,但是由于这些网站的期刊品种每年都在不断增加,要跟踪这些网站期刊品种的变化,获取今后新发现的OA期刊网站的期刊品种及相关信息都存在很大的困难。因此需要设计一个OA期刊共享集成方案,从而真正解决不同OA期刊网站上的OA期刊相关信息的收割和跟踪问题。通过对现有OA期刊网站分析,将OA期刊共享集成时所遇到的问题归纳如下:

(1)不同的OA期刊源,其元数据属性不同,在实现各类OA期刊元数据共享集成时,必须要解决不同的OA期刊源的元数据的整合问题;
(2)目前并不是所有OA期刊提供者的数据格式都是采用OAI-PMH协议标准,所以在数据DP(Data Provider,数据提供者)和sP(service Provider,服务提供者)之间存在不同的数据收割协议:一种是基于OAI-PMH协议;另一种是HTTP协议;特别是后者,在网页中,期刊的各种信息是通过非结构化形式组织揭示,且分布在多级页面中,不同期刊网站,表现形式各异。
(3)收割OA期刊元数据是个动态过程,因此需要解决对OA期刊集成库的跟踪维护问题。
3共享集成方案设计及实现
3.1整体方案设计
OA期刊共享集成的设计方案主要包括数据采集和不同OA期刊源的共享集成两个方面。
数据采集主要是进一步对OA期刊信息进行挖掘,分析不同来源的OA期刊及其元数据(如:期刊刊名及其URL、ISSN、出版社、出版频率、OA的起始年、来源、embargo信息、TOC信息、摘要信息等)的发布形式,为收割后的OA期刊元数据共享集成做好基础工作;共享集成主要包括研究并设计对不同来源、不同类型OA期刊网站的元数据收割的技术方案,实现OA期刊元数据收割;设计不同来源OA期刊元数据的统一描述的技术方案;开发共享集成平台,提供一站式浏览与检索服务。OA期刊共享集成整体解决方案如图1所示。
3.2关键技术研究
OA期刊源的获取,主要是通过到网上收集,挑选出与本单位学科密切相关的OA期刊网站,作为今后要集成的对象和跟踪的对象。不同的OA期刊网站,期刊信息的发布所采用的技术手段、网页揭示情况各不相同。在上述讨论的问题中,统一不同期刊源的期刊元数据实现起来并不难,如果能解决对不同OA期刊源的元数据收割,那么跟踪、更新不同期刊源的数据也就不会成为难题。关键问题是需要解决遵循不同协议元数据的收割问题;即分别解决基于遵循OAI-PMH协议的OA期刊源的元数据发现与收割问题和基于HTrP协议的OA期刊网页的源代码解析成DOM(Document Object Model)树和元数据的提取问题。
3.2.1基于OAI-PMH协议的OA期刊源的元数据收割解决方案
OAI-PMH协议工作原理已经在很多文章中都已经阐述,这里不再赘述。对于基于OAI-PMH协议的OA期刊网站的元数据收割时的收割器使用的动词配置描述如下:
Identity:收割OA期刊相关信息,包括期刊的名称、ISSN号、URL、分类信息等;
ListSets:返回期刊的分类信息;
List Identifiers:返回满足一定条件的期刊记录;
ListRecords:收割目次级元数据。
基于OAI-PMH协议OA期刊元数据收割的流程图如图2所示,首先收割机器人发出收割指令,OAI服务器做出判断,然后有选择地返回XML格式元数据,最后对得到的元数据进行解析后存储到本地数据库。
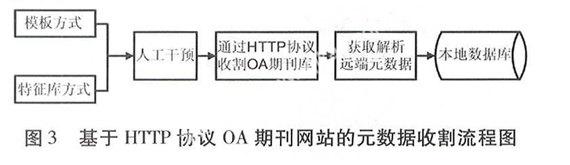
3.2.2基于HTTP协议的OA期刊的元数据收割解决方案
这种收割指的是网页结构化提取,网页结构化提取是将网页中的非结构化数据按照一定的要求提取成为结构化数据,如按需要数据收割TOC目次级别信息,甚至摘要级别信息,这样就需要元数据收割器能做到对某一个OA期刊源站点,做智能分析,抽期刊信息:刊名、ISSN、简介、期刊关键词、期刊摘要、创刊年度、出版社、学科、影响因子;卷
期信息:卷、期、出版年度;目次信息:文章标题、作者、作者联系方式、摘要、DOI、关键词、全文URL、文档类型等。
结构化信息提取有三种方式可以实现,一是模板方式,二是网页特征库方式,三是人工干预方式。
(1)模板方式:对特定网站事先做模板配置,收割器对配置中设定数据进行提取,这种方式主要适合于诸如open J-Gate(http://www.open/gate.org)和PubMed Central(PMC,http://www.pubmedcentral.nih.gov)这样网页界面单一、数据量大的OA期刊数据源。
(2)网页特征库方式:先将网页HTML源文件进行DOM(Document Object Model)树解析,然后从特征库中提取元数据特征信息,进行提取相应内容。这种方式适合于诸如BioMed Central(http://www.biomedcentral.com)以及J-Stage(hap://www.jstage.jst.go.jp)这类界面风格较为统一,数据层次结构较深的期刊数据源。
(3)人工干预方式:元数据收割器将用户制定网页删,源文件解析成DOM树,然后用户根据有用信息所在节点(Node),进行批量下载和批处理,最后得到有用信息。这种方式适合于诸如High Wire Press(http://highwire.stanford.edu)和Freefulltext(http://www.free—fulltext.com)这样下级页面多样,采用单一方法难以获取TOC级别元数据的期刊数据源。
目前提供HTTP服务的OA期刊网站多种多样。如果需要全面获取较为完整的信息,单独使用其中的一种方式均不能满足我们的需要,所以对结构化信息的提取,我们采用前两种程序化的方法并结合人工干预对网页进行抓取,以实现准确度与自动化的最佳平衡。基于HTTP协议OA期刊网站的元数据收割流程如图3所示:
3.2.3OA期刊元数据的集成
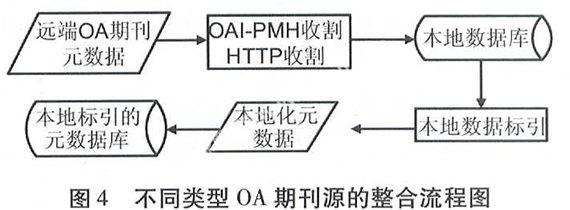
不同OA期刊网站,其元数据属性揭示的程度不同,在实现各类OA期刊元数据共享集成时,必须要解决不同OA期刊网站源元数据的统一描述问题。针对这个问题,采用DC标准,DC包含有15个基本著录项,对于期刊的元数据表达完全够用。对不同的期刊源的元数据(期刊网站)实行结构化分布式存储;同时对获取的远端元数据进行本地化标引后存入主数据库,来实现一站式整合,流程加下:
3.3OA期刊共享集成系统的模块化设计与实现
整个系统基于模块化设计,分为期刊元数据的采集、本地化和发布三部分。这三个相对独立的模块完成各自功能,所以一旦期刊数据源发生变更或者增加新的数据源,只需要升级相应的模块而不要整体改变。
3.3.1OA期刊元数据采集模块
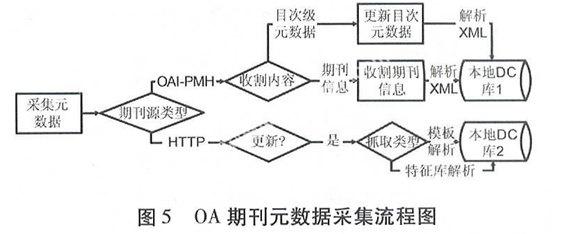
OA期刊元数据的收割主要依靠OAI-PMH协议收割和HTTP协议抓取共同完成。开始采集时,程序首先根据OA期刊源库中存储的类型信息决定以何种方式采集数据,同时更新期刊源库中对应的更新时间。OA期刊元数据采集流程如图5所示。
对于基于OAI-PMH协议的OA期刊源,通过OAI-PMH协议收割元数据,首先判断需要收割的元数据的类型,是期刊描述信息还是期刊目次级元数据;并采用不同的指令向服务器发出请求,对返回的XML文件进行解析,将得到的数据以记录方式存入数据库中。
对于基于HTTP协议的OA期刊源,通过HTTP协议抓取元数据,首先根据OA期刊源库中存储的类型信息决定该网站的抓取方式,是采用模板方式还是特征库方式抓取;在页面逐级抓取更新过程中对比上次期刊库中上次该页面的更新时间,如果内容有更新,则将新获取的原始数据以记录方式存入数据库,同时打上时间戳。
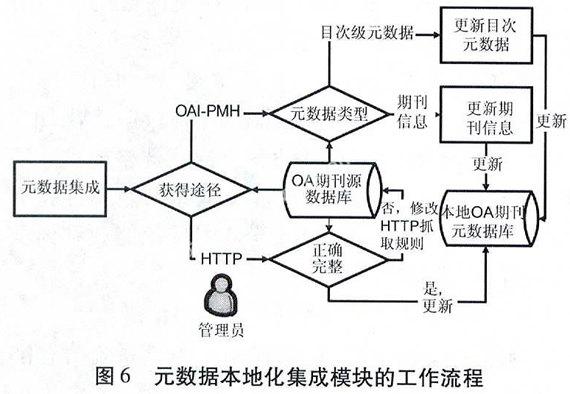
3.3.2元数据本地化集成化模块
针对基于OAI协议和基于HTTP协议采集来的元数据,OA期刊元数据的本地化集成在模块设计上略有区别:由OAI-PMH途径得到的元数据一般来说规范性较好,简单审核后可以直接根据字段对应关系进行自动标引,纳入本地库;而HTTP途径抓取的页面原始信息,首先需要管理员人工审核,确认无误后可根据字段对应关系进行自动标引,而后写入本地库。数据的本地化集成是整个系统的核心,元数据信息的准确性直接关系到不同OA期刊的揭示及用户利用OA期刊的效率。元数据本地化集成模块的工作流程如图6所示。
3.3.3数据发布与服务
将本地化后的OA期刊数据以网页的形式呈现给用户,在OA期刊共享平台上,用户可以按刊名、分类浏览,也可以按照刊名关键字或期刊的ISSN进行检索,快速查找所需要的期刊。在期刊列表中,可以看到不同来源的OA期刊信息,包括OA的起始年卷、出版社、是否是peer review、Embargoed/no em,bargo时间标识等信息。除了提供检索功能和浏览功能外,还能以作者、篇名、关键词、摘要作为检索点进行篇名目次级检索,直接链接到全文。
4结论
基于上述方案,我们实现了不同OA期刊源的共享集成。并在实际应用中得到了验证。解决了今后OA期刊的收割和发布问题及跟踪维护问题,同时为OA期刊与现有期刊导航系统的整合奠定了基础,也为今后整合OA仓储资源积累了实践经验。
猜你喜欢
宁波大学学报(理工版)(2022年4期)2022-07-08
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
读者(2021年5期)2021-02-05
华人经济(2017年6期)2017-08-18
军事文摘·科学少年(2017年4期)2017-06-20
电脑知识与技术(2016年28期)2016-12-21
读书(2016年5期)2016-05-21
中央社会主义学院学报(2016年2期)2016-05-04
全国新书目(2014年7期)2014-09-19
